वेक्टर स्टोर
- समष्टिकरण पर जाएं और लैंगचेन द्वारा आधिकारिक रूप से समर्थित तृतीय-पक्ष वेक्टर स्टोर इंजन के बारे में जानें।
अनावरणित डेटा का रखरखाव और खोज करने के लिए सबसे सामान्य समाधान है कि डेटा के feature वेक्टरों की गणना की जाए और फिर पूछते समय वेक्टर समानता के आधार पर समान वेक्टरों की खोज की जाए। एक वेक्टर डेटाबेस वेक्टर की रखरखाव और पूछताछ के लिए डेटा भंडारण इंजन प्रदान करने के लिए जिम्मेदार होती है।
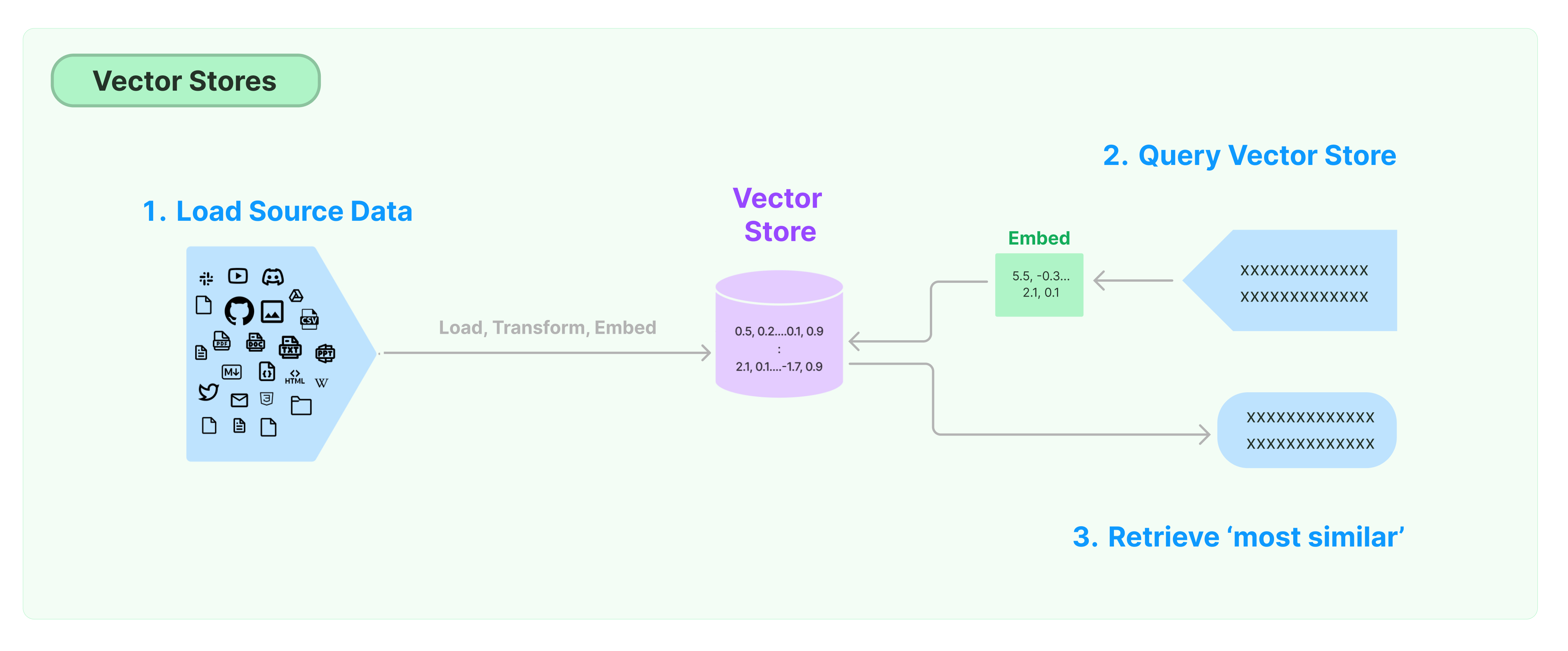
लैंगचेन वेक्टर स्टोर के साथ शुरुआत
इस मार्गदर्शिका में वेक्टर स्टोर के संबंधित मौलिक कार्य का परिचय है। वेक्टर स्टोर के साथ काम करने वाला मुख्य घटक अंकित मॉडल है (जिम्मेदार फ़ीचर वेक्टर की गणना के लिए)। इसलिए, इस अध्याय की अध्ययन करने से पहले टेक्स्ट एन्क्रिप्शन मॉडल के साथ टेक्स्ट वेक्टर की गणना कैसे करें, इसे सिखना सिफारिश किया जाता है।
कई उत्कृष्ट वेक्टर स्टोर इंजन्स हैं। नीचे, हम लैंगचेन फ्रेमवर्क में 3 मुफ्त और ओपन-सोर्स वेक्टर स्टोर इंजन के उपयोग का परिचय प्रस्तुत करते हैं।
क्रोमा
इस अध्याय में, क्रोमा वेक्टर डेटाबेस का उपयोग किया गया है, जो स्थानीय रूप से एक पाइथन लाइब्रेरी के रूप में चलता है।
pip install chromadb
यहां, हम ओपनएआई एंबेडिंग मॉडल का उपयोग करके वेक्टर की गणना करने के लिए करें, इसलिए हमें ओपनएआई एपीआई कुंजी प्राप्त करनी होगी।
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
फेस
इस अध्याय में, फेस वेक्टर डेटाबेस का उपयोग करता है, जो फेसबुक एआई सिमिलैरिटी सर्च (फेस) पुस्तकालय का उपयोग करता है।
pip install faiss-cpu
यहां, हम ओपनएआई एंबेडिंग मॉडल का उपयोग करके वेक्टर की गणना करने के लिए करें, इसलिए हमें ओपनएआई एपीआई कुंजी प्राप्त करनी होगी।
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = FAISS.from_documents(documents, OpenAIEmbeddings())
लांस
इस अध्याय में, हम बताएंगे कि लैंगचेन फ्रेमवर्क कैसे लांसडीबी वेक्टर डेटाबेस का उपयोग करता है।
pip install lancedb
यहां, हम ओपनएआई के एंबेडिंग मॉडल का उपयोग करने के लिए वेक्टर की गणना करनी है, इसलिए हमें ओपनएआई एपीआई कुंजी प्राप्त करनी होगी।
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import LanceDB
import lancedb
db = lancedb.connect("/tmp/lancedb")
table = db.create_table(
"my_table",
data=[
{
"vector": embeddings.embed_query("Hello World"),
"text": "Hello World",
