مثالی از پرسش و پاسخ هوش مصنوعی بر اساس پایگاه دانش محلی
فرض کنید دارید تعدادی اسناد متنی (از قبیل پیدیاف، وبلاگها، دادههای خصوصی محلی و غیره) دارید و میخواهید یک چتبات هوش مصنوعی پرسش و پاسخ بر اساس یک پایگاه دانش محلی ایجاد کنید. ایجاد این قابلیت با استفاده از LangChain بسیار آسان است. در زیر راهنمای گام به گام برای دستیابی به این قابلیت پرسش و پاسخ با استفاده از LangChain آورده شده است.
- توجه: به دلیل هزینه بالای آموزش LLM (مدل زبان بزرگ)، پایگاه دانش مدل زبان بزرگ به طور مکرر به روز نخواهد شد. هوش مصنوعی تنها محتوایی را میشناسد که بر آن آموزش دیده است و از محتوای جدید یا دادههای خصوصی شرکت/شخصی آگاه نیست لذا ضروری است تا پایگاه دانش محلی را با مدل زبان بزرگ ترکیب کرد.
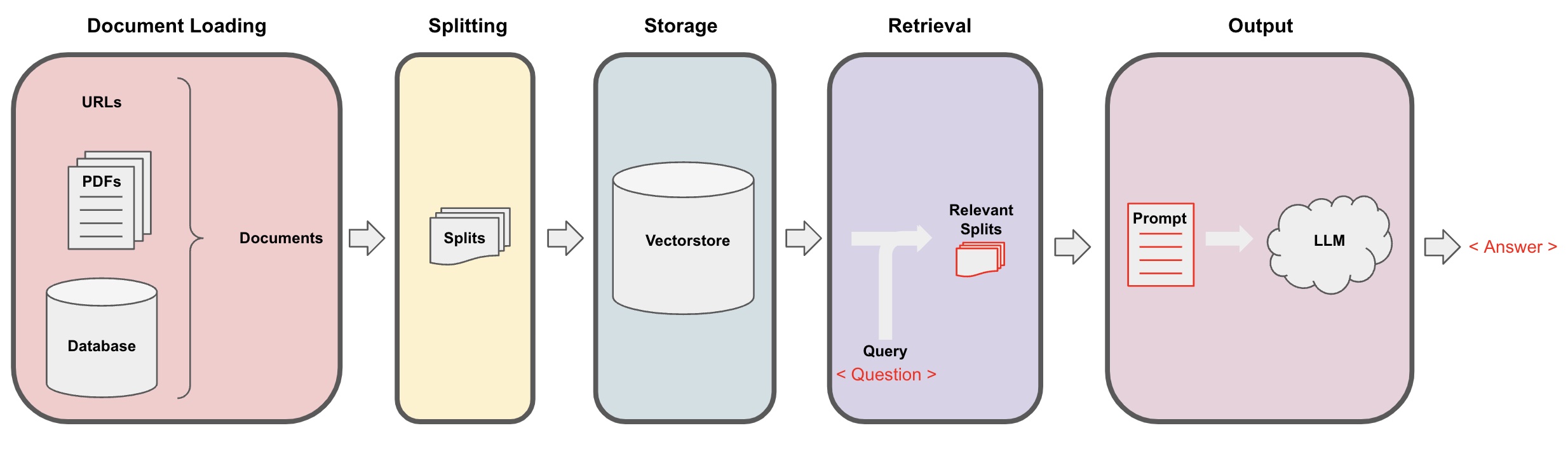
فرایند پرسش و پاسخ هوش مصنوعی
-
بارگذاری اسناد: در ابتدا، باید دادههای متنی محلی خود را بارگذاری کنیم که با استفاده از مؤلفه بارگذار LangChain قابل دستیابی است. -
تقسیم اسناد: از تقسیمکننده متن LangChain برای تقسیم اسناد به قطعات متن با اندازه مشخص استفاده کنید. (توجه: هدف از تقسیم متن، یافتن قطعات مرتبط با محتوای سوال بر اساس سوالات است. یک دلیل دیگر برای تقسیم این است که مدل زبان بزرگ محدودیت حداکثر توکن دارد.) -
ذخیرهسازی: پس از تقسیم اسناد، برداشت بردار ویژگی اسناد را با استفاده از یک مدل جانگاشت محاسبه کرده و سپس آنها را در یک پایگاه داده بردار ذخیره کنید. -
بازخوانی: بر اساس سوال، پایگاه داده بردار را جستجو کنید تا قطعات مشابه اسناد را بازیابی کنید. -
تولید: از زنجیره QA LangChain برای انجام پرسش و پاسخ استفاده کنید، قطعات اسناد مرتبط با سوال را با خود سوال ترکیب کرده و به عنوان سوالاتی طراحی شده توسط شما به LLM ارسال کنید تا به سوال پاسخ دهد. -
گفتگو(اختیاری): با اضافه کردن مؤلفه حافظه به زنجیره QA، میتوانید قابلیت حافظه پیام تاریخی هوش مصنوعی را اضافه کنید تا دیالوگهای چند دورهای پرسش و پاسخ را تسهیل کنید.
