Ví dụ về AI Q&A dựa trên cơ sở kiến thức cục bộ
Giả sử bạn có một số tài liệu văn bản (PDF, blog, dữ liệu riêng tư cục bộ, v.v.) và muốn tạo một chatbot AI Q&A dựa trên cơ sở kiến thức cục bộ. Việc triển khai chức năng này bằng LangChain rất dễ dàng. Dưới đây là hướng dẫn từng bước về cách đạt được chức năng Q&A này bằng LangChain.
- Lưu ý: Do chi phí huấn luyện mô hình ngôn ngữ lớn (LLM) cao, cơ sở kiến thức của mô hình ngôn ngữ lớn chính nó sẽ không được cập nhật thường xuyên. Trí tuệ nhân tạo chỉ biết nội dung mà nó đã được huấn luyện và không hiểu về nội dung mới hoặc dữ liệu cá nhân/doanh nghiệp cục bộ, vì vậy việc kết hợp cơ sở kiến thức cục bộ với mô hình ngôn ngữ lớn là cần thiết.
Quy trình AI Q&A
-
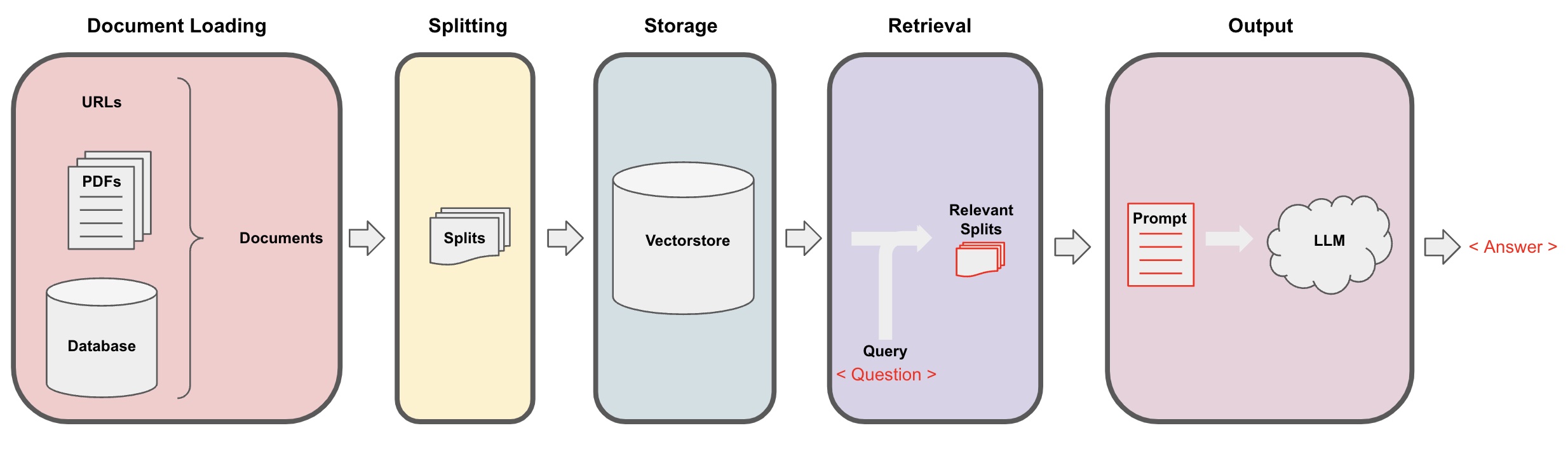
Tải tài liệu: Trước hết, chúng ta cần tải dữ liệu văn bản cục bộ của chúng ta, điều này có thể được thực hiện bằng cách sử dụng thành phần tải của LangChain. -
Phân đoạn tài liệu: Sử dụng công cụ phân đoạn văn bản của LangChain để chia các tài liệu thành các đoạn văn bản có kích thước cụ thể. (Lưu ý: Mục đích của việc phân đoạn văn bản là để thuận tiện cho việc tìm kiếm các đoạn văn bản liên quan dựa trên các câu hỏi. Một lý do khác cho việc phân đoạn là mô hình ngôn ngữ lớn có giới hạn mã thông báo tối đa.) -
Lưu trữ: Sau khi phân đoạn các tài liệu, tính toán các vector đặc trưng của tài liệu bằng một mô hình nhúng và sau đó lưu trữ chúng trong cơ sở dữ liệu vector. -
Truy xuất: Dựa trên câu hỏi, truy vấn cơ sở dữ liệu vector để truy xuất các đoạn văn bản tương tự. -
Tạo ra: Sử dụng chuỗi QA của LangChain để thực hiện Q&A, nối các đoạn văn bản liên quan đến câu hỏi với chính câu hỏi để tạo ra các lời nhắc AI do bạn thiết kế, và chuyển chúng đến LLM để trả lời câu hỏi. -
Hội thoại(tùy chọn): Bằng cách thêm thành phần Memory vào chuỗi QA, bạn có thể thêm chức năng lưu trữ tin nhắn lịch sử của AI để thuận tiện cho các cuộc hội thoại đa lượt.
