Esempio di domande e risposte basate su una base di conoscenza locale
Supponiamo di avere alcuni documenti di testo (PDF, blog, dati privati locali, ecc.) e vogliamo creare un chatbot di domande e risposte basato su una base di conoscenza locale. È facile implementare questa funzionalità utilizzando LangChain. Di seguito è riportata una guida passo-passo su come ottenere questa funzionalità Q&A utilizzando LangChain.
- Nota: A causa dell'alto costo di addestramento del LLM (Large Language Model), la base di conoscenza del grande modello di linguaggio stesso non verrà aggiornata frequentemente. L'IA conosce solo i contenuti su cui è stata addestrata e non è a conoscenza di nuovi contenuti o di dati privati aziendali/personali, quindi è necessario combinare la base di conoscenza locale con il grande modello di linguaggio.
Processo di domande e risposte dell'IA
-
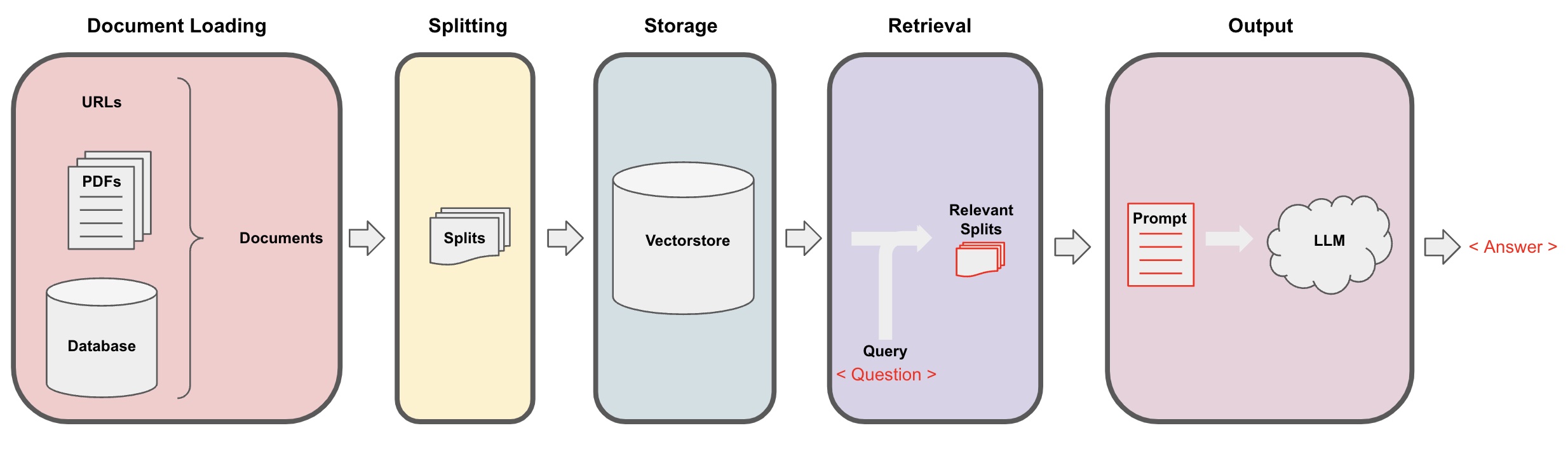
Caricamento del documento: Prima di tutto, dobbiamo caricare i nostri dati di testo locali, che può essere realizzato utilizzando il componente di caricamento di LangChain. -
Splitting dei documenti: Utilizzare lo splitter di testo di LangChain per suddividere i documenti in frammenti di testo di dimensioni specificate. (Nota: Lo scopo della suddivisione del testo è quello di facilitare la ricerca dei frammenti di contenuto rilevanti in base alle domande. Un'altra ragione per la suddivisione è che il grande modello di linguaggio ha un limite massimo di token.) -
Archiviazione: Dopo aver suddiviso i documenti, calcolare i vettori delle caratteristiche del documento utilizzando un modello di incorporamento e quindi archiviarli in un database vettoriale. -
Recupero: In base alla domanda, interrogare il database vettoriale per recuperare frammenti di documento simili. -
Generazione: Utilizzare la catena di domande e risposte di LangChain per eseguire domande e risposte, concatenare i frammenti di documento relativi alla domanda con la domanda stessa in prompt AI progettati da te e passarli al LLM per rispondere alla domanda. -
Conversazione(opzionale): Aggiungendo il componente Memory alla catena di domande e risposte, è possibile aggiungere la funzionalità di memoria dei messaggi storici dell'IA per facilitare i dialoghi multigiro di domande e risposte.
