Lokal bilgi tabanlı AI Soru-Cevap Örneği
Varsayalım ki bazı metin belgeleriniz (PDF'ler, bloglar, yerel özel veriler vb.) var ve yerel bir bilgi tabanı üzerine kurulu bir AI Soru-Cevap sohbet botu oluşturmak istiyorsunuz. Bu işlevselliği LangChain kullanarak kolayca uygulamak mümkündür. Aşağıda, LangChain kullanarak bu Soru-Cevap işlevselliğini nasıl başaracağınıza dair adım adım bir rehber bulunmaktadır.
- Not: Büyük dil modelinin (LLM) eğitim maliyetinin yüksek olması nedeniyle, büyük dil modelinin bilgi tabanı genellikle sıkça güncellenmez. Yapay zeka yalnızca eğitildiği içeriği bilir ve yeni içerik veya kurumsal/kişisel özel verilerden haberdar değildir. Bu nedenle, yerel bilgi tabanını büyük dil modeliyle birleştirmek gereklidir.
AI Soru-Cevap Süreci
-
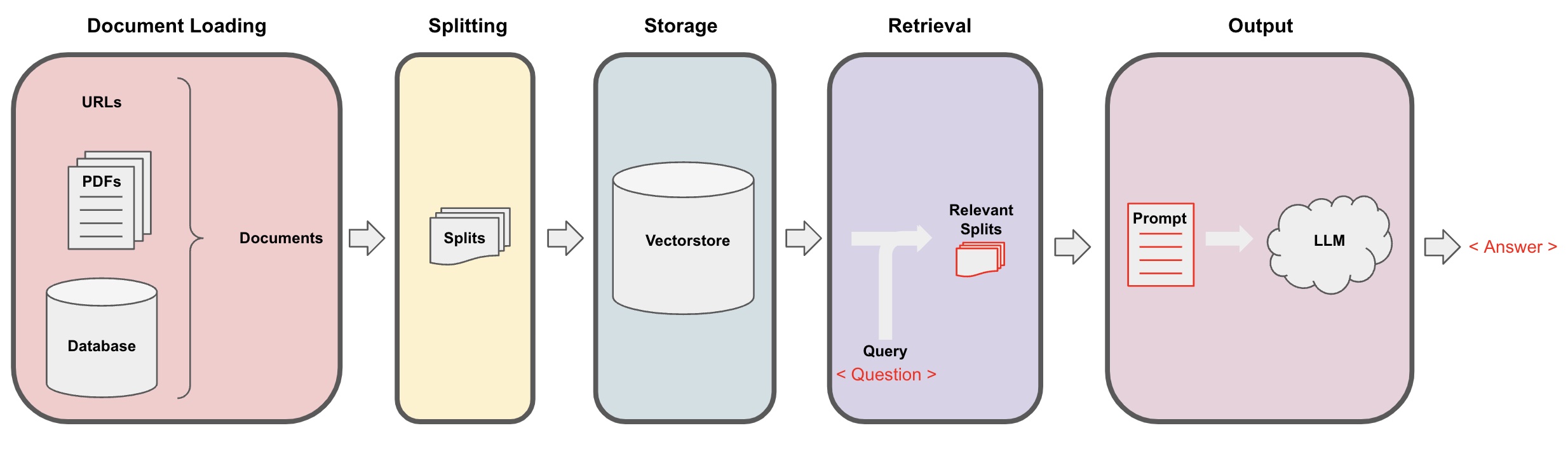
Belge yükleme: İlk olarak, yerel metin verilerimizi yüklememiz gerekiyor; bunu LangChain'in yükleyici bileşeni kullanılarak başarabiliriz. -
Belgeleri bölmek: LangChain'in metin böleyicisini kullanarak belgeleri belirli boyuttaki metin parçalarına böleriz. (Not: Metin bölme amacı, sorulara dayalı ilgili içerik parçalarını aramayı kolaylaştırmaktır. Bölme işleminin bir diğer nedeni, büyük dil modelinin maksimum belirteç sınırına sahip olmasıdır.) -
Depolama: Belgeleri böldükten sonra, gömme modelini kullanarak belge öznitelik vektörlerini hesaplayın ve ardından bunları bir vektör veritabanında saklayın. -
Gerçekleme: Soruya dayanarak vektör veritabanını sorgulayarak benzer belge parçalarını alın. -
Oluşturma: LangChain QA zincirini kullanarak Soru-Cevap yapmak için, belge parçalarını soruyla birlikte kendi tasarladığınız AI ipuçlarına birleştirin ve bunları LLM'ye ileterek soruyu cevaplamasını sağlayın. -
Konuşma(isteğe bağlı): QA zincirine Bellek bileşenini ekleyerek, çoklu dönemli Soru-Cevap diyaloglarını kolaylaştırmak için yapay zekanın tarihsel mesaj belleği işlevselliği ekleyebilirsiniz.