Quy trình AI Q&A được minh họa trong sơ đồ sau:
Bắt đầu
Để bắt đầu nhanh chóng, quy trình ở trên có thể được bọc trong một đối tượng đơn VectorstoreIndexCreator. Giả sử chúng ta muốn tạo một chương trình Q&A dựa trên bài đăng blog này. Điều này có thể được thực hiện chỉ với một vài dòng mã:
- Lưu ý: Chương trình này vẫn sử dụng mô hình ngôn ngữ lớn của OpenAI.
Trước tiên, thiết lập các biến môi trường và cài đặt các gói cần thiết:
pip install openai chromadb
export OPENAI_API_KEY="..."
Sau đó chạy:
from langchain_community.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
index = VectorstoreIndexCreator().from_loaders([loader])
Bây giờ, bắt đầu đặt câu hỏi:
index.query("What is task decomposition?")
Phân rã nhiệm vụ là một kỹ thuật để phân chia các nhiệm vụ phức tạp thành các bước nhỏ hơn, đơn giản hơn. Điều này có thể được thực hiện bằng cách sử dụng LLM với các nhắc đơn giản, hướng dẫn cụ thể về nhiệm vụ, hoặc thông tin đầu vào từ con người. Mindtrees (Yao et al.2023) là một ví dụ về kỹ thuật phân rã nhiệm vụ, nơi khám phá nhiều khả năng lập luận tại mỗi bước và tạo ra nhiều ý tưởng tại mỗi bước để tạo ra một cấu trúc cây.
Chương trình đang chạy, nhưng nó được triển khai như thế nào ở dưới tấm lòng? Hãy phân tích quá trình từng bước.
Bước 1. Tải dữ liệu (Loading Document Data)
Xác định một DocumentLoader để tải dữ liệu đã chỉ định vào một đối tượng Documents. Đối tượng Document đại diện cho một đoạn văn bản (page_content) và siêu dữ liệu liên quan.
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
- Lưu ý: Langchain cung cấp các trình tải khác nhau để thuận tiện cho việc tải các loại dữ liệu khác nhau, có thể tham khảo trong các chương trước đó.
Bước 2. Chia (Splitting Documents)
Do câu nhắc của mô hình lớn có giới hạn mã thông báo tối đa, chúng ta không thể chuyển quá nhiều nội dung văn bản cho trí tuệ nhân tạo. Thường đủ để chuyển các đoạn văn bản có liên quan, vì vậy chúng ta cần xử lý các phân đoạn văn bản ở đây.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 0)
all_splits = text_splitter.split_documents(data)
Bước 3. Lưu trữ (Lưu trữ Vectơ)
Để truy vấn các đoạn văn bản liên quan dựa trên một câu hỏi, chúng ta cần tính toán các vectơ đặc trưng văn bản cho các đoạn văn bản đã được chia trước đó bằng một mô hình nhúng, sau đó lưu trữ chúng trong cơ sở dữ liệu vectơ.
Ở đây, chúng ta sử dụng cơ sở dữ liệu vectơ mặc định "chroma" do Langchain cung cấp, và sau đó sử dụng mô hình nhúng của openai.
- Lưu ý: Bạn cũng có thể chọn các mô hình mã nguồn mở khác để thay thế cho mô hình nhúng.
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
Bước 4. Truy xuất (Truy vấn Tài liệu Liên quan)
Truy xuất các đoạn văn bản liên quan đến câu hỏi thông qua tìm kiếm độ tương đồng.
- Lưu ý: Mục đích của bước này là để thực hiện chức năng tìm kiếm độ tương đồng của cơ sở dữ liệu vectơ. Chức năng của bước này tự động được bao gồm trong chuỗi Q&A được đóng gói bởi Langchain ở bước thứ 5.
question = "Các phương pháp phân rã công việc là gì?"
docs = vectorstore.similarity_search(question)
len(docs)
4
Bước 5. Tạo ra (Sử dụng Trí tuệ nhân tạo để trả lời câu hỏi)
Sử dụng mô hình LLM/Chat (ví dụ: gpt-3.5-turbo) và chuỗi RetrievalQA để rút gọn đoạn văn bản đã truy xuất thành một câu trả lời duy nhất.
- Gợi ý:
RetrievalQAlà một chuỗi được đóng gói bởi LangChain, có khả năng thực hiện trả lời câu hỏi dựa trên cơ sở kiến thức cục bộ.
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectorstore.as_retriever())
qa_chain({"query": question})
{
'query': 'Các phương pháp phân rã công việc là gì?',
'result': 'Các phương pháp phân rã công việc bao gồm:\n\n1. Gợi ý đơn giản: Phương pháp này sử dụng các gợi ý đơn giản hoặc câu hỏi để hướng dẫn cho người thực hiện phân rã công việc thành các mục tiêu phụ nhỏ hơn. Ví dụ, người thực hiện có thể được yêu cầu với câu hỏi "Bước để XYZ" và được yêu cầu liệt kê các mục tiêu phụ để đạt được XYZ.\n\n2. Hướng dẫn Cụ thể cho Công việc: Trong phương pháp này, các hướng dẫn cụ thể cho công việc được cung cấp để hướng dẫn quá trình phân rã cho người thực hiện công việc. Ví dụ, nếu công việc là viết một cuốn tiểu thuyết, người thực hiện có thể được hướng dẫn "Lập kế hoạch nội dung câu chuyện" như một mục tiêu phụ.\n\n3. Đầu vào từ Con người: Phương pháp này liên quan đến việc tích hợp đầu vào từ con người vào quá trình phân rã công việc. Con người có thể cung cấp hướng dẫn, phản hồi và gợi ý để giúp người thực hiện phân rã những công việc phức tạp thành các mục tiêu phụ có thể quản lý được.\n\nNhững phương pháp này nhằm mục đích xử lý công việc phức tạp một cách hiệu quả bằng cách phân rã chúng thành các phần nhỏ hơn, dễ quản lý hơn.'
}
Lưu ý rằng bạn có thể truyền "LLM" hoặc "ChatModel" cho chuỗi "RetrievalQA".
Gợi ý: Hướng dẫn này sử dụng chuỗi
RetrievalQAtích hợp sẵn trong LangChain để thực hiện trả lời câu hỏi dựa trên kiến thức. Trong thực tế, đối với phiên bản mới của LangChain, sử dụng ngôn ngữ Biểu thức LangChain (LCEL), rất dễ tùy chỉnh một chuỗi trả lời câu hỏi tương tự. Vui lòng tham khảo phần liên quan về LCEL.
Mẫu Gợi ý Tùy chỉnh
Khi sử dụng chuỗi RetrievalQA trước đó, chúng ta không thiết lập một từ gợi ý và sử dụng mẫu từ gợi ý tích hợp sẵn từ langchain. Bây giờ, hãy tùy chỉnh mẫu từ gợi ý.
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
template ="""Trả lời câu hỏi dựa trên ngữ cảnh bên dưới.
Nếu bạn không biết câu trả lời, chỉ cần nói "Tôi không biết," và không cố gắng dựng lời giải.
Câu trả lời nên ở trong vòng 3 câu, và hãy giữ ngắn gọn.
Luôn nói "Cảm ơn bạn đã đặt câu hỏi!" ở cuối câu trả lời.
{context}
Câu hỏi: {question}
Câu trả lời: """
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)
result = qa_chain({"query": question})
result["result"]
Tham khảo cho câu trả lời AI Q&A
Sử dụng RetrievalQAWithSourcesChain thay vì RetrievalQA để trả về câu trả lời của trí tuệ nhân tạo dựa trên tài liệu nào.
from langchain.chains import RetrievalQAWithSourcesChain
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(llm, retriever=vectorstore.as_retriever())
result = qa_chain({"question": question})
result
Xây dựng trên ví dụ trước đó về việc trả lời câu hỏi dựa trên liên kết blog, kết quả trả về như sau, cho phép chúng ta thấy rằng trí tuệ nhân tạo đã trả lời câu hỏi dựa trên địa chỉ URL cụ thể của blog:
{
'question': 'Phương pháp nào được sử dụng để phân tách công việc?',
'answer': 'Các phương pháp phân tách công việc bao gồm (1) sử dụng LLM và các lời nhắc đơn giản, (2) sử dụng hướng dẫn cụ thể cho từng nhiệm vụ, và (3) sự tham gia của con người trong quá trình này.\n',
'sources': 'https://lilianweng.github.io/posts/2023-06-23-agent/'
}