Exemplo de AI Q&A com base em um banco de conhecimento local
Suponha que você tenha alguns documentos de texto (PDFs, blogs, dados privados locais, etc.) e queira criar um chatbot de IA de pergunta e resposta com base em um banco de conhecimento local. É fácil implementar essa funcionalidade usando o LangChain. Abaixo está um guia passo a passo sobre como alcançar essa funcionalidade de Q&A usando o LangChain.
- Observação: Devido ao alto custo de treinamento do LLM (grande modelo de linguagem), o próprio banco de conhecimento do grande modelo de linguagem não será atualizado com frequência. A IA só conhece o conteúdo em que foi treinada e não tem conhecimento de novos conteúdos ou dados privados de empresas/pessoais, então é necessário combinar o banco de conhecimento local com o grande modelo de linguagem.
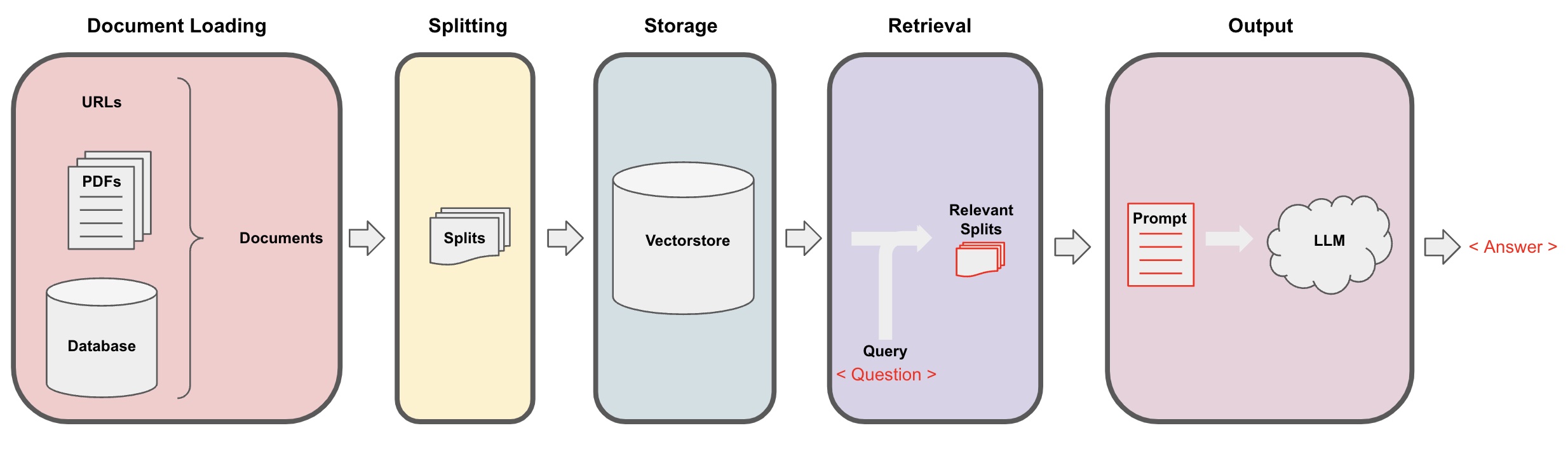
Processo de Q&A da AI
-
Carregamento de Documentos: Primeiro, precisamos carregar nossos dados de texto locais, o que pode ser alcançado usando o componente de carregamento do LangChain. -
Divisão de Documentos: Usar o separador de texto do LangChain para segmentar os documentos em fragmentos de texto de tamanho especificado. (Observação: O objetivo da segmentação de texto é facilitar a busca de fragmentos de conteúdo relevantes com base nas perguntas. Outro motivo para a segmentação é que o grande modelo de linguagem tem um limite máximo de tokens.) -
Armazenamento: Após segmentar os documentos, calcular os vetores de características do documento usando um modelo de incorporação e então armazená-los em um banco de dados de vetores. -
Recuperação: Com base na pergunta, consultar o banco de dados de vetores para recuperar fragmentos de documentos semelhantes. -
Geração: Usar a cadeia de QA do LangChain para realizar perguntas e respostas, concatenar os fragmentos de documento relacionados à pergunta com a pergunta em si em prompts de IA projetados por você e passá-los para o LLM para responder à pergunta. -
Conversa(opcional): Adicionando o componente de Memória à cadeia de QA, você pode adicionar funcionalidade de memória de mensagens históricas de IA para facilitar diálogos de perguntas e respostas multi-turnos.
O processo de Q&A da AI é ilustrado no diagrama a seguir:
Primeiros Passos
Para começar rapidamente, o processo acima pode ser encapsulado em um único objeto VectorstoreIndexCreator. Suponha que desejamos criar um programa de perguntas e respostas Q&A com base neste post do blog. Isso pode ser alcançado com apenas algumas linhas de código:
- Observação: Este capítulo ainda utiliza o grande modelo de linguagem da OpenAI.
Primeiro, defina as variáveis de ambiente e instale os pacotes necessários:
pip install openai chromadb
export OPENAI_API_KEY="..."
Em seguida, execute:
from langchain_community.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
índice = VectorstoreIndexCreator().from_loaders([loader])
Agora, comece a fazer perguntas:
índice.query("O que é decomposição de tarefas?")
A decomposição de tarefas é uma técnica para dividir tarefas complexas em etapas menores e mais simples. Pode ser feita usando o LLM com prompts simples, instruções específicas da tarefa ou entrada humana. Mindtrees (Yao et al.2023) é um exemplo de técnica de decomposição de tarefas, que explora múltiplas possibilidades de raciocínio em cada etapa e gera múltiplas ideias em cada etapa para criar uma estrutura em árvore.
