ตัวอย่างคำถามและคำตอบของ AI โดยใช้ฐานความรู้ท้องถิ่น
สมมติว่าคุณมีเอกสารข้อความบางส่วน (PDF, บล็อก, ข้อมูลส่วนบุคคลท้องถิ่น ฯลฯ) และต้องการสร้างบอทการสนทนา AI Q&A โดยใช้ฐานความรู้ท้องถิ่น ซึ่งสามารถทำได้ง่ายๆ ด้วย LangChain ด้านล่างเป็นขั้นตอนการทำ Q&A ของการทำงานนี้โดยใช้ LangChain
- หมายเหตุ: เนื่องจากมีค่าใช้จ่ายสูงในการฝึก LLM (โมเดลภาษาขนาดใหญ่) ฐานความรู้ของโมเดลภาษาขนาดใหญ่เองจึงไม่ได้ถูกอัปเดตอย่างสม่ำเสมอ แอบ็อทเท่านั้นทราบเนื้อหาที่ฝึกและไม่ทราบเนื้อหาใหม่หรือข้อมูลส่วนบุคคล/องค์กร ดังนั้นจึงจำเป็นต้องผสมฐานความรู้ท้องถิ่นกับโมเดลภาษาขนาดใหญ่
กระบวนการทำ AI Q&A
-
การโหลดเอกสาร: ต้องโหลดข้อมูลข้อความท้องถิ่นของเราก่อน ซึ่งสามารถทำได้โดยใช้คอมโพเนนต์โหลดของ LangChain -
การแบ่งเอกสาร: ใช้ตัวแบ่งข้อความของ LangChain เพื่อแบ่งข้อความเอกสารเป็นส่วนๆ ขนาดที่ระบุ (หมายเหตุ: วัตถุประสงค์ของการแบ่งข้อความคือเพื่อการค้นหาเนื้อหาที่เกี่ยวข้องตามคำถาม สาเหตุอีกอย่างคือในโมเดลภาษาขนาดใหญ่มีขีดจำกัดของโทเคน) -
การจัดเก็บ: หลังจากแบ่งเอกสารเสร็จเรียบร้อยแล้ว คำนวณเวกเตอร์ลักษณะของเอกสารโดยใช้โมเดลการฝังอิมเบ็ดและจัดเก็บไว้ในฐานข้อมูลเวกเตอร์ -
การเรียกคืน: โดยขึ้นอยู่กับคำถาม สอบถามฐานข้อมูลเวกเตอร์เพื่อเรียกคืนส่วนของเอกสารที่คล้ายกัน -
การสร้าง: ใช้เชน QA ของ LangChain เพื่อทำ Q&A ต่อกันเอกสารที่เกี่ยวข้องกับคำถามพร้อมกับคำถามเองเข้าด้วยกันเป็นข้อความให้ AI ตอบคำถาม -
การสนทนา(ตัวเลือก): โดยการเพิ่มองค์ประกอบอำนาจของเชนและQA คุณสามารถเพิ่มฟังก์ชันแหล่งความทรงจำของ AI สำหรับการสนทนาหลายรอบ
กระบวนการ AI Q&A แสดงไดอะแกรมด้านล่าง:
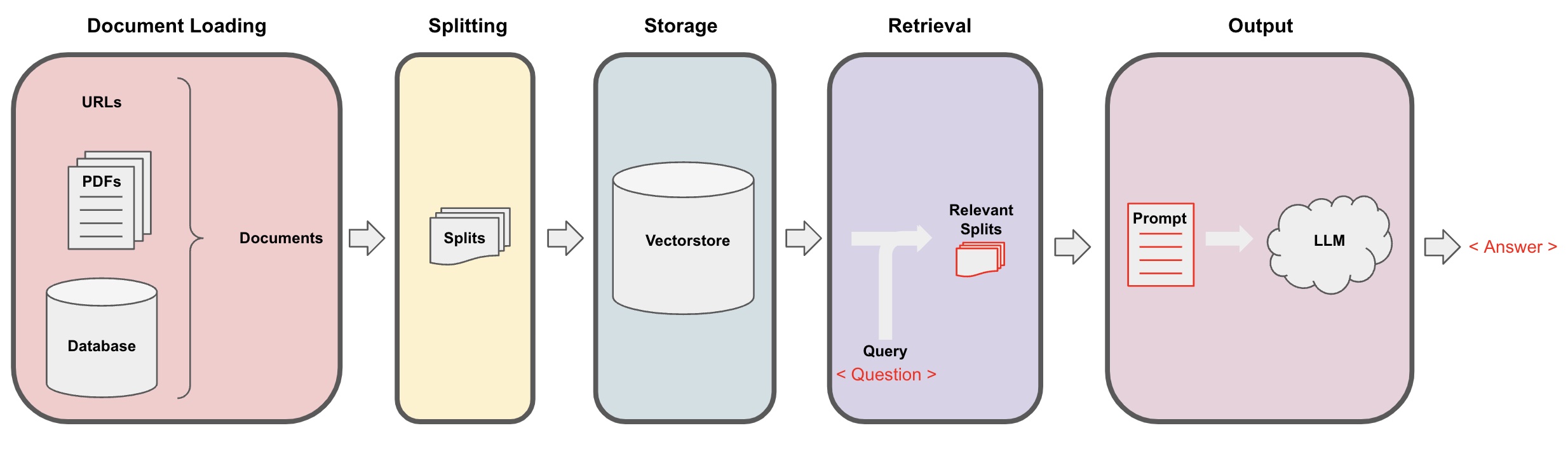
เริ่มต้น
เพื่อการเริ่มต้นง่ายๆ กระบวยการด้านบนสามารถห่อหุ้มไว้ในออบเจ็คเดียวกัน VectorstoreIndexCreator. สมมติว่าเราต้อกาสร้างโปรแกรม Q&A ที่ใช้ฐานความรู้นี้ บล็อกโพสต์ สามารถทำได้ด้วยเพียงไม่กี่บรรทัดโค้ด:
- หมายเหตุ: บทต่อไปนี้ยังใช้ LLM ของ OpenAI
