Przykład AI Q&A opartego na lokalnej bazie wiedzy
Załóżmy, że masz pewne dokumenty tekstowe (PDF-y, blogi, lokalne prywatne dane itp.) i chcesz stworzyć chatbota AI Q&A opartego na lokalnej bazie wiedzy. Łatwo zaimplementować tę funkcjonalność przy użyciu LangChain. Poniżej znajdziesz krok po kroku, jak osiągnąć tę funkcjonalność Q&A, korzystając z LangChain.
- Uwaga: Ze względu na wysoki koszt szkolenia modelu językowego LLM (Large Language Model), sama baza wiedzy dużego modelu językowego nie będzie często aktualizowana. AI zna tylko treści, na których była szkolona i nie ma świadomości nowych treści ani danych prywatnych przedsiębiorstwa/osobistej. Dlatego konieczne jest połączenie lokalnej bazy wiedzy z dużym modelem językowym.
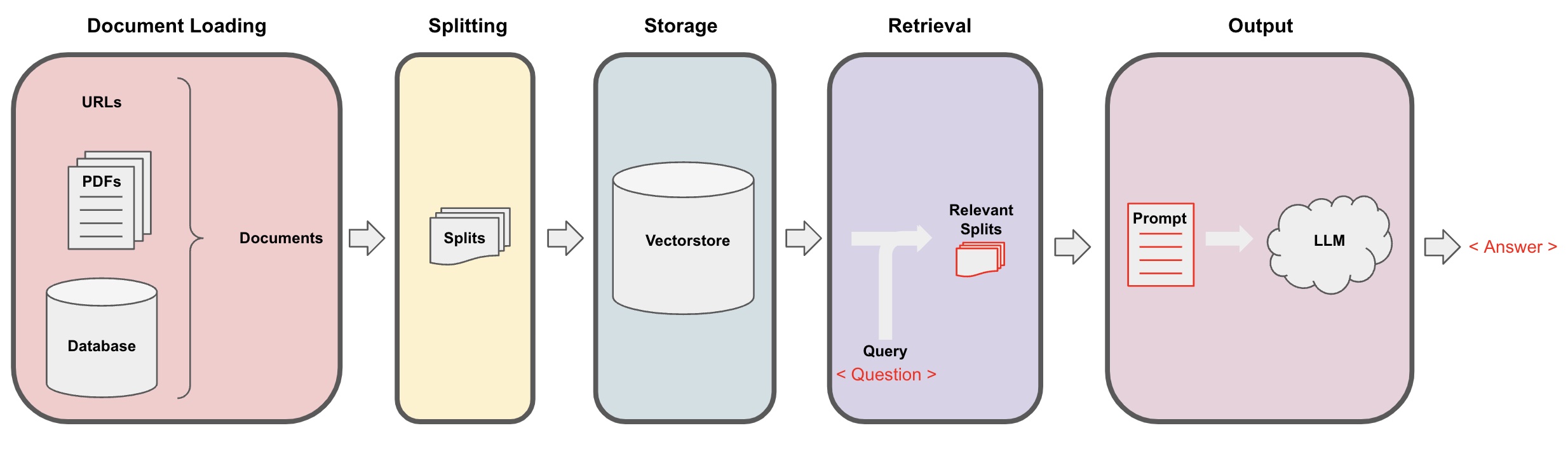
Proces AI Q&A
-
Ładowanie dokumentów: Najpierw musimy załadować nasze lokalne dane tekstowe, co można osiągnąć przy użyciu komponentu wczytywania w LangChain. -
Dzielenie dokumentów: Użyj splittera tekstu LangChain do podzielenia dokumentów na określone fragmenty tekstu o zadanych rozmiarach. (Uwaga: Celem segmentacji tekstu jest ułatwienie wyszukiwania odpowiednich fragmentów treści na podstawie pytań. Innym powodem segmentacji jest to, że duży model językowy ma maksymalny limit tokenów.) -
Przechowywanie: Po podzieleniu dokumentów oblicz wektory cech dokumentów za pomocą modelu osadzającego, a następnie przechowuj je w bazie danych wektorów. -
Pobieranie: Na podstawie pytania zapytaj bazę danych wektorów, aby pobrać podobne fragmenty dokumentów. -
Generowanie: Użyj łańcucha QA LangChain do wykonania Q&A, połącz fragmenty dokumentów związane z pytaniem z samym pytaniem w formie podpowiedzi AI zaprojektowanej przez ciebie i przekaż je do LLM, aby odpowiedzieć na pytanie. -
Rozmowa(opcjonalnie): Dodając komponent Memory do łańcucha QA, możesz dodać funkcjonalność pamięci historycznych wiadomości AI, aby ułatwić prowadzenie wielokrotnej rozmowy w trybie pytanie-odpowiedź.