Il processo di domande e risposte dell'IA è illustrato nel diagramma seguente:
Per iniziare
Per iniziare rapidamente, il processo sopra può essere avvolto in un singolo oggetto VectorstoreIndexCreator. Supponiamo di voler creare un programma di domande e risposte basato su questo post del blog. Questo può essere ottenuto con poche righe di codice:
- Nota: Questo capitolo utilizza ancora il grande modello di linguaggio di OpenAI.
Prima, impostare le variabili di ambiente e installare i pacchetti richiesti:
pip install openai chromadb
export OPENAI_API_KEY="..."
Poi eseguire:
from langchain_community.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
index = VectorstoreIndexCreator().from_loaders([loader])
Ora, iniziare a fare domande:
index.query("Cosa significa scomposizione dei compiti?")
La scomposizione dei compiti è una tecnica per suddividere compiti complessi in passaggi più piccoli e più semplici. Può essere fatta utilizzando LLM con prompt semplici, istruzioni specifiche per il compito o input umano. Mindtrees (Yao et al.2023) è un esempio di tecnica di scomposizione dei compiti, che esplora più possibilità di ragionamento ad ogni passaggio e genera più idee ad ogni passaggio per creare una struttura ad albero.
Il programma è in esecuzione, ma come è implementato sotto il cofano? Vediamo il processo passo dopo passo.
Passo 1. Caricamento (Caricamento dei Dati dei Documenti)
Specificare un DocumentLoader per caricare i dati specificati in un oggetto Documents. L'oggetto Document rappresenta un pezzo di testo (page_content) e metadati correlati.
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
- Nota: Langchain fornisce vari caricatori per il caricamento comodo di diversi tipi di dati, che possono essere consultati nei capitoli precedenti.
Passo 2. Suddivisione (Suddivisione dei Documenti)
Poiché i prompt dei modelli di grandi dimensioni hanno un limite massimo di token, non possiamo passare troppo contenuto del documento all'IA. Di solito è sufficiente passare frammenti di documento pertinenti, quindi dobbiamo elaborare i tagli del documento qui.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 0)
all_splits = text_splitter.split_documents(data)
Passo 3. Memoria (Archiviazione vettoriale)
Per poter interrogare frammenti di documenti pertinenti basati su una domanda, è necessario calcolare i vettori delle caratteristiche del testo per i frammenti di documenti precedentemente suddivisi utilizzando un modello di incorporamento e quindi archiviarli in un database vettoriale.
Qui utilizziamo il database vettoriale predefinito "chroma" fornito da Langchain e quindi utilizziamo il modello di incorporamento di openai.
- Nota: è anche possibile scegliere altri modelli open source come sostituti del modello di incorporamento.
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
Passo 4. Recupero (Interrogazione documenti pertinenti)
Recupera frammenti di documenti correlati alla domanda attraverso una ricerca di similarità.
