Пример вопросов и ответов на основе локальной базы знаний на основе ИИ
Предположим, у вас есть некоторые текстовые документы (PDF, блоги, локальные частные данные и т. д.) и вы хотите создать чат-бота Q&A на основе локальной базы знаний. Легко реализовать эту функциональность, используя LangChain. Ниже приведена пошаговая инструкция, как добиться этой функциональности Q&A, используя LangChain.
- Примечание: из-за высокой стоимости обучения крупной языковой модели, сама база знаний большой языковой модели не будет часто обновляться. И ИИ знает только содержимое, на котором он был обучен, и не знает о новом содержимом или личных данных предприятия/личных данных. Поэтому необходимо объединить локальную базу знаний с крупной языковой моделью.
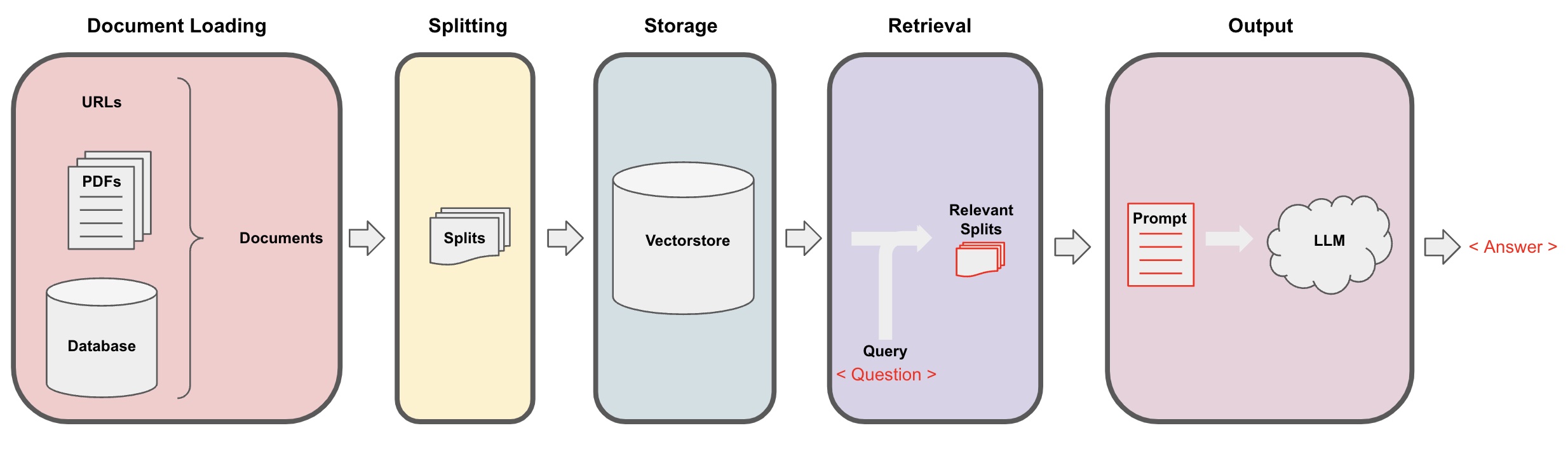
Процесс Q&A ИИ
-
Загрузка документов: Сначала нам нужно загрузить наши локальные текстовые данные, что можно сделать с помощью компонента загрузчика LangChain. -
Разделение документов: Используйте разделитель текста LangChain, чтобы разбить документы на заданные фрагменты текста заданного размера. (Примечание: цель разделения текста - облегчить поиск соответствующих фрагментов контента на основе вопросов. Еще одна причина разделения - максимальное количество токенов крупной языковой модели.) -
Хранение: После разделения документов вычислите векторы признаков документа с использованием модели вложения, а затем сохраните их в базе данных векторов. -
Поиск: На основе вопроса запросите базу данных векторов, чтобы извлечь похожие фрагменты документов. -
Создание: Используйте цепочку LangChain QA, чтобы выполнять Q&A, объедините фрагменты документов, относящиеся к вопросу, с самим вопросом в AI-подсказки, созданные вами, и передайте их в LLM, чтобы ответить на вопрос. -
Диалог(опционально): Добавив компонент памяти к цепочке QA, можно добавить функциональность памяти истории сообщений ИИ для облегчения многоходовых диалогов Q&A.
Процесс Q&A ИИ проиллюстрирован на следующей диаграмме:
Начало работы
Чтобы быстро начать, вышеуказанный процесс может быть обернут в один объект VectorstoreIndexCreator. Предположим, мы хотим создать программу QA Q&A на основе этого блог-поста. Это можно сделать с помощью всего нескольких строк кода:
- Примечание: в этой главе все еще используется крупная языковая модель OpenAI.
Сначала установите переменные окружения и установите необходимые пакеты:
pip install openai chromadb
export OPENAI_API_KEY="..."
Затем запустите:
from langchain_community.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
index = VectorstoreIndexCreator().from_loaders([loader])
Теперь начните задавать вопросы:
index.query("Что такое декомпозиция задачи?")
Декомпозиция задачи - это техника разбиения сложных задач на более мелкие, более простые шаги. Ее можно выполнить с помощью LLM с простыми подсказками, инструкциями, специфическими для задачи данными или вводом человека. Mindtrees (Yao et al.2023) - это пример техники декомпозиции задачи, которая исследует несколько возможностей рассуждения на каждом этапе и генерирует несколько идей на каждом шаге для создания структуры дерева.
Программа работает, но как это реализовано внутри? Давайте разберем процесс по шагам.
Шаг 1. Загрузка (Загрузка данных документа)
Укажите DocumentLoader для загрузки указанных данных в объект Documents. Объект Document представляет собой фрагмент текста (page_content) и соответствующие метаданные.
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
- Примечание: LangChain предоставляет различные загрузчики для удобной загрузки различных типов данных, на которые можно сослаться в предыдущих главах.
Шаг 2. Разделение (Разделение документов)
Поскольку у крупной модели есть максимальное количество токенов, которое мы не можем превысить, мы не можем передавать слишком много содержимого документов в ИИ. Обычно достаточно передать соответствующие фрагменты документов, поэтому здесь мы должны обработать срезы документов.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 0)
all_splits = text_splitter.split_documents(data)
Шаг 3. Хранение (Хранилище векторов)
Для того чтобы запрашивать соответствующие фрагменты документов на основе вопроса, нам необходимо посчитать векторы признаков текста для ранее разделенных фрагментов документов, используя модель встраивания, а затем сохранить их в векторной базе данных.
Здесь мы используем предоставленную по умолчанию векторную базу данных "chroma" от Langchain и затем используем открытую модель встраивания openai.
- Примечание: Вы также можете выбрать другие модели с открытым исходным кодом в качестве замены для модели встраивания.
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
Шаг 4. Извлечение (Запрос соответствующих документов)
Извлеките фрагменты документов, связанных с вопросом, с помощью поиска похожести.
- Примечание: Цель этого шага - продемонстрировать функцию поиска похожести в векторной базе данных. Функциональность этого шага автоматически включена в цепочку Q&A, инкапсулированную Langchain, в 5-м шаге.
question = "Какие существуют методы декомпозиции задачи?"
docs = vectorstore.similarity_search(question)
len(docs)
4
Шаг 5. Генерация (Использование ИИ для ответа на вопросы)
Используйте модель LLM/Chat (например, gpt-3.5-turbo) и цепочку RetrievalQA, чтобы сжать извлеченный документ в один ответ.
- Совет:
RetrievalQA- это цепочка, инкапсулированная LangChain, способная осуществлять ответы на вопросы с использованием локальной базы знаний.
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectorstore.as_retriever())
qa_chain({"query": question})
{
'query': 'Какие существуют методы декомпозиции задачи?',
'result': 'Методы декомпозиции задачи включают:\n\n1. Простые подсказки: Этот метод использует простые подсказки или вопросы, чтобы помочь агенту разбить задачу на более мелкие подцели. Например, агент может получить подсказку "Шаги для XYZ" и попросить перечислить подцели для достижения XYZ.\n\n2. Задача-специфические инструкции: В этом методе предоставляются задача-специфические инструкции для направления процесса декомпозиции для агента. Например, если задача состоит в написании романа, агенту может быть предписано "Составить обзор сюжета" в качестве подцели.\n\n3. Человеческий вклад: Этот метод включает в себя вовлечение человеческого вклада в процесс декомпозиции задачи. Люди могут предоставлять руководство, обратную связь и предложения, чтобы помочь агенту разбить сложные задачи на управляемые подцели.\n\nЭти методы направлены на эффективную обработку сложных задач путем их декомпозиции на более мелкие и управляемые части.'
}
Обратите внимание, что вы можете передать "LLM" или "ChatModel" в цепочку "RetrievalQA".
Совет: В этом руководстве используется встроенная цепочка
RetrievalQAв LangChain для реализации ответов на вопросы на основе базы знаний. На практике, для новой версии LangChain, с использованием языка выражений LangChain (LCEL), легко настроить аналогичную цепочку ответов на вопросы. Обратитесь к соответствующему разделу LCEL.
Пользовательский шаблон подсказки
При использовании ранее цепочки RetrievalQA мы не установили ключевое слово подсказки и использовали встроенный шаблон ключевого слова от langchain. Теперь давайте настроим пользовательский шаблон ключевого слова.
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
template ="""Ответьте на вопрос на основе нижеследующего контекста.
Если вы не знаете ответа, просто скажите "Я не знаю", и не пытайтесь придумать ответ.
Ответ должен быть в пределах 3 предложений, и он должен быть кратким.
В конце ответа всегда говорите "Спасибо за ваш вопрос!"
{context}
Вопрос: {question}
Ответ: """
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)
result = qa_chain({"query": question})
result["result"]
Ссылка для ответов на вопросы искусственного интеллекта
Для возврата ответов искусственного интеллекта на основе определенного документа используйте RetrievalQAWithSourcesChain вместо RetrievalQA.
from langchain.chains import RetrievalQAWithSourcesChain
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(llm, retriever=vectorstore.as_retriever())
result = qa_chain({"question": question})
result
На основе предыдущего примера ответов на вопросы на основе ссылок на блоги, возвращаемые результаты следующие, позволяя нам увидеть, что искусственный интеллект ответил на вопрос на основе конкретной ссылки на блог:
{
'question': 'Какие методы разложения задачи?',
'answer': 'Методы разложения задачи включают (1) использование LLM и простых подсказок, (2) использование инструкций, специфичных для задачи, и (3) вовлечение человеческого ввода в него.\n',
'sources': 'https://lilianweng.github.io/posts/2023-06-23-agent/'
}