व्यावसायिक ज्ञान आधार पर एआई प्रश्न-उत्तर उदाहरण
मान लीजिए आपके पास कुछ पाठ दस्तावेज (पीडीएफ, ब्लॉग, स्थानीय निजी डेटा, आदि) है और आप स्थानीय ज्ञान आधार पर आधारित एआई प्रश्न-उत्तर चैटबॉट बनाना चाहते हैं। इस फ़ंक्शनालिता को लांगचैन का उपयोग करके आसानी से लागू कर सकते हैं। नीचे एक कदम-से-कदम गाइड है कि लंगचैन का उपयोग करके इस प्रश्न-उत्तर कार्यक्षमता को कैसे प्राप्त किया जा सकता है।
- ध्यान दें: LLM (बड़े भाषा मॉडल) की प्रशिक्षण की उच्च लागत के कारण, बड़े भाषा मॉडल के ज्ञान आधार को स्वयं नहीं धारण किया जाएगा। एआई केवल उस सामग्री को जानती है जिस पर उसका प्रशिक्षण हुआ है और वह नयी सामग्री या उद्यम/व्यक्तिगत निजी डेटा के बारे में अज्ञात है, इसलिए स्थानीय ज्ञान आधार को बड़े भाषा मॉडल के साथ मेल करना आवश्यक है।
एआई प्रश्न-उत्तर प्रक्रिया
-
दस्तावेज लोडिंग: पहले, हमें हमारी स्थानीय पाठ सामग्री को लोड करने की आवश्यकता होती है, जो लांगचैन के लोडर घटक का उपयोग करके प्राप्त किया जा सकता है। -
दस्तावेजों को विभाजन करना: लांगचैन के टेक्स्ट स्प्लिटर का उपयोग करके दस्तावेजों को निर्दिष्ट आकार की पाठ से विभाजित किया जा सकता है। (ध्यान दें: पाठ विभाजन का उद्देश्य प्रश्नों के आधार पर संबंधित सामग्री फ्रेगमेंट्स की खोज को सुविधाजनक बनाना है। विभाजन का एक और कारण है कि बड़े भाषा मॉडल में एक अधिकतम टोकन सीमा होती है।) -
स्टोरेज: दस्तावेजों को विभाजन करने के बाद, एक एम्बेडिंग मॉडल का उपयोग करके दस्तावेज के सुरूप वेग वेक्टर की गणना करें और फिर उन्हें एक वेग डेटाबेस में संग्रहित करें। -
पुनर्प्राप्ति: प्रश्न के आधार पर, वेग डेटाबेस को पुनर्प्राप्त करने के लिए क्वेरी करें और समान दस्तावेज फ्रेगमेंट्स को पुनर्प्राप्त करें। -
