স্থানীয় জ্ঞান ভিত্তিক এআই প্রশ্ন-উত্তর এর উদাহরণ
মনে করুন আপনার কিছু পাঠ্য দস্তাবেজ (পিডিএফ, ব্লগ, স্থানীয় ব্যক্তিগত ডেটা, ইত্যাদি) আছে এবং একটি স্থানীয় জ্ঞান ভিত্তিক এআই প্রশ্ন-উত্তর চ্যাটবট তৈরি করতে চান। এই প্রযুক্তি পেতে LangChain ব্যবহার করা সহজ। নিম্নলিখিত পদক্ষেপের মাধ্যমে LangChain ব্যবহার করে এই প্রশ্ন-উত্তর কার্যকারিতা পেতে যায়।
- দ্রষ্টব্য: LLM (বড় ভাষার মডেল) প্রশিক্ষণের উচ্চ মূল্যের কারণে, বড় ভাষার মডেলের জ্ঞানের বিশেষ ভিত্তিতেই অভ্যন্তরীণ উপাত্তসমূহ সঙ্গীত হতে হবে, বৃহত্তর ভাষার মডেলটি নিজে বেশ নয়টা সাধারণ হবে। প্রস্তুত নেওয়া কন্টেন্ট যার উপর প্রশিক্ষিত হয়েছে তাকে ছাড়া, এই এআই-তে আরও কোন নতুন কন্টেন্ট বা কোম্পানি/ব্যক্তিগত ব্যক্তিগত ডেটা নেই, তাই এটি প্রয়োজনীয় যে স্থানীয় জ্ঞানের ভিত্তি বড় ভাষার মডেলের সঙ্গে যোগ করা।
এআই প্রশ্ন-উত্তর প্রক্রিয়া
-
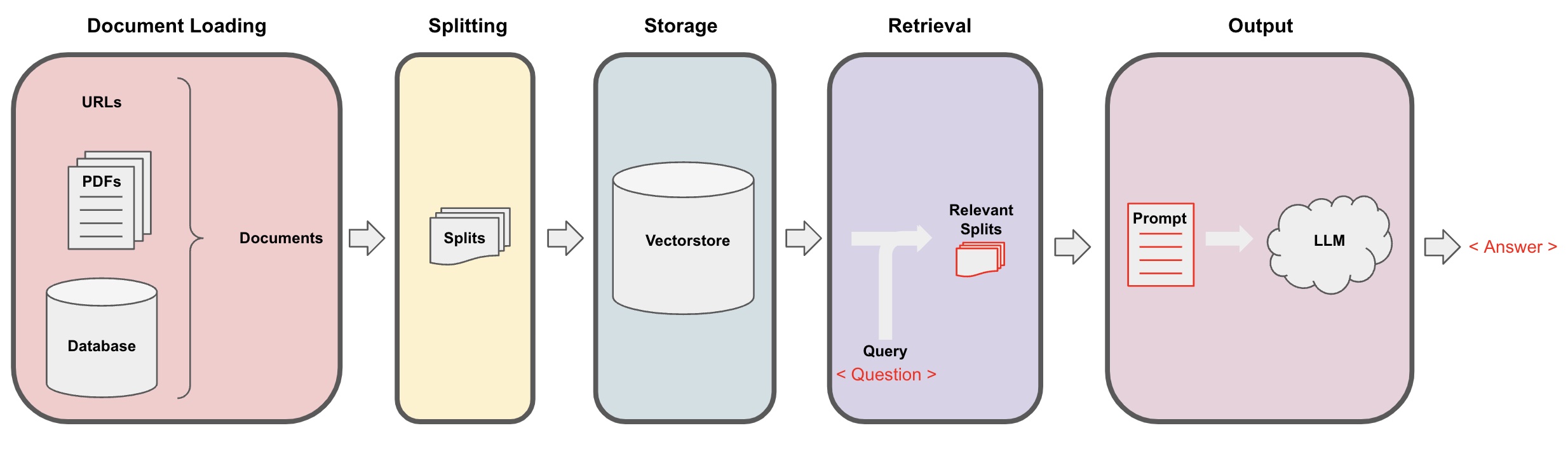
ডকুমেন্ট লোডিং: প্রথমে, আমাদের স্থানীয় পাঠ্য ডেটা লোড করতে হবে, যা LangChain এর লোডার কম্পোনেন্ট ব্যবহার করে সাধ্য হতে পারে। -
ডকুমেন্ট ভাগবেদনা: LangChain এর টেক্সট স্প্লিটারটি ব্যবহার করে ডকুমেন্টগুলি নির্দিষ্ট সাইজের টেক্সট ফ্র্যাগমেন্টে ভাগ করুন। (নোট: টেক্সট ভাগ করার উদ্দেশ্য প্রশ্নের ভিত্তিতে সম্পর্কিত কন্টেন্ট ফ্র্যাগমেন্ট অনুসন্ধান করার উদ্দেশ্যে এবং অন্য কারণ কি টেক্সট ভাগ করা আছে তা হলো বড় ভাষার মডেলের সর্বাধিক টোকেন লিমিট।) -