ก่อนอื่นกำหนดตัวแปรสภาพแวดล้อมและติดตั้งแพ็คเกจที่ต้องการ:
pip install openai chromadb
export OPENAI_API_KEY="..."
จากนั้นเรียกใช้:
from langchain_community.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
index = VectorstoreIndexCreator().from_loaders([loader])
ตอกรถามได้เลย:
index.query("What is task decomposition?")
การถอดแยกงานเป็นเทคนิคที่ใช้เพื่อแยกรายงานงานที่ซับซ้อนเป็นบรรทัดเล็กๆ จากงานย่อยที่ง่ายขึ้น สามารถทำได้โดยใช้ LLM กับวิธีการกำหนดโปรตัสธรรมตามงาน คำแนะนำพิเศษเกี่ยวกับงานหรือมีป้อนเข้าจากมนุษย์ ตัวอย่างของเทคนิคการถอดแยกงานคือ Mindtrees (Yao et al.2023) ซึ่งเป็นตัวอย่างของเทคนิคการถอดแยกงานที่สำเร็จสรรพ์ ที่สำรวจความเป็นไปได้หลายอย่างในแต่ละขั้นตอนหลายๆ อย่าง และสร้างการคิดหลายๆ แนวที่แต่ละขั้นเพื่อสร้างโครงสร้างต้นไม้
โปรแกรมกำลังทำงาน แต่ภาพรวมการทำงานอยู่ที่ไหน? เรามาชี้แจงกระบวนการขั้นต่อโดยชั้น:
ขั้นตอนที่ 1. โหลด (การโหลดข้อมูลเอกสาร)
ระบุ โหลดข้อมูลเอกสาร เพื่อโหลดข้อมูลที่ระบุเข้าสู่ วัตถุข้อมูลถาย โดยที่ วัตถุข้อมูลถาย แทนข้อความ (page_content) และเมตาดาด้อื่นๆ ที่เกี่ยวข้อง
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
ข้อมูล = loader.load()
- หมายเหตุ: Langchain มีโหลดเดอร์หลายรูปแบบสำหรับสะดวกในการโหลดข้อมูลประเภทต่างๆ ซึ่งสามารถอ้างอิงได้ในบทก่อนหน้า
ขั้นตอนที่ 2. แบ่ง (การแบ่งข้อความ)
เนื่องจากโปรตัสโมเดลมีขีดจำกัดทั้งสิ่งที่เรียกในโทเคน แต่ไม่สามารถส่งเนื้อหาข้อความมากเกินไปให้กับ AI แต่ตำก็พอดีที่จะส่งเนื้อหาข้อความที่เกี่ยวข้อง ดังนั้นเราจึงต้องประมวลผลไปที่นี่
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 0)
ทุกส่วน = text_splitter.split_documents(ข้อมูล)
ขั้นตอนที่ 3. จัดเก็บ (การจัดเก็บเวกเตอร์)
เพื่อสามารถค้นพบข้อมูลส่วนหนึ่งที่เกี่ยวข้องกับคำถาม จะต้องคำนวณเวกเตอร์คุณลักษณะของข้อความสำหรับข้อมูลที่แยกไว้ก่อนหน้านี้โดยใช้ embedding model แล้วจึงจัดเก็บไว้ในฐานข้อมูลของเวกเตอร์
ที่นี่เราใช้ฐานข้อมูลเวกเตอร์เริ่มต้น "chroma" ที่ให้มาจาก Langchain และจากนั้นใช้ embedding model จาก openai
- หมายเหตุ: คุณยังสามารถเลือกใช้โมเดล open source อื่น ๆ เพื่อใช้เป็นตัวแทนของ embedding model ได้ด้วย
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
ขั้นตอนที่ 4. การเรียกคืน (ค้นหาเอกสารที่เกี่ยวข้อง)
ค้นหาข้อมูลส่วนหน้าที่เกี่ยวข้องกับคำถามผ่านการค้นหาความคล้ายคลึง
- หมายเหตุ: วัตถุประสงค์ของขั้นตอนนี้คือเพื่อแสดงฟังก์ชันการค้นหาความคล้ายคลึงของฐานข้อมูลเวกเตอร์ ซึ่งฟังก์ชันของขั้นตอนนี้ถูกรวมไว้ใน Q&A chain ที่ถูกซ้อนทับโดย Langchain ในขั้นตอนที่ 5
question = "วิธีการแบ่งงานย่อยมีอะไรบ้าง?"
docs = vectorstore.similarity_search(question)
len(docs)
4
ขั้นตอนที่ 5. สร้าง (การใช้ AI ในการตอบคำถาม)
ใช้โมเดล LLM/Chat (ตัวอย่างเช่น gpt-3.5-turbo) และ RetrievalQA chain เพื่อรวมเอกสารที่ค้นหาได้เป็นคำตอบเดียว
- เทคนิค:
RetrievalQAเป็น chain ที่ถูกซ้อนทับโดย LangChain ที่สามารถดำเนินการตอบคำถามที่อ้างอิงจากฐานข้อมูลท้องถิ่น
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectorstore.as_retriever())
qa_chain({"query": question})
{
'query': 'วิธีการแบ่งงานย่อยมีอะไรบ้าง?',
'result': 'วิธีการแบ่งงานย่อย ได้แก่:\n\n1. Simple Prompts: วิธีนี้ใช้คำถามหรือคำถามที่เรียบง่ายเพื่อชี้นำตัวเองในการแบ่งงานเป็นเป้าหมายย่อย ตัวอย่างเช่น ตัวเองสามารถถาม "ขั้นตอนสำหรับ XYZ" และถามให้แบกเส้นเป้าหมายย่อยเพื่อทำ XYZ\n\n2. คำแนะนำเฉพาะงาน: ในวิธีนี้ จะใช้คำแนะนำที่เฉพาะเจาะจงสำหรับงานเพื่อชี้นำกระบวนการแบ่งเป้าหมายสำหรับตัวเอง ตัวอย่างเช่น หากงานเป็นการเขียนนวนิยาย ตัวเองสามารถได้รับคำแนะนำให้ "ร่างโครงเรื่อง" เป็นเป้าหมายย่อย\n\n3. การรับข้อมูลจากมนุษย์: วิธีนี้เกี่ยวกับการนำข้อมูลจากมนุษย์มาช่วยในกระบวนการแบ่งเป้าหมาย มนุษย์สามารถให้คำแนะนำ คำตอบ และข้อเสนอช่วยการตัวเองในการแบ่งงานที่ซับซ้อนเป็นเป้าหมายย่อย\n\nวิธีเหล่านี้มุ่งเน้นการจัดการงานที่ซับซ้อนอย่างมีประสิทธิภาพโดยการแบ่งงานเป็นส่วนที่น้อยลง ที่จะสามารถจัดการได้ง่ายขึ้น'