- Nota: lo scopo di questo passaggio è quello di dimostrare la funzione di ricerca di similarità del database vettoriale. La funzionalità di questo passaggio è automaticamente inclusa nella catena Q&A racchiusa da Langchain nel 5° passaggio.
domanda = "Quali sono i metodi di scomposizione dei compiti?"
docs = vectorstore.similarity_search(question)
len(docs)
4
Passo 5. Generazione (Utilizzo dell'IA per rispondere alle domande)
Utilizza il modello LLM/Chat (ad es. gpt-3.5-turbo) e la catena RetrievalQA per condensare il documento recuperato in una singola risposta.
- Suggerimento:
RetrievalQAè una catena racchiusa da LangChain, in grado di implementare risposte AI basate su una base di conoscenze locali.
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectorstore.as_retriever())
qa_chain({"query": question})
{
'query': 'Quali sono i metodi di scomposizione dei compiti?',
'result': 'I metodi di scomposizione dei compiti includono:\n\n1. Suggerimenti semplici: Questo metodo utilizza semplici suggerimenti o domande per guidare l'agente nella scomposizione del compito in obiettivi più piccoli. Ad esempio, all'agente può essere suggerito "Passaggi per XYZ" e chiesto di elencare i sotto-obiettivi per raggiungere XYZ.\n\n2. Istruzioni specifiche del compito: In questo metodo, vengono fornite istruzioni specifiche del compito per guidare il processo di scomposizione per l'agente. Ad esempio, se il compito è scrivere un romanzo, all'agente può essere istruito di "Bozza di un'outline della storia" come sotto-obiettivo.\n\n3. Input umano: Questo metodo comporta l'incorporazione dell'input umano nel processo di scomposizione del compito. Gli esseri umani possono fornire orientamento, feedback e suggerimenti per aiutare l'agente a suddividere compiti complessi in sotto-obiettivi gestibili.\n\nQuesti metodi mirano a gestire efficacemente i compiti complessi scomponendoli in parti più piccole e gestibili.'
}
Si noti che è possibile passare "LLM" o "ChatModel" alla catena "RetrievalQA".
Suggerimento: questo tutorial utilizza la catena "RetrievalQA" incorporata in LangChain per implementare la risposta alle domande basata sulla conoscenza. In realtà, per la nuova versione di LangChain, utilizzando le espressioni del Linguaggio di Espressione LangChain (LCEL), è facile personalizzare una catena simile per rispondere alle domande. Si prega di fare riferimento alla sezione pertinente su LCEL.
Modello di Prompt Personalizzato
Quando si è utilizzata la catena RetrievalQA in precedenza, non si è impostata una parola di prompt e si è utilizzato il modello di parola di prompt incorporato in langchain. Ora, personalizziamo il modello di parola di prompt.
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
template ="""Rispondi alla domanda in base al contesto sottostante.
Se non conosci la risposta, limitati a dire "Non lo so", e non tentare di inventare una risposta.
La risposta dovrebbe essere entro 3 frasi e deve essere concisa.
Termina sempre con "Grazie per la tua domanda!" alla fine della risposta.
{context}
Domanda: {question}
Risposta: """
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)
result = qa_chain({"query": question})
result["result"]
Riferimento per la risposta di Q&A sull'IA
Utilizza RetrievalQAWithSourcesChain invece di RetrievalQA per restituire le risposte dell'IA basate su quale documento.
from langchain.chains import RetrievalQAWithSourcesChain
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(llm, retriever=vectorstore.as_retriever())
result = qa_chain({"question": domanda})
result
Costruendo sull'esempio precedente di rispondere alle domande basate su collegamenti ai blog, i risultati restituiti sono i seguenti, ciò ci permette di vedere che l'IA ha risposto alla domanda basandosi sull'URL specifico del blog:
{
'domanda': 'Quali sono i metodi per la decomposizione dei compiti?',
'risposta': 'I metodi per la decomposizione dei compiti includono (1) utilizzare LLM e frasi semplici, (2) utilizzare istruzioni specifiche del compito e (3) coinvolgere l'input umano al suo interno.\n',
'fonti': 'https://lilianweng.github.io/posts/2023-06-23-agent/'
}