স্টোরেজ: ডকুমেন্টগুলি ভাগবিন্যস্ত করার পর, এম্বেডিং মডেল ব্যবহার করে ডকুমেন্ট ফিচার ভেক্টর গণনা করুন এবং তারপর তাদেরকে ভেক্টর ডাটাবেজে সংরক্ষণ করুন। -
রিট্রিভ্যাল: প্রশ্নের ভিত্তিতে, ভেক্টর ডাটাবেজ পূর্বের দস্তাবেজ ফ্র্যাগমেন্ট অনুসন্ধান করতে কাজ করুন। -
জেনারেশন: LangChain এর QA চেইন ব্যবহার করে প্রশ্ন-উত্তর করতে, প্রশ্নের সাথে সম্পর্কিত ডকুমেন্ট ফ্র্যাগমেন্টগুলি আপনার নির্দেশিত এআই প্রোম্প্টে যুক্ত করুন এবং এগুলি এলএমএম-এ প্রশ্নের উত্তর দিন। -
সংলাপ(ঐচ্ছিক): কিছুর স্মরণের কম্পোনেন্ট যুক্ত করে এআই ঐতিহাসিক বার্তা স্মৃতি কার্যকারিতা যোগ করে, আপনি এআই বহু-টার্ন প্রশ্ন-উত্তর সংলাপ পাল্টাতে পারেন।
উপরোক্ত এআই প্রশ্ন-উত্তর প্রক্রিয়াটি নিম্নলিখিত ডায়াগ্রামে প্রদর্শিত:
শুরু করা হচ্ছে
একটি সংক্ষিপ্ত শর্তে উপরোক্ত প্রক্রিয়াটি একইসাথে VectorstoreIndexCreator নামক একটি অবজেক্টে ঘেরে ফেলা যেতে পারে। মনে করা যাক, আমরা এই ব্লগ পোস্ট ভিত্তিক একটি প্রশ্ন-উত্তর প্রোগ্রাম তৈরি করতে চাই। এটি কোনও কিছু লাইন কোড ব্যবহার করে অর্জন করা যা হতে পারে:
- নোট: এই অধ্যায়টি এখনও OpenAI এর বড় ভাষার মডেল ব্যবহার করে।
প্রথমে, পরিবেশের ভেরিয়েবল সেট করুন এবং প্রয়োজনীয় প্যাকেজগুলি ইনস্টল করুন:
pip install openai chromadb
export OPENAI_API_KEY="..."
তারপর সারি চালান:
from langchain_community.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
index = VectorstoreIndexCreator().from_loaders([loader])
এখন, প্রশ্ন করা শুরু করুন:
index.query("What is task decomposition?")