فرایند پرسش و پاسخ هوش مصنوعی در دیاگرام زیر نشان داده شده است:
شروع کردن
برای شروع سریع، فرآیند فوق را میتوان در یک شیء تک VectorstoreIndexCreator بستهبندی کرد. فرض کنید میخواهید یک برنامه پرسش و پاسخ QA بر اساس این وبلاگ ایجاد کنید. این کار با چند خط کد میتواند انجام شود:
- توجه: این فصل همچنان از مدل زبان بزرگ OpenAI استفاده میکند.
اولینبار متغیرهای محیطی را تنظیم کرده و پکیجهای مورد نیاز را نصب کنید:
pip install openai chromadb
export OPENAI_API_KEY="..."
سپس اجراکنید:
from langchain_community.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
index = VectorstoreIndexCreator().from_loaders([loader])
اکنون، شروع به پرسش سوالات کنید:
index.query("چیست تجزیهکاری وظایف؟")
تجزیهکاری وظایف یک تکنیک برای تجزیه وظایف پیچیده به قسمتهای کوچکتر و سادهتر است. این ممکن است با استفاده از LLM با امور مثل پرمپهای ساده، دستورات خاص و یا ورودی انسان انجام شود. Mindtrees (Yao et al.2023) نمونهای از تکنیک تجزیهکاری وظایف است که در هر مرحله به چندین احتمال استدلال میپردازد و ایدههای چندگانهای را در هر گام ایجاد میکند تا ساختار درختی را ایجاد کند.
برنامه در حال اجراست، اما چگونه زیرپوش پیادهسازی شده است؟ بیایید فرایند را گام به گام تجزیه کنیم.
گام 1. بارگذاری (بارگذاری دادههای سند)
یک DocumentLoader مشخص را برای بارگذاری دادههای مشخص به یک شیء Documents بارگذاری کنید. شیء Document یک قطعه متن (page_content) و اطلاعات مرتبط را نمایان میکند.
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
- توجه: LangChain انواع مختلفی از بارگذارها را برای بارگذاری آسان انواع مختلف دادهها فراهم میکند که میتوان به فصلهای قبلی مراجعه کرد.
گام 2. تقسیم (تقسیم اسناد)
زیرا پرمپهای مدل بزرگ محدودیت حداکثر توکن دارند و نمیتوانیم محتوای اسناد را زیادی به هوش مصنوعی منتقل کنیم، معمولاً کافی است که قطعات مرتبط اسناد را منتقل کنیم، بنابراین اینجا باید قطعات مستند را پردازش کنیم.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 0)
all_splits = text_splitter.split_documents(data)
مرحله ۳. ذخیرهسازی (ذخیرهسازی برداری)
برای پرسوجوی قطعات مرتبط با یک سوال، ما باید بردارهای ویژگی متن برای قطعات سند تقسیم شده قبلی را با استفاده از مدل جاسازی محاسبه کرده و سپس آنها را در یک پایگاه داده برداری ذخیره کنیم.
در اینجا ما از پایگاه داده برداری پیشفرض "کروما" ارائه شده توسط Langchain استفاده میکنیم، و سپس از مدل جاسازی openai استفاده میکنیم.
- توجه: شما همچنین میتوانید مدلهای منبع باز دیگر را به عنوان جایگزین برای مدل جاسازی انتخاب کنید.
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
مرحله ۴. بازیابی (جستجوی اسناد مرتبط)
اسناد مربوط به سوال را از طریق جستجوی شباهت بازیابی کنید.
- توجه: هدف این مرحله نشان دادن تابع جستجوی شباهت پایگاه داده برداری است. عملکرد این مرحله به صورت خودکار در گام پنجمی است که توسط Langchain در Q&A chain بستهبندی شده است.
question = "روشهای تجزیه و واکاوی کار چیست؟"
docs = vectorstore.similarity_search(question)
len(docs)
4
مرحله ۵. تولید (استفاده از هوش مصنوعی برای پاسخ به سوالات)
از مدل LLM/Chat (مانند gpt-3.5-turbo) و زنجیره RetrievalQA برای تقلیل اسناد بازیابی شده به یک پاسخ واحد استفاده کنید.