तैयारी: लांगचैन के क्यूए चेन का उपयोग करके प्रश्न-उत्तर करने के लिए, प्रश्न के संबंधित दस्तावेज फ्रेगमेंट्स को प्रश्न के साथ जोड़ें और इन्हें आपके द्वारा डिज़ाइन किए गए एआई प्रॉम्प्ट्स में लांगचैन को पार करें। -
बातचीत(वैकल्पिक): क्यूए चेन में मेमोरी कॉम्पोनेंट जोड़कर, आप मल्टी-टर्न प्रश्न-उत्तर संवाद को सुविधाजनक बनाने के लिए एआई ऐतिहासिक संदेश मेमोरी क्षमता जोड़ सकते हैं।
तस्वीर लगातार की गई प्रक्रिया को निम्नलिखित आरेख के माध्यम से प्रस्तुत किया गया है: 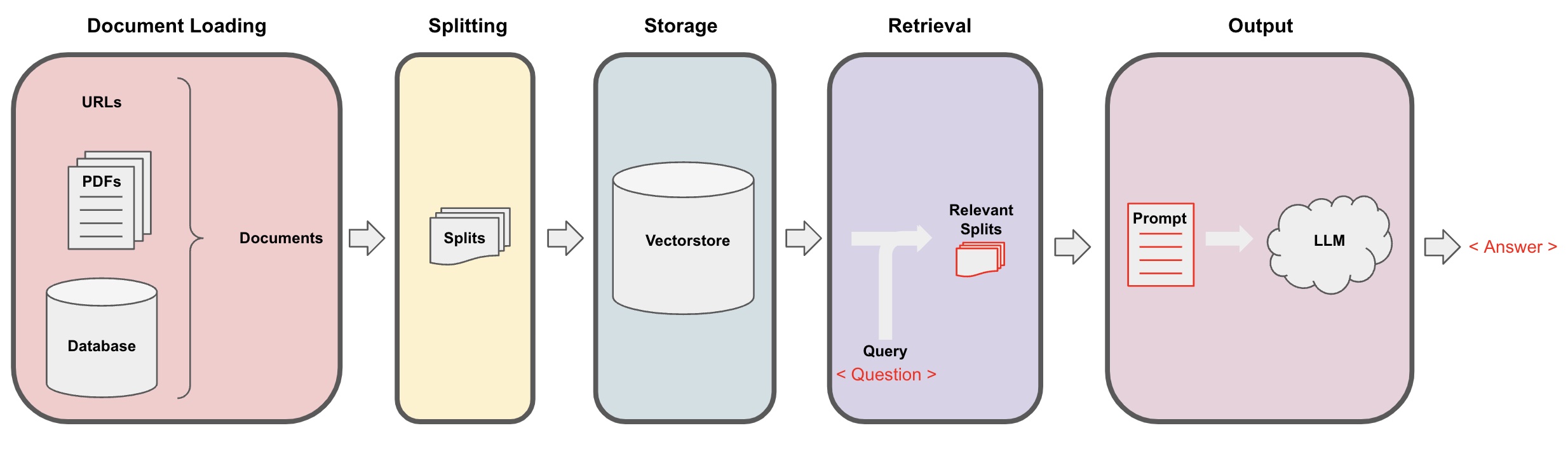
प्रारंभ करना
एक त्वरित आरम्भ करने के लिए, उपरोक्त प्रक्रिया को एकल ऑब्जेक्ट VectorstoreIndexCreator में आपवाहिक किया जा सकता है। मान लीजिए कि हम इस ब्लॉग पोस्ट पर आधारित एक क्यूए क्वेशन-आंसर कार्यक्रम बनाना चाहते हैं। इसे कुछ ही कोड की पंक्तियों के माध्यम से साधा किया जा सकता है:
- ध्यान दें: यह अध्याय अभी भी OpenAI के बड़े भाषा मॉडल का उपयोग करता है।
सबसे पहले, पर्यावरण चर को सेट करें और आवश्यक पैकेजों को स्थापित करें:
pip install openai chromadb
export OPENAI_API_KEY="..."
और फिर यह रन करें:
from langchain_community.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
index = VectorstoreIndexCreator().from_loaders([loader])
अब, प्रश्न पूछना शुरू करें:
index.query("What is task decomposition?")
Task decomposition is a technique to break down complex tasks into smaller, simpler steps. It can be done using LLM with simple prompts, task-specific instructions, or human input. Mindtrees (Yao et al.2023) is an example of task decomposition technique, which explores multiple reasoning possibilities at each step and generates multiple ideas at each step to create a tree structure.