টাস্ক ডিকম্পোজিশন হল অসংখ্য সাধারণ স্টেপ বিভজন করার একটি প্রযুক্তি। এটি বেশি জটিল কাজগুলির অংশগুলি ছোট ও সহজ করার একটি প্রক্রিয়া। এটি সাধারণ প্রোম্পট দিয়ে, কাজ-নির্দিষ্ট নির্দেশিকা বা মানব ইনপুট দিয়ে LLM দ্বারা করা হতে পারে। মাইন্ডট্রিস (Yao et al.2023) একটি টাস্ক ডিকমপোজিশন তেকনিকের উদাহরণ, যা প্রতিটি পল্লবে বড় পরিকল্পনা সম্ভাবনা এবং প্রতিটি পল্লবে অনেকগুলি ধারণা উৎপন্ন করে এবং একটি বৃক্ষাকার প্রস্তাবনা তৈরী করার জন্য একাধিক তার সাথে বাস্তবোস্পদ মান্য করে।
প্রোগ্রামটি চলছে, তবে এটি হুডে কিভাবে প্রয়ান করা হয়েছে? চলুন ধারণা অনুসন্ধান করি এই প্রক্রিয়াটি প্রতি পদক্ষেপে।
পদক্ষেপ 1. লোড করা (ডকুমেন্ট ডেটা লোড করা)
নির্দিষ্ট ডেটা লোড করা এবং ডকুমেন্টস অবজেক্টে সরবরাহ সংশ্লিষ্ট মেটাডেটা দিয়ে একটি টেক্সট ভাগসমূহ প্রতিনিধি করা প্রতিটি টেক্সট এবং সম্পর্কিত মেটাডেটার।
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
- নোট: বিভিন্ন ধরনের ডেটা সহজে সরঞ্জামের জন্য বিভিন্ন লোডার প্রদান করা হয়, যা আগের অধ্যায়ে রেফার করা যেতে পারে।
পদক্ষেপ 2. ভাগ (ডকুমেন্ট ভাগ করা)
বড় মডেল প্র
পদক্ষেপ ৩. সংরক্ষণ (ভেক্টর সংরক্ষণ)
প্রশ্নের ভিত্তিতে সম্পর্কিত নথি টুকরা প্রশ্ন করার জন্য, আমাদের পূর্বে বিভক্ত নথি টুকরা গুলির জন্য একটি এম্বেডিং মডেল ব্যবহার করে পাঠযোগ্য ভেক্টর গুলি গণনা করতে হবে, এবং তারপর তাদেরকে একটি ভেক্টর ডাটাবেসে সংরক্ষণ করতে হবে।
এখানে আমরা ল্যাংচেন দ্বারা প্রদত্ত 'chroma' ভেক্টর ডাটাবেস ব্যবহার করি, এবং তারপর ওপেনএআই এম্বেডিং মডেল ব্যবহার করি।
- লক্ষ্য: আপনি যদি চান তবে আপনি অন্যান্য মৌলিক মডেলগুলি নির্বাচন করতে পারেন এম্বেডিং মডেল এর জন্য।
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
পদক্ষেপ ৪. পুনর্প্রাপ্তপ্রায় (প্রশ্ন বিষয়ক নথিসমূহ)
প্রশ্নের সাথে সম্পর্কিত নথি টুকরা খুঁজে বের করুন।
- লক্ষ্য: এই পদক্ষেপের উদ্দেশ্য হল ভেক্টর ডাটাবেসের এইচসচ ফাংশনটি প্রদর্শন করা। ল্যাংচেন দ্বারা ৫ম পদক্ষেপে প্রস্তুত করা কিউ এবং এএ চেইন দ্বারা এই পদক্ষেপের কার্যক্ষমতাগুলি স্বয়ংক্রিয়ভাবে অন্তর্ভুক্ত হয়।
question = "কাজ বিভক্তির পদ্ধতিগুলি কী কী?"