- نکته:
RetrievalQAیک زنجیره است که توسط LangChain بستهبندی شده و قادر به اجرای پرسش و پاسخ مبتنی بر دانش محلی است.
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectorstore.as_retriever())
qa_chain({"query": question})
{
'query': 'روشهای تجزیه و واکاوی کار چیست؟',
'result': 'روشهای تجزیه و واکاوی کار شامل:\n\n1. سوالات ساده: این روش از پرسشها یا سوالات ساده برای هدایت عامل در تجزیه واکاوی کار به اقسام کوچکتر استفاده میکند. به عنوان مثال، عامل میتواند با "گامهای XYZ" هدایت و خواسته شود تا اهداف زیرین برای دستیابی به XYZ را فهرست کند.\n\n2. دستورالعملهای وظیفهمحور: در این روش، دستورالعملهای وظیفهمحور برای هدایت فرآیند تجزیه برای عامل ارائه میشود. به عنوان مثال، اگر وظیفه نوشتن یک رمان باشد، عامل میتواند به عنوان وظیفهزمینه "طراحی یک طرح داستان" داده شود.\n\n3. ورودی انسانی: این روش شامل گنجاندن ورودی انسانی در فرآیند تجزیه واکاوی کار میشود. انسانها میتوانند راهنمایی، بازخورد و پیشنهادها را برای کمک به عامل در تجزیه کارهای پیچیده به قطعات مدیریتپذیر ارائه دهند.\n\nاین روشها به هدف مدیریت بهینه وظایف پیچیده با تجزیه آنها به قطعات کوچکتر و مدیریتپذیر هدفمند میپردازند.'
}
لطفا توجه داشته باشید که میتوانید "LLM" یا "ChatModel" را به زنجیره "RetrievalQA" بفرستید.
نکته: این آموزش از زنجیره
RetrievalQAداخلی در LangChain برای اجرای پرسش و پاسخ برمبنای دانش استفاده میکند. در واقعیت، برای نسخه جدید LangChain، با استفاده از بیانیههای زبان بیان LangChain (LCEL)، آسان است یک زنجیره پرسش و پاسخ مشابه را سفارشیسازی کنید. لطفا به بخش مربوطه درباره LCEL مراجعه کنید.
الگوی دلخواه سوال
وقتی از زنجیره RetrievalQA در مرحله قبل استفاده میکردیم، ما یک کلمه الگو تعیین نکردهایم و از الگوی کلمه داخلی langchain استفاده کردهایم. حالا بیایید الگوی کلمه را سفارشی کنیم.
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
template ="""پاسخ به سوال براساس زمینه زیر را ارائه دهید.
اگر پاسخ را نمیدانید، فقط بگویید "نمیدانم" و سعی نکنید یک پاسخ ساختگی ارائه دهید.
پاسخ باید حداکثر در 3 جمله باشد و خلاصه باشد.
در پایان پاسخ، همیشه "با تشکر از سوال شما!" را بگویید.
{context}
سوال: {question}
پاسخ: """
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)
result = qa_chain({"query": question})
result["result"]
مرجعی برای پاسخگویی به سوالات مرتبط با هوش مصنوعی
برای بازگرداندن پاسخهای هوش مصنوعی بر اساس اسناد مربوطه، از RetrievalQAWithSourcesChain به جای RetrievalQA استفاده کنید.
from langchain.chains import RetrievalQAWithSourcesChain
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(llm, retriever=vectorstore.as_retriever())
result = qa_chain({"question": question})
result
با توجه به مثال قبلی برای پاسخ دادن به سوالات بر اساس لینکهای وبلاگ، نتایج برگردانده شده به شکل زیر است که به ما امکان میدهد ببینیم که هوش مصنوعی با توجه به URL خاص وبلاگ، به سوال پاسخ داده است:
{
'question': 'روشهای تجزیه وظایف چیست؟',
'answer': 'روشهای مربوط به تجزیه وظایف شامل (1) استفاده از LLM و دستورالعملهای ساده، (2) استفاده از دستورالعملهای مخصوص وظایف، و (3) دخالت ورودی انسان در آن است.\n',
'sources': 'https://lilianweng.github.io/posts/2023-06-23-agent/'
}