Proces Q&A AI jest zobrazowany na poniższym diagramie:
Rozpoczęcie pracy
Aby szybko rozpocząć, powyższy proces można zawinąć w pojedynczy obiekt VectorstoreIndexCreator. Załóżmy, że chcemy stworzyć program Q&A oparty na tej publikacji na blogu zaledwie kilkoma linijkami kodu:
- Uwaga: Ten rozdział nadal wykorzystuje duży model językowy OpenAI.
Najpierw ustaw zmienne środowiskowe i zainstaluj wymagane paczki:
pip install openai chromadb
export OPENAI_API_KEY="..."
Następnie uruchom:
from langchain_community.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
index = VectorstoreIndexCreator().from_loaders([loader])
Teraz możesz zacząć zadawać pytania:
index.query("Co to jest dekompozycja zadania?")
Dekompozycja zadania to technika rozłożenia złożonych zadań na mniejsze, prostsze kroki. Można to zrobić za pomocą LLM z prostymi poleceniami, instrukcjami specyficznymi dla zadania lub wejściem człowieka. Przykładem techniki dekompozycji zadań jest Mindtrees (Yao et al.2023), która bada wiele możliwości rozumowania na każdym kroku i generuje wiele pomysłów na każdym kroku, tworząc strukturę drzewa.
Program działa, ale jak jest zaimplementowany od podszewki? Przeanalizujmy proces krok po kroku.
Krok 1. Wczytywanie (Ładowanie danych dokumentu)
Określ DocumentLoader, aby załadować określone dane do obiektu Documents. Obiekt Document reprezentuje kawałek tekstu (page_content) i powiązane metadane.
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
- Uwaga: Langchain dostarcza różne loadery do wygodnego wczytywania różnych typów danych, które można znaleźć w poprzednich rozdziałach.
Krok 2. Podział (Dzielenie dokumentów)
Ponieważ długie modele mają maksymalny limit tokenów, nie możemy przekazywać zbyt dużo treści dokumentu do AI. Zazwyczaj wystarczy przekazać odpowiednie fragmenty dokumentów, dlatego tutaj musimy przetworzyć fragmenty dokumentów.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(data)
Krok 3. Przechowywanie (Magazynowanie wektorów)
Aby móc wyszukiwać odpowiednie fragmenty dokumentów na podstawie pytania, musimy obliczyć wektory cech tekstu dla wcześniej podzielonych fragmentów dokumentów za pomocą modelu osadzeń, a następnie przechować je w bazie danych wektorowej.
Tutaj korzystamy z domyślnej bazy danych wektorowej "chroma" dostarczonej przez Langchain, a następnie używamy modelu osadzeń openai.
- Uwaga: Możesz również wybrać inne modele o otwartym kodzie jako zamiennik modelu osadzeń.
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
Krok 4. Odzyskiwanie (Wyszukiwanie odpowiednich dokumentów)
Znajdywanie fragmentów dokumentów związanych z pytaniem poprzez wyszukiwanie podobieństw.
- Uwaga: Celem tego kroku jest zademonstrowanie funkcji wyszukiwania podobieństw w bazie danych wektorowej. Funkcjonalność tego kroku automatycznie jest zawarta w łańcuchu Q&A opracowanym przez Langchain w 5. kroku.
question = "Jakie są metody dekompozycji zadań?"
docs = vectorstore.similarity_search(question)
len(docs)
4
Krok 5. Generowanie (Użycie sztucznej inteligencji do odpowiadania na pytania)
Wykorzystaj model LLM/Chat (np. gpt-3.5-turbo) oraz łańcuch RetrievalQA do skondensowania odzyskanego dokumentu w pojedynczą odpowiedź.