}
โปรดทราบว่าคุณสามารถส่ง "LLM" หรือ "ChatModel" ไปยัง "RetrievalQA" chain
เทคนิค: ที่แนะนำในบทนี้ใช้รูปแบบตัวอย่างของข้อสั่งการที่กำหนดเองไม่ได้ตั้งคำสั่งคำถามไว้เองและใช้ตัวแม่ของคำสั่งคำถามที่ถูกซ้อนทับในภาษาละติน กรุณาอ้างอิงการปรับแก้รูปแบบข้อสั่งการคำถามในส่วนที่เกี่ยวข้องใน LCEL ได้ง่ายๆ
การปรับแบบแม่ของคำสั่งคำถามที่กำหนดเอง
เมื่อใช้ RetrievalQA chain ก่อนหน้านี้ เราไม่ได้ตั้งคำสั่งคำถามเองและใช้ตัวแม่ของคำสั่งคำถามที่ถูกซ้อนทับที่มาจาก langchain ตอนนี้ ให้ปรับแบบแม่ของคำสั่งคำถามเอง
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
template ="""ตอบคำถามโดยอิงจากประเด็นด้านล่างนี้
ถ้าคุณไม่ทราบคำตอบ ตอบ "ฉันไม่ทราบ" และอย่าพยายามปลอมเป็นคำตอบ
คำตอบควรอยู่ภายใน 3 ประโยคและเป็นคำตอบที่กระชับ
บอกว่า "ขอบคุณสำหรับคำถาม!" ท้ายคำตอบทุกครั้ง
{context}
คำถาม: {question}
คำตอบ: """
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)
result = qa_chain({"query": question})
result["result"]
ข้อมูลอ้างอิงสำหรับการตอบคำถามเกี่ยวกับ AI
ใช้ RetrievalQAWithSourcesChain แทน RetrievalQA เพื่อที่จะได้รับคำตอบจาก AI โดยขึ้นอยู่กับเอกสารที่ไหน
from langchain.chains import RetrievalQAWithSourcesChain
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(llm, retriever=vectorstore.as_retriever())
result = qa_chain({"question": question})
result
พัฒนาจากตัวอย่างก่อนหน้าของการตอบคำถามโดยขึ้นอยู่กับลิงก์บล็อก ผลลัพธ์ที่ได้คือดังนี้ ทำให้เราสามารถเห็นได้ว่า AI ตอบคำถามขึ้นอยู่กับ URL บล็อกที่เฉพาะเจาะจง:
{
'question': 'วิธีการแยกงานมีอะไรบ้าง?',
'answer': 'วิธีการแยกงานมี (1) การใช้ LLM และข้อความโปรดง่าย, (2) การใช้คำสั่งที่เฉพาะเจาะจงเกี่ยวกับงาน, และ (3) การให้คำแนะนำจากมนุษย์.\n',
'sources': 'https://lilianweng.github.io/posts/2023-06-23-agent/'
}