प्रोग्राम चल रहा है, लेकिन इसे कैसे अंदर से कार्यान्वित किया गया है? चलिए, हम प्रक्रिया को कदम-ब-कदम विचार करें।
कदम 1. लोड करें (दस्तावेज डाटा लोड करना)
निर्दिष्ट डेटा को Documents ऑब्जेक्ट में लोड करने के लिए एक DocumentLoader का निर्दिष्ट करें। Documents ऑब्जेक्ट पाठ (पेज_सामग्री) और संबंधित मेटाडाटा का प्रतिनिधित्व करता है।
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
- ध्यान दें: लांगचैन विभिन्न लोडर प्रदान करता है ताकि विभिन्न प्रकार के डेटा को आसानी से लोड किया जा सके, जिसे पिछले अध्यायों में संदर्भ में लेना होगा।
कदम 2. विभाजन (दस्तावेजों को विभाजित करना)
क्योंकि बड़े मॉडल प्रॉम्प्ट्स की अधिकतम टोकन सीमा होती है, हम आई को बहुत ज्यादा दस्तावेज सामग्री को पार नहीं करा सकते। सामान्यत: क्यूट परिविष्टिए किए गए संबंधित दस्तावेज फ्रेगमेंट्स का परियाप्त होता है, इसलिए, हमें यहाँ दस्तावेज के स्लाइस प्रसंस्करण करने की जरूरत होती है।
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 0)
all_splits = text_splitter.split_documents(data)
स्टेप 3. स्टोर (वेक्टर स्टोरेज)
सवाल के आधार पर संबंधित दस्तावेज़ अंश की क्वेरी करने के लिए, हमें पहले से विभाजित दस्तावेज़ अंशों के लिए पाठ सुविधा वेक्टर की गणना करनी होगी, और फिर उन्हें वेक्टर डेटाबेस में स्टोर करना होगा।
यहाँ हम Langchain द्वारा प्रदत्त डिफ़ॉल्ट वेक्टर डेटाबेस "क्रोमा" का उपयोग करते हैं, और फिर ओपेनआई एम्बेडिंग मॉडल का उपयोग करते हैं।
- ध्यान दें: आप एम्बेडिंग मॉडल के रूप में अन्य ओपन सोर्स मॉडल भी चुन सकते हैं।
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
स्टेप 4. पुनर्प्राप्त (संबंधित दस्तावेज़ों की क्वेरी)
समानता खोज के माध्यम से सवाल के संबंधित दस्तावेज़ अंशों को पुनर्प्राप्त करें।
- ध्यान दें: इस स्टेप का उद्देश्य वेक्टर डेटाबेस की समानता खोज की कार्यक्षमता को प्रदर्शित करना है। इस स्टेप की कार्यक्षमता, लैंगचेन द्वारा 5वें स्टेप में एन्कैप्सुलेट किए गए क्यू एंड ए चेन में स्वत: शामिल है।
question = "कार्य विभाजन के विधान क्या हैं?"
docs = vectorstore.similarity_search(question)
len(docs)
4
स्टेप 5. उत्पन्न (AI का उपयोग सवालों का जवाब देने के लिए)
लेनशैन की फिल्टर लाइब्रेरी एलएलएम/चैट मॉडल (जैसे gpt-3.5-turbo) और रिट्रीवलक्यूए चेन का उपयोग करके पुनर्प्राप्त दस्तावेज़ को एक एकल उत्तर में संक्षेपित करना।
- सुझाव:
रिट्रीवलक्यूएएक चेन है जो लैंगचेन द्वारा एन्कैप्सुलेट किया गया है, जिसमें स्थानिक ज्ञान आधारित सवालों के जवाब देने की क्षमता होती है।
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectorstore.as_retriever())
qa_chain({"query": question})
{
'query': 'कार्य विभाजन के विधान क्या हैं?',
'result': 'कार्य विभाजन के विधान निम्नलिखित होते हैं:\n\n1. सरल प्रॉम्प्ट्स: इस विधि में, कार्य को छोटे उप-लक्ष्यों में विभाजित करने के लिए सरल प्रॉम्प्ट्स या प्रश्नों का उपयोग किया जाता है। उदाहरण के लिए, एजेंट को "XYZ के लिए कदम" के साथ प्रॉम्प्ट किया जा सकता है और यहां पर XYZ प्राप्त करने के लिए उप-लक्ष्यों की सूची बनाने के लिए कहा जाता है।\n\n2. कार्य-विशिष्ट निर्देश: इस विधि में, कार्य-विशिष्ट निर्देश एजेंट की विभाजन प्रक्रिया के लिए प्रादान किए जाते हैं। उदाहरण के लिए, यदि किसी कार्य को नॉवेल लिखना है, तो एजेंट को "कथा की रूपरेखा ड्राफ्ट करें" के रूप में आदेश दिया जा सकता है जैसा कि एक उप-लक्ष्य।\n\n3. मानव प्रविष्टि: इस विधि में, कार्य विभाजन प्रक्रिया में मानव प्रविष्टि को शामिल किया जाता है। मानव एजेंट एजेंट को संयंत्र के संयंत्र को किसी अधिक व्यवस्थित उप-लक्ष्यों में बाँटने के लिए मार्गदर्शन, प्रतिक्रिया और सुझाव प्रदान कर सकते हैं।\n\nये विधियाँ बड़े कार्यों को, उन्हें छोटे, अधिक प्रबंधन योग्य भागों में विभाजित करके प्रभावी तरीके से निपटने का लक्ष्य रखती हैं।'
}
ध्यान दें कि आप "लेएलएम" या "चैटमॉडल" को "रिट्रीवलक्यूए" चेन में पास कर सकते हैं।
सूचना: यह ट्यूटोरियल लैंगचेन में स्वत: एन्कैप्सुलेट किए गए
रिट्रीवलक्यूएचेन का उपयोग ज्ञान आधारित सवाल-जवाब करने के लिए करता है। वास्तविकता में, नए संस्करण के लिए लैंगचेन एलसीईएल (LCEL) अभिव्यक्तियों पर उपयुक्त अनुसरण के लिए समान सवाल-जवाब चेन कस्टमाइज़ करना बहुत आसान है। कृपया एलसीईएल पर संबंधित अनुभाग को देखें।
कस्टम प्रारूप टेम्पलेट
पिछले रिट्रीवलक्यूए चेन का उपयोग करते समय, हमने किसी प्रारूप शब्द को सेट नहीं किया और लैंगचेन से निर्मित प्रारूप शब्द टेम्पलेट का उपयोग किया। अब, आइए प्रारूप शब्द टेम्पलेट को साधारित करें।
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
template ="""नीचे दिए गए संदर्भ के आधार पर सवाल का जवाब दीजिए।
अगर आप जवाब नहीं जानते, तो सिर्फ "मुझे नहीं पता" कहें,
और एक जवाब बनाने की कोशिश न करें।
जवाब 3 वाक्यों के भीतर होना चाहिए, और इसे संक्षेप में रखें।
हमेशा उत्तर के अंत में "आपके सवाल के लिए धन्यवाद!" कहें।
{context}
सवाल: {question}
जवाब: """
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)
result = qa_chain({"query": question})
result["result"]
AI प्रश्न और उत्तर स्रोत के साथ
उपयोग करें RetrievalQAWithSourcesChain भर्ती के स्थान पर RetrievalQA से, ताकि AI के जवाब देने का आधार कौन से दस्तावेज पर हो।
from langchain.chains import RetrievalQAWithSourcesChain
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(llm, retriever=vectorstore.as_retriever())
result = qa_chain({"question": question})
result
ब्लॉग लिंक्स पर आधारित सवालों के जवाब देने के पिछले उदाहरण पर आधारित, वापस आये परिणाम निम्नलिखित हैं, जो हमें यह दिखाते हैं कि AI ने विशिष्ट ब्लॉग URL पर आधारित सवाल का जवाब दिया है:
{
'question': 'कार्य विभाजन के लिए विधियाँ क्या हैं?',
'answer': 'कार्य विभाजन के लिए विधियाँ में शामिल हैं (1) LLM और सरल प्रॉम्प्ट का उपयोग करना, (2) कार्य-विशिष्ट निर्देशों का उपयोग करना, और (3) इसके अंदर मानव संवेदनशीलता को शामिल करना।\n',
'sources': 'https://lilianweng.github.io/posts/2023-06-23-agent/'
}