- Wskazówka:
RetrievalQAto łańcuch opracowany przez LangChain, zdolny do implementacji sztucznej inteligencji odpowiadającej na pytania na podstawie lokalnej bazy wiedzy.
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectorstore.as_retriever())
qa_chain({"query": question})
{
'query': 'Jakie są metody dekompozycji zadań?',
'result': 'Metody dekompozycji zadań obejmują:\n\n1. Proste wskazówki: Ta metoda wykorzystuje proste wskazówki lub pytania, aby przewodniczyć agentowi w dekompozycji zadania na mniejsze cele pośrednie. Na przykład agentowi można podać „Kroki do wykonania XYZ” i poprosić o wymienienie podcelów do osiągnięcia XYZ.\n\n2. Instrukcje zadania-specyficzne: W tej metodzie udziela się agentowi instrukcji zadania-specyficznych, aby przewodniczyć procesowi dekompozycji. Na przykład, jeśli zadaniem jest napisanie powieści, agentowi można zlecić "Napisanie planu fabuły" jako podcel.\n\n3. Wprowadzenie ludzkiej interakcji: Ta metoda polega na włączeniu interakcji ludzkiej w proces dekompozycji zadania. Ludzie mogą udzielać wskazówek, opinii i sugestii, aby pomóc agentowi w rozłożeniu złożonych zadań na bardziej zarządzalne podcele.\n\nTe metody mają na celu efektywne radzenie sobie z złożonymi zadaniami poprzez dekompozycję ich na mniejsze, bardziej zarządzalne części.'
}
Zauważ, że możesz przekazać "LLM" lub "Model czatu" do łańcucha "RetrievalQA".
Wskazówka: W tym samouczku wykorzystano wbudowany łańcuch
RetrievalQAw LangChain do implementacji odpowiadania na pytania opartej na wiedzy. W rzeczywistości, dla nowej wersji LangChain, korzystanie z wyrażeń LangChain Expression Language (LCEL) umożliwia łatwe dostosowanie łańcucha odpowiadania na podobne pytania. Proszę odnieść się do odpowiedniej sekcji na temat LCEL.
Niestandardowy szablon podpowiedzi
Podczas wcześniejszego korzystania z łańcucha RetrievalQA nie ustawiliśmy słowa kluczowego i korzystaliśmy z wbudowanego szablonu słowa kluczowego z langchain. Teraz dostosujmy szablon słowa kluczowego.
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
template ="""Odpowiedz na pytanie na podstawie poniższego kontekstu.
Jeśli nie znasz odpowiedzi, po prostu powiedz "Nie wiem" i nie próbuj zmyślać odpowiedzi.
Odpowiedź powinna zawierać się w 3 zdaniach, bądź zwięzły.
Zawsze powiedz na końcu "Dziękuję za pytanie!".
{context}
Pytanie: {question}
Odpowiedź: """
SZABLON_PROMPT_CHAIN_QA = PromptTemplate.from_template(template)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": SZABLON_PROMPT_CHAIN_QA}
)
wynik = qa_chain({"query": question})
wynik["result"]
Odwołanie do odpowiedzi na pytania dotyczące sztucznej inteligencji
Użyj RetrievalQAWithSourcesChain zamiast RetrievalQA, aby zwrócić odpowiedzi sztucznej inteligencji oparte na którym dokumencie.
from langchain.chains import RetrievalQAWithSourcesChain
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(llm, retriever=vectorstore.as_retriever())
result = qa_chain({"question": pytanie})
result
Kontynuując poprzedni przykład odpowiedzi na pytania oparte na linkach do blogów, zwrócone wyniki są następujące, pozwalając nam zobaczyć, że sztuczna inteligencja odpowiedziała na pytanie opierając się na konkretnym adresie URL bloga:
{
'question': 'Jakie są metody dekompozycji zadań?',
'answer': 'Metody dekompozycji zadań obejmują (1) użycie LLM i prostych poleceń, (2) użycie instrukcji specyficznych dla zadania oraz (3) zaangażowanie ludzkiego wkładu w to.\n',
'sources': 'https://lilianweng.github.io/posts/2023-06-23-agent/'
}