1. LangServe Overview
LangServe is a library that helps developers run programs and chains of LangChain as REST APIs. It integrates FastAPI and uses pydantic for data validation.
2. Features
LangServe has the following features:
- Automatically infers input and output modes from LangChain objects and performs validation for each API call, providing rich error messages
- API documentation page containing JSONSchema and Swagger
- Efficient
/invoke/,/batch/, and/stream/endpoints supporting many concurrent requests on a single server -
/stream_log/endpoint for streaming all (or part) of the intermediate steps of the chain/agent -
New feature as of version 0.0.40, supports
astream_eventsto make streaming easier without parsing the output ofstream_log -
/playground/page with streaming output and intermediate steps - Optional built-in tracing to LangSmith, just by adding your API key
- Built with battle-tested open-source Python libraries such as FastAPI, Pydantic, uvloop, and asyncio
- Invoke LangServe server using a client SDK just like calling a locally running Runnable (or directly calling the HTTP API)
- LangServe Hub
3. Limitations
- Client callbacks for events originating from the server are not yet supported
- OpenAPI documentation is not generated when using Pydantic V2. FastAPI does not support mixed pydantic v1 and v2 namespaces. See the section below for more details.
4. Installation
You can install LangServe using the following command:
pip install "langserve[all]"
Or install client code using pip install "langserve[client]", and server code using pip install "langserve[server]".
4. Sample Application
Below, we demonstrate how to publish models, chains, and agents defined in LangChain as REST APIs for other applications to call. If you are familiar with FastAPI, it's simple, just use the utility class provided by langserve to register FastAPI routes.
The following example deploys an OpenAI chat model, an Anthropic chat model, and a chain using the Anthropic model to tell jokes about specific topics.
Here is the sample code:
from fastapi import FastAPI
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatAnthropic, ChatOpenAI
from langserve import add_routes
app = FastAPI(
title="LangChain Server",
version="1.0",
description="Simple API server using Runnable interface of LangChain",
)
add_routes(
app,
ChatOpenAI(),
path="/openai",
)
add_routes(
app,
ChatAnthropic(),
path="/anthropic",
)
model = ChatAnthropic()
prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
add_routes(
app,
prompt | model,
path="/joke",
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)
If you intend to call the endpoints from a browser, you also need to set CORS headers. You can achieve this using the built-in middleware in FastAPI:
from fastapi.middleware.cors import CORSMiddleware
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
expose_headers=["*"],
)
5. Documentation
After running the example above, LangServe automatically generates API documentation for all registered routes. You can check the generated OpenAPI documentation at the following address:
http://localhost:8000/docs
Make sure to append the /docs suffix.
⚠️ If using pydantic v2, the documentation will not be generated for invoke, batch, stream, and stream_log. It is recommended to use pydantic v1 version.
6. Introduction to API Routes
Below is an introduction to the API interfaces generated by LangServe after registering an API route.
For example, consider the following code:
add_routes(
app,
runnable,
path="/my_runnable",
)
LangServe will generate the following interfaces:
-
POST /my_runnable/invoke- Interface for model invocation -
POST /my_runnable/batch- Interface for batch model invocation -
POST /my_runnable/stream- Interface for streaming model invocation -
POST /my_runnable/stream_log- Interface for streaming model invocation with log output -
POST /my_runnable/astream_events- Asynchronous streaming model invocation with event output -
GET /my_runnable/input_schema- Interface parameter description for model invocation -
GET /my_runnable/output_schema- Interface parameter description for model output -
GET /my_runnable/config_schema- Configuration description of the model
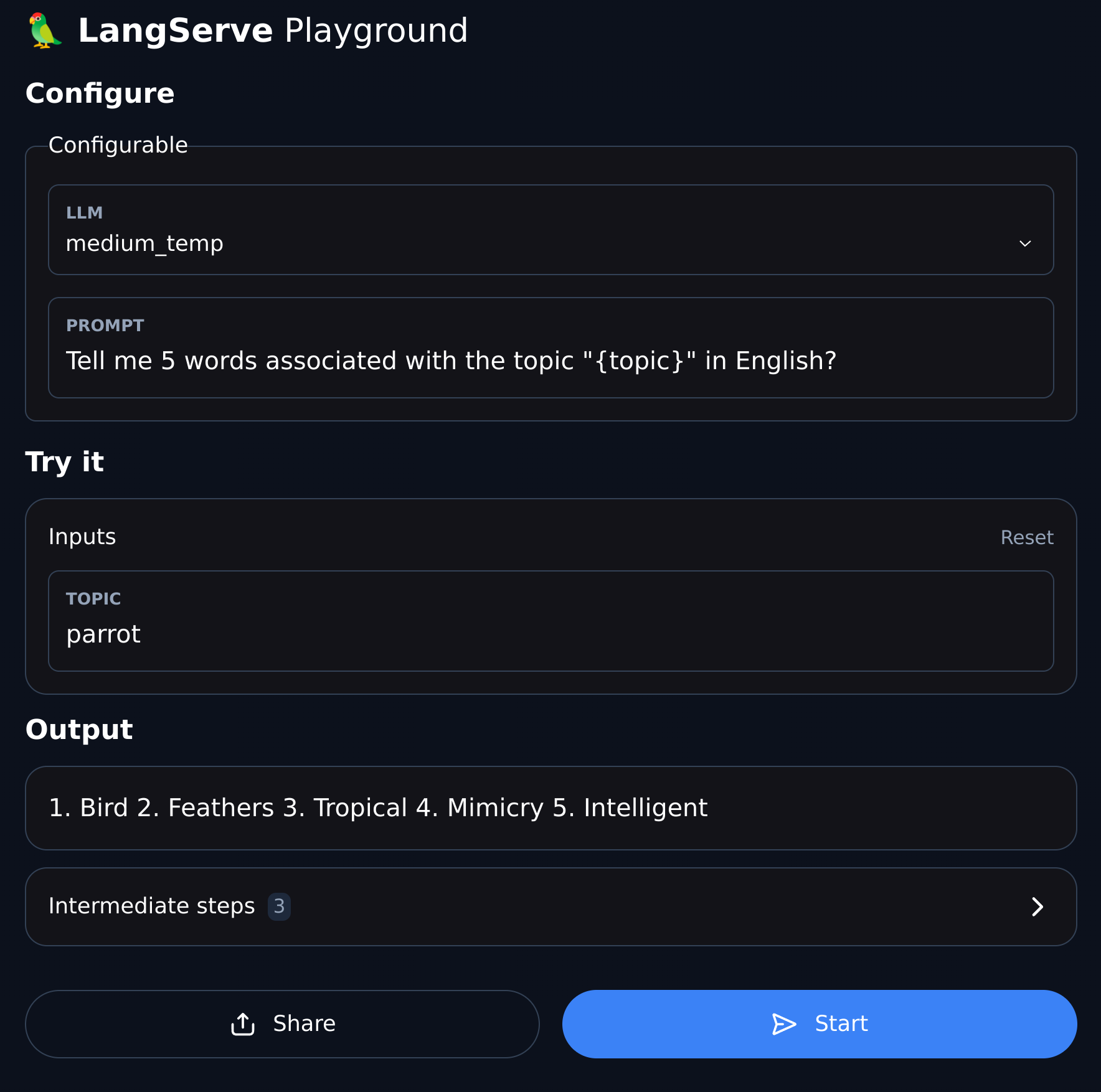
7. Playground
LangServe provides a UI debugging page for each registered route, making it convenient to debug the Chain, Agent, and other LangChain services we define.
You can access the Playground example in the following format: visit /my_runnable/playground/.