مقامی علم و معلومات تصنیف کی مثال
کسی مواد (پی ڈی ایف، بلاگز، مقامی خصوصی ڈیٹا وغیرہ) کے متن تصویرات ہیں اور آپ ایک مقامی علم اور معلومات پر مشتمل AI سوال و جواب چیٹ بٹ بسانا چاہتے ہیں۔ اس کام کو لانگچین کی مدد سے پانے کی عملیات بہت آسان ہے۔ نیچے دی گئی ہدایت نامہ خود بابت لانگچین کی مدد سے یہ Q & A کامیابی حاصل کرنے کے لئے صفحے ضرور دیکھیں۔
- نوٹ: بڑے زبان ماڈل (LLM) کی تشویشناک قیمتی کی وجہ سے، بڑے زبان ماڈل کی معلوماتی بیس خود میں عموماً تازہ کرنے کی کمی کی بنا پر نہیں برکرتی۔ AI صرف اُس مواد کو جانتا ہے جس پر اُس کی ٹریننگ ہوئی ہے اور نیا مواد یا کسی شخصی خصوصی ڈیٹا یا سیکریٹ مواد کے بارے میں علم نہیں رکھتا، اس لئے مقامی علم و معلومات کو بڑے زبان ماڈل کے ساتھ ملا لینا ضروری ہوتا ہے۔
AