Ejemplo de pregunta y respuesta de IA basada en una base de conocimientos local
Supongamos que tienes algunos documentos de texto (PDF, blogs, datos privados locales, etc.) y quieres crear un chatbot de pregunta y respuesta de IA basado en una base de conocimientos local. Es fácil implementar esta funcionalidad utilizando LangChain. A continuación se muestra una guía paso a paso sobre cómo lograr esta funcionalidad de pregunta y respuesta utilizando LangChain.
- Nota: Debido al alto costo de entrenamiento del LLM (modelo de lenguaje grande), la base de conocimientos del propio modelo de lenguaje grande no se actualizará con frecuencia. La IA solo conoce el contenido en el que ha sido entrenada y no tiene conocimiento de contenidos nuevos o de datos privados de empresas/personales, por lo que es necesario combinar la base de conocimientos local con el modelo de lenguaje grande.
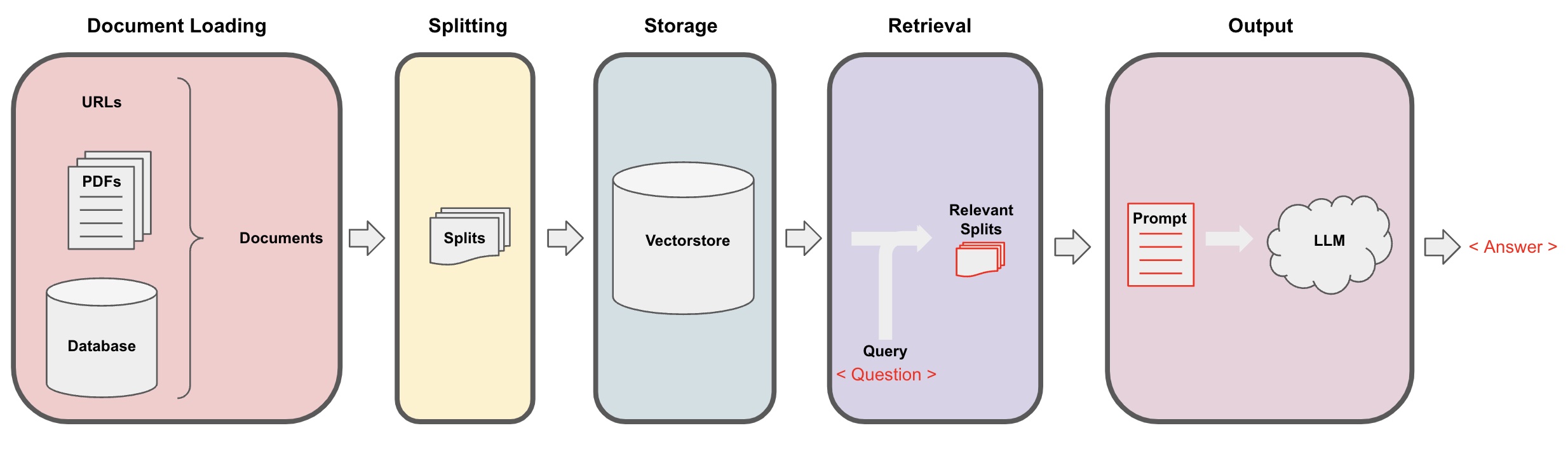
Proceso de pregunta y respuesta de IA
-
Carga de documentos: Primero, necesitamos cargar nuestros datos de texto locales, lo cual se puede lograr utilizando el componente de carga de LangChain. -
División de documentos: Utiliza el separador de texto de LangChain para segmentar los documentos en fragmentos de texto de tamaño especificado. (Nota: El propósito de la segmentación de texto es facilitar la búsqueda de fragmentos de contenido relevantes basados en las preguntas. Otra razón para la segmentación es que el modelo de lenguaje grande tiene un límite máximo de tokens.) -
Almacenamiento: Después de segmentar los documentos, calcula los vectores característicos del documento utilizando un modelo de incrustación y luego almacénalos en una base de datos de vectores. -
Recuperación: Basándose en la pregunta, consulta la base de datos de vectores para recuperar fragmentos de documentos similares. -
Generación: Utiliza la cadena de preguntas y respuestas de LangChain para realizar preguntas y respuestas, concatena los fragmentos de documentos relacionados con la pregunta con la pregunta misma en las indicaciones de IA diseñadas por ti, y pásalas al LLM para responder la pregunta. -
Conversación(opcional): Al agregar el componente de Memoria a la cadena de preguntas y respuestas, puedes agregar funcionalidad de memoria de mensajes históricos de AI para facilitar diálogos de preguntas y respuestas de múltiples turnos.
El proceso de pregunta y respuesta de IA se ilustra en el siguiente diagrama:
Empezar
Para comenzar rápidamente, el proceso anterior puede envolverse en un solo objeto VectorstoreIndexCreator. Supongamos que queremos crear un programa de pregunta y respuesta de IA basado en este post de blog. Esto se puede lograr con solo unas pocas líneas de código:
- Nota: Este capítulo todavía utiliza el modelo de lenguaje grande de OpenAI.
Primero, establece las variables de entorno e instala los paquetes requeridos:
pip install openai chromadb
export OPENAI_API_KEY="..."
Luego ejecuta:
from langchain_community.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
index = VectorstoreIndexCreator().from_loaders([loader])
Ahora, comienza a hacer preguntas:
index.query("¿Qué es la descomposición de tareas?")
La descomposición de tareas es una técnica para desglosar tareas complejas en pasos más pequeños y simples. Se puede hacer utilizando LLM con indicaciones simples, instrucciones específicas de la tarea o entrada humana. Mindtrees (Yao et al.2023) es un ejemplo de técnica de descomposición de tareas, que explora múltiples posibilidades de razonamiento en cada paso y genera múltiples ideas en cada paso para crear una estructura de árbol.
El programa está en ejecución, pero ¿cómo se implementa bajo el escenario? Analicemos el proceso paso a paso.
Paso 1. Cargar (Carga de datos de documentos)
Especifica un DocumentLoader para cargar los datos especificados en un objeto Documents. El objeto Document representa un fragmento de texto (page_content) y metadatos relacionados.
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
- Nota: Langchain proporciona varios cargadores para cargar de manera conveniente diferentes tipos de datos, que se pueden consultar en los capítulos anteriores.
Paso 2. División (División de documentos)
Debido a que los indicativos de modelos grandes tienen un límite máximo de tokens, no podemos pasar demasiado contenido de documentos a la IA. Por lo general, es suficiente pasar fragmentos de documentos relevantes, por lo que necesitamos procesar los cortes de documentos aquí.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 0)
all_splits = text_splitter.split_documents(data)
Paso 3. Almacenar (Almacenamiento de vectores)
Para consultar fragmentos de documentos relevantes basados en una pregunta, necesitamos calcular los vectores de características de texto para los fragmentos de documentos previamente divididos mediante un modelo de incrustación, y luego almacenarlos en una base de datos de vectores.
Aquí utilizamos la base de datos de vectores predeterminada "chroma" proporcionada por Langchain, y luego utilizamos el modelo de incrustación de openai.
- Nota: También puedes elegir otros modelos de código abierto como reemplazo para el modelo de incrustación.
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
Paso 4. Recuperar (Consultar documentos relevantes)
Recuperar fragmentos de documentos relacionados con la pregunta a través de una búsqueda de similitud.
- Nota: El propósito de este paso es demostrar la función de búsqueda de similitud de la base de datos de vectores. La funcionalidad de este paso se incluye automáticamente en la cadena de preguntas y respuestas encapsulada por Langchain en el quinto paso.
pregunta = "¿Cuáles son los métodos de descomposición de tareas?"
docs = vectorstore.similarity_search(pregunta)
len(docs)
4
Paso 5. Generar (Usar la inteligencia artificial para responder preguntas)
Utiliza el modelo LLM/Chat (por ejemplo, gpt-3.5-turbo) y la cadena RetrievalQA para condensar el documento recuperado en una sola respuesta.