docs = vectorstore.similarity_search(question)
len(docs)
4
পদক্ষেপ ৫. উত্তর তৈরি (প্রশ্নের উপর AI ব্যবহার করে)
রিট্রিভাল ডিবি এমন একটি চেন ব্যবহার করে প্রাপ্ত নথিটি একটি একক উত্তরে সংক্ষেপন করার জন্য LLM/Chat মডেল (যেমন gpt-3.5-turbo) এবং RetrievalQA চেইন ব্যবহার করা।
- সূচনা:
RetrievalQAহল একটি চেন যা ল্যাংচেন দ্বারা ক্ষমতাশালী ভাবে একটি লোকাল জ্ঞান ভিত্তিক প্রশ্ন-উত্তর প্রণালী প্রদান করতে পারে।
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectorstore.as_retriever())
qa_chain({"query": question})
{
'query': 'কাজ বিভক্তির পদ্ধতিগুলি কী কী?',
'result': 'কাজ বিভক্তির পদ্ধতিগুলি নিম্নলিখিত:\n\n1. সাধারণ প্রম্পটস: এই পদ্ধতিটি সহজ প্রম্পট বা প্রশ্নসমূহ ব্যবহার করে কার্যের অনুভূতিটি ছোট উল্লেখ করার জন্য। যেমন, অবধির XYZ\'র "জন্য পদক্ষেপ" ও কিছু উল্লেখ করে প্রত্যাহার করা যেতে পারে।\n\n2. কাজ-বিশেষ নির্দেশিকা: এই পদ্ধতিতে, কাজ-বিশেষ নির্দেশিকা কাজ বিভক্তি প্রক্রিয়া পরিচালনার জন্য প্রদান করা হয়। উদাহরণস্বরূপ, যদি কোনো উপায়ে নতুন লেখা লিখা হয়, তবে উপায়ে বলা হয় যে, "একটি গল্পের বোঝাই প্রতিলিপি তৈরি করুন"।\n\n3. মানুষিক ইনপুট: এই পদ্ধতিতে কাজ বিভক্তি প্রক্রিয়ায় মানুষিক ইনপুট অন্তর্ভূক্ত করা হয়। মানুষরা উপায়, প্রতিজ্ঞা, এবং পরামর্শ সরবরাহ করতে পারে, যাতে অসমীচ্ছ কাজগুলি ছোট উপায়ে বিভক্ত হতে পারে।\n\nএই পদ্ধতিগুলি বড় কাজগুলি পরিষ্কারের জন্য নামান্য অংশে ভাগ করার উদ্দেশ্যে থাকে। '
}
দয়া করে অনুবাদ এবং অনুপ্রেরণার জন্য ধন্যবাদ জানান।
কাস্টম প্রম্পট টেম্পলেট
আগের "রিট্রিভাল চেইন" ব্যবহার করার সময়, আমরা কোনও প্রম্পট শব্দ সেট করিনি এবং langchain হতে নির্মিত প্রোম্পট শব্দ টেম্পলেট ব্যবহার করি। এখন, আসুন এই প্রোম্পট শব্দ টেম্পলেট কাস্টমাইজ করে দেখি।
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
template ="""উপরের সন্দর্ভে ভিত্তি করে প্রশ্নের উত্তর দিন।
আপনি যদি জানা না তাহলে বলুন "আমি জানি না," এবং কোনও প্রতারণা করা চেষ্টা না করুন।
উত্তরটির ভেতরের অংশটি 3 লাইনের মধ্যে রাখুন, এবং এটি সংক্ষেপে রাখুন।
উত্তর শেষে সবসময় "আপনার প্রশ্নের জন্য ধন্যবাদ!" বলুন বলুন।
{context}
প্রশ্ন: {question}
উত্তর: """
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)
result = qa_chain({"query": question})
result["result"]
from langchain.chains import RetrievalQAWithSourcesChain
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(llm, retriever=vectorstore.as_retriever())
result = qa_chain({"question": question})
result
ব্লগ লিংক ভিত্তিক প্রশ্নের উত্তরের উপর ভিতিত হয়ে এআই এর উত্তর দেওয়া সম্বন্ধে আগের উদাহরণের উপর নির্ভর করে, প্রাপ্ত ফলাফলগুলি নিম্নলিখিত হতে পারে, যা আমাদেরকে দেখাতে দেয়, যে AI বিশেষ ব্লগ URL এর উপর ভিতিত প্রশ্নের উত্তর দিয়েছে:
{
'question': 'What are the methods for task decomposition?',
'answer': 'কাজের ডিকম্পোজিশনের জন্য পদ্ধতিগুলি মধ্যে (1) LLM এবং সহজ প্রম্পট ব্যবহার করা, (2) কাজের বিশেষ নির্দেশিকা ব্যবহার করা, এবং (3) এর মধ্যে মানুষের ইনপুট নেওয়া যায়।\n',
'sources': 'https://lilianweng.github.io/posts/2023-06-23-agent/'
}