AI Soru-Cevap süreci aşağıdaki diyagramda gösterilmiştir:
Başlarken
Hızlı bir başlangıç yapmak için yukarıdaki süreç tek bir VectorstoreIndexCreator nesnesine sarılabilir. Diyelim ki bu blog yazısı üzerinde kurulu bir QA Soru-Cevap programı oluşturmak istiyoruz. Bunun için sadece birkaç kod satırı gereklidir:
- Not: Bu bölüm hala OpenAI'nin büyük dil modelini kullanmaktadır.
Öncelikle, ortam değişkenlerini ayarlayın ve gerekli paketleri yükleyin:
pip install openai chromadb
export OPENAI_API_KEY="..."
Ardından şunu çalıştırın:
from langchain_community.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
index = VectorstoreIndexCreator().from_loaders([loader])
Şimdi sorular sormaya başlayabiliriz:
index.query("Görev ayrıştırma nedir?")
Görev ayrıştırma, karmaşık görevleri daha küçük, basit adımlara bölmek için bir tekniktir. Basit ipuçları, görevle ilgili talimatlar veya insan girişi kullanılarak yapılabilir. Mindtrees (Yao et al.2023), her adımda birden fazla akıl yürütme olasılığını keşfeden ve her adımda birden fazla fikir üreten bir görev ayrıştırma tekniği örneğidir ve ağaç yapısı oluşturmak için kullanılır.
Program çalışıyor, peki bunun altında nasıl çalıştığını düşünelim. Süreci adım adım çözümleyelim.
Adım 1. Yükleme (Belge Verileri Yükleme)
Belirli bir DocumentLoader belirtin ve belirtilen verileri Documents nesnesine yükleyin. Document nesnesi, bir metin parçasını (sayfa_içeriği) ve ilgili meta verileri temsil eder.
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
veri = loader.yükle()
- Not: LangChain, farklı veri türlerini kolayca yüklemek için çeşitli yükleyiciler sağlar, bunlar önceki bölümlerde bulunabilir.
Adım 3. Depolama (Vektör Depolama)
Sorulara dayalı ilgili belge parçalarını sorgulamak için önceden bölünmüş belge parçalarının metin özellik vektörlerini hesaplamamız ve onları bir vektör veritabanında saklamamız gerekiyor.
Burada, Langchain tarafından sağlanan varsayılan "chroma" vektör veritabanını kullanıyoruz ve ardından openai yerleştirme modelini kullanıyoruz.
- Not: Gömme modeli olarak diğer açık kaynak modellerini tercih edebilirsiniz.
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
Adım 4. Getirme (İlgili Belge Sorgulama)
Soruyla ilgili belge parçalarını benzerlik aramasıyla getirin.
- Not: Bu adımın amacı, vektör veritabanının benzerlik arama işlevini göstermektir. Bu adımın işlevselliği, Langchain tarafından 5. adımda kapsüllenmiş olan Q&A zinciri içinde otomatik olarak bulunmaktadır.
question = "Görev ayrıştırmanın yöntemleri nelerdir?"
belgeler = vectorstore.similarity_search(question)
len(belgeler)
4
Adım 5. Oluşturma (Yapay Zeka Kullanarak Soruları Yanıtlama)
Getirilen belgeyi tek bir yanıt haline getirmek için LLM/Chat modeli (ör. gpt-3.5-turbo) ve RetrievalQA zincirini kullanın.