"id": "1",
}
],
mode="overwrite",
)
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = LanceDB.from_documents(documents, OpenAIEmbeddings(), connection=table)
समानता खोज
query = "राष्ट्रपति ने केतन्जी ब्राउन जैक्सन को क्या कहा?"
docs = db.similarity_search(query)
print(docs[0].page_content)
वेक्टर समानता खोज
similarity_search_by_vector का उपयोग दिए गए वेक्टर पर आधारित समानता खोज के लिए करें। इस फ़ंक्शन को एक स्ट्रिंग की बजाय एक एम्बेडिंग वेक्टर के रूप में पैरामीटर के रूप में लेता है।
embedding_vector = OpenAIEmbeddings().embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
print(docs[0].page_content)
असमवादी कार्य
वेक्टर संग्रह अक्सर एक स्वतंत्र सेवा के रूप में चलता है और कुछ आईओ कार्यों की आवश्यकता होती है। इसलिए, वेक्टर डेटाबेस इंटरफ़ेस के लिए असमवादी कॉल का उपयोग करें। यह प्रदर्शन में समय बर्बाद करने की आवश्यकता नहीं होती है क्योंकि आपको बाहरी सेवाओं से प्रतिक्रियाओं का इंतजार करने की आवश्यकता नहीं होती है।
भाषाश्रृंखला वेक्टर संग्रह के लिए असमवादी कार्यों का समर्थन करती है। सभी विधियाँ a उपसर्ग के साथ अपने असमवादी कार्यों का उपयोग करके बुला सकते हैं, जो async को दर्शाता है।
Qdrant एक वेक्टर संग्रह है जो सभी असमवादी कार्यों का समर्थन करता है। नीचे एक Qdrant का उपयोग करके उदाहरण है।
pip install qdrant-client
from langchain_community.vectorstores import Qdrant
असमवादी वेक्टर संग्रह निर्माण
db = await Qdrant.afrom_documents(documents, embeddings, "http://localhost:6333")
समानता खोज
query = "राष्ट्रपति ने केतन्जी ब्राउन जैक्सन को क्या कहा?"
docs = await db.asimilarity_search(query)
print(docs[0].page_content)
वेक्टर-आधारित खोज
embedding_vector = embeddings.embed_query(query)
docs = await db.asimilarity_search_by_vector(embedding_vector)
अधिकतम मार्जिनल प्रारंभ (MMR) खोज
अधिकतम मार्जिनल प्रारंभ अनुरूपता को अनुकूलित करता है जो कि प्रश्न और चयनित दस्तावेज़ों के बीच विविधता को अनुकूलता और समानता अनुकूलता को अनुकूलता करती है। यह भी असमवादी API का समर्थन करता है।
query = "राष्ट्रपति ने केतन्जी ब्राउन जैक्सन को क्या कहा?"
found_docs = await qdrant.amax_marginal_relevance_search(query, k=2, fetch_k=10)
for i, doc in enumerate(found_docs):
print(f"{i + 1}.", doc.page_content, "\n")