O programa está em execução, mas como ele é implementado sob o capô? Vamos quebrar o processo passo a passo.
Passo 1. Carregar (Carregando Dados do Documento)
Especifique um DocumentLoader para carregar os dados especificados em um objeto Document. O objeto Document representa um pedaço de texto (page_content) e metadados relacionados.
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
dados = loader.load()
- Observação: O Langchain fornece vários carregadores para carregar convenientemente diferentes tipos de dados, que podem ser consultados nos capítulos anteriores.
Passo 2. Dividir (Divisão de Documentos)
Como os prompts do grande modelo têm um limite máximo de tokens, não podemos passar muito conteúdo do documento para a IA. Geralmente é suficiente passar fragmentos relevantes do documento, então precisamos processar as fatias do documento aqui.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 0)
todos_splits = text_splitter.split_documents(dados)
Passo 3. Armazenar (Armazenamento de Vetores)
Para consultar fragmentos de documento relevantes com base em uma pergunta, precisamos calcular os vetores de características de texto para os fragmentos de documento previamente divididos utilizando um modelo de incorporação e depois armazená-los em um banco de dados de vetores.
Aqui, usamos o banco de dados de vetor padrão "chroma" fornecido pela Langchain e, em seguida, utilizamos o modelo de incorporação openai.
- Nota: Você também pode escolher outros modelos de código aberto como substituto para o modelo de incorporação.
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
Passo 4. Recuperar (Consultar Documentos Relevantes)
Recuperar fragmentos de documento relacionados à pergunta por meio da busca de similaridade.
- Nota: O objetivo deste passo é demonstrar a função de busca de similaridade do banco de dados de vetores. A funcionalidade deste passo está automaticamente incluída na cadeia de pergunta e resposta encapsulada pela Langchain no 5º passo.
questão = "Quais são os métodos de decomposição de tarefas?"
docs = vectorstore.similarity_search(questão)
len(docs)
4
Passo 5. Gerar (Usando IA para responder perguntas)
Use o modelo LLM/Chat (por exemplo, gpt-3.5-turbo) e a cadeia RetrievalQA para condensar o documento recuperado em uma única resposta.
- Dica:
RetrievalQAé uma cadeia encapsulada pela LangChain, capaz de implementar perguntas e respostas de IA com base em uma base de conhecimento local.
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
cadeia_qa = RetrievalQA.from_chain_type(llm, retriever=vectorstore.as_retriever())
cadeia_qa({"query": questão})
{
'query': 'Quais são os métodos de decomposição de tarefas?',
'result': 'Os métodos de decomposição de tarefas incluem:\n\n1. Pistas Simples: Este método utiliza pistas simples ou perguntas para orientar o agente na decomposição da tarefa em submetas menores. Por exemplo, o agente pode ser orientado com "Passos para XYZ" e solicitado a listar os submetas para alcançar XYZ.\n\n2. Instruções Específicas da Tarefa: Neste método, instruções específicas da tarefa são fornecidas para orientar o processo de decomposição para o agente. Por exemplo, se a tarefa for escrever um romance, o agente pode ser instruído a "Esboçar um resumo da história" como um submeta.\n\n3. Entrada Humana: Este método envolve a incorporação da entrada humana no processo de decomposição da tarefa. Humanos podem fornecer orientação, feedback e sugestões para ajudar o agente a dividir tarefas complexas em submetas gerenciáveis.\n\nEsses métodos têm como objetivo lidar eficientemente com tarefas complexas, decompondo-as em partes menores e mais gerenciáveis.'
}
Observe que você pode passar "LLM" ou "Modelo de Chat" para a cadeia "RetrievalQA".
Dica: Este tutorial utiliza a cadeia
RetrievalQAintegrada na LangChain para implementar perguntas e respostas baseadas em conhecimento. Na realidade, para a nova versão da LangChain, utilizando expressões LangChain Language (LCEL), é fácil personalizar uma cadeia semelhante de perguntas e respostas. Consulte a seção relevante sobre LCEL.
Modelo de Prompt Personalizado
Ao usar a cadeia RetrievalQA anteriormente, não definimos uma palavra de prompt e utilizamos o modelo de palavra de prompt integrado da langchain. Agora, vamos personalizar o modelo de palavra de prompt.
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
template ="""Responda à pergunta com base no contexto abaixo.
Se você não souber a resposta, apenas diga "Eu não sei," e não tente fabricar uma resposta.
A resposta deve ser em 3 frases, e mantê-la concisa.
Sempre diga "Obrigado pela sua pergunta!" no final da resposta.
{context}
Pergunta: {question}
Resposta: """
CADEIA_QA_PROMPT = PromptTemplate.from_template(template)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
cadeia_qa = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": CADEIA_QA_PROMPT}
)
resultado = cadeia_qa({"query": questão})
resultado["result"]
Referência para Resposta de Perguntas e Respostas de IA
Use RetrievalQAWithSourcesChain em vez de RetrievalQA para retornar as respostas do IA com base em qual documento.
from langchain.chains import RetrievalQAWithSourcesChain
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(llm, retriever=vectorstore.as_retriever())
result = qa_chain({"question": question})
result
Seguindo o exemplo anterior de responder perguntas com base em links de blog, os resultados retornados são os seguintes, permitindo-nos ver que o IA respondeu à pergunta com base na URL específica do blog:
{
'question': 'Quais são os métodos para decomposição de tarefas?',
'answer': 'Os métodos para decomposição de tarefas incluem (1) o uso de LLM e prompts simples, (2) o uso de instruções específicas da tarefa e (3) envolver a entrada humana nela.\n',
'sources': 'https://lilianweng.github.io/posts/2023-06-23-agent/'
}