- Consejo:
RetrievalQAes una cadena encapsulada por LangChain, capaz de implementar la respuesta a preguntas basada en una base de conocimientos local.
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectorstore.as_retriever())
qa_chain({"query": pregunta})
{
'query': '¿Cuáles son los métodos de descomposición de tareas?',
'result': 'Los métodos de descomposición de tareas incluyen:\n\n1. Indicaciones simples: Este método utiliza indicaciones simples o preguntas para guiar al agente en la descomposición de la tarea en submetas más pequeñas. Por ejemplo, al agente se le puede pedir: "Pasos para XYZ" con el fin de listar las submetas para lograr XYZ.\n\n2. Instrucciones específicas de la tarea: En este método, se proporcionan instrucciones específicas de la tarea para guiar el proceso de descomposición para el agente. Por ejemplo, si la tarea es escribir una novela, se le puede indicar al agente "Crear un esquema del argumento" como submeta.\n\n3. Aportación humana: Este método implica incorporar la aportación humana en el proceso de descomposición de tareas. Las personas pueden proporcionar orientación, retroalimentación y sugerencias para ayudar al agente a descomponer tareas complejas en submetas manejables.\n\nEstos métodos tienen como objetivo manejar eficientemente tareas complejas al descomponerlas en partes más pequeñas y manejables.'
}
Ten en cuenta que puedes pasar "LLM" o "ChatModel" a la cadena "RetrievalQA".
Consejo: Este tutorial utiliza la cadena integrada
RetrievalQAen LangChain para implementar la respuesta a preguntas basada en conocimientos. En realidad, para la nueva versión de LangChain, utilizando expresiones de lenguaje de expresión de LangChain (LCEL), es fácil personalizar una cadena similar de respuesta a preguntas. Consulta la sección relevante sobre LCEL.
Plantilla personalizada de indicaciones
Cuando usamos la cadena RetrievalQA anteriormente, no establecimos una palabra de indicación y utilizamos la plantilla de palabra de indicación integrada de langchain. Ahora, vamos a personalizar la plantilla de palabra de indicación.
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
template ="""Responde la pregunta basándote en el contexto a continuación.
Si no sabes la respuesta, simplemente di "No lo sé" y no intentes inventar una respuesta.
La respuesta debe tener un máximo de 3 oraciones y mantenerla concisa.
Siempre di "¡Gracias por tu pregunta!" al final de la respuesta.
{context}
Pregunta: {pregunta}
Respuesta: """
PLANTILLA_INDICACION_QA = PromptTemplate.from_template(template)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": PLANTILLA_INDICACION_QA}
)
resultado = qa_chain({"query": pregunta})
resultado["result"]
Referencia para la respuesta de preguntas y respuestas de IA
Utilice RetrievalQAWithSourcesChain en lugar de RetrievalQA para obtener las respuestas de IA basadas en qué documento.
from langchain.chains import RetrievalQAWithSourcesChain
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(llm, retriever=vectorstore.as_retriever())
result = qa_chain({"question": question})
result
Basándonos en el ejemplo anterior de responder preguntas basadas en enlaces de blogs, los resultados devueltos son los siguientes, lo que nos permite ver que la IA respondió a la pregunta basándose en la URL específica del blog:
{
'question': '¿Cuáles son los métodos para la descomposición de tareas?',
'answer': 'Los métodos para la descomposición de tareas incluyen (1) el uso de LLM y simples indicaciones, (2) el uso de instrucciones específicas de la tarea y (3) la participación de la entrada humana en ella.\n',
'sources': 'https://lilianweng.github.io/posts/2023-06-23-agent/'
}