- İpucu:
RetrievalQA, yerel bir bilgi tabanına dayalı yapay zeka soru-cevaplamayı uygulayabilen LangChain tarafından kapsüllenmiş bir zincirdir.
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_zinciri = RetrievalQA.from_chain_type(llm, retriever=vectorstore.as_retriever())
qa_zinciri({"query": question})
{
'query': 'Görev ayrıştırmanın yöntemleri nelerdir?',
'result': 'Görev ayrıştırma yöntemleri şunları içerir:\n\n1. Basit İpucu: Bu yöntem, görevi daha küçük alt hedeflere ayrıştırmak için basit ipuçları veya sorular kullanır. Örneğin, ajan "XYZ için Adımlar" ile yönlendirilebilir ve XYZ'yi gerçekleştirmek için alt hedefleri listelemesi istenebilir.\n\n2. Göreve Özgü Talimatlar: Bu yöntemde, göreve özgü talimatlar, görevin ayrıştırma sürecini ajan için yönlendirmek amacıyla kullanılır. Örneğin, bir roman yazma görevi olduğunda, ajanın alt hedef olarak "Bir hikaye taslağı hazırlamak" talimatı verilebilir.\n\n3. İnsan Girişi: Bu yöntem, insan girişini görev ayrıştırma sürecine dahil eder. İnsanlar, karmaşık görevleri yönetilebilir alt hedeflere ayrıştırmak için rehberlik, geribildirim ve öneriler sağlarlar.\n\nBu yöntemler, karmaşık görevleri yönetilebilir parçalara ayrıştırarak etkin bir şekilde ele almaya yöneliktir.'
}
Unutmayın, "RetrievalQA" zincirine "LLM" veya "ChatModel"i iletebilirsiniz.
İpucu: Bu öğretici, LangChain'de yerleşik
RetrievalQAzincirini kullanarak bilgi tabanlı soru-cevaplamayı uygulamaktadır. Gerçekte, LangChain'in yeni sürümü için benzer bir soru-cevaplama zinciri özelleştirmek, LangChain Expression Language (LCEL) ifadelerini kullanarak kolaydır. İlgili bölüme bakınız.
Özel İpucu Şablonu
Daha önce RetrievalQA zincirini kullanırken bir ipucu kelimesi belirlemedik ve langchain'den yerleşik ipucu kelime şablonunu kullandık. Şimdi, ipucu kelime şablonunu özelleştirelim.
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
şablon ="""Bağlamın temel alındığı soruyu yanıtlayın.
Yanıtı bilmiyorsanız, "Bilmiyorum" deyin ve yanıtlamaya kalkışmayın.
Yanıt 3 cümle içinde olmalı ve kısa olmalı.
Yanıtın sonunda daima "Sorunuz için teşekkür ederim!" deyin.
{context}
Soru: {question}
Yanıt: """
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_zinciri = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)
sonuç = qa_zinciri({"query": question})
sonuç["result"]
AI Soru-Cevap Yanıtı için Referans
AI'nın cevaplarını hangi belgeye dayanarak verdiğini belirlemek için RetrievalQA yerine RetrievalQAWithSourcesChain kullanın.
from langchain.chains import RetrievalQAWithSourcesChain
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(llm, retriever=vectorstore.as_retriever())
result = qa_chain({"question": soru})
result
Blog bağlantılarına dayalı soruları yanıtlama örneğinden devam ederek, dönen sonuçlar aşağıdaki gibidir, böylece AI'nın belirli blog URL'sine dayanarak soruyu cevapladığını görebiliriz:
{
'question': 'Görev ayrıştırma için yöntemler nelerdir?',
'answer': 'Görev ayrıştırma yöntemleri arasında (1) LLM ve basit ipuçları kullanma, (2) görevle ilgili talimatları kullanma ve (3) içinde insan girişini dahil etme bulunur.\n',
'sources': 'https://lilianweng.github.io/posts/2023-06-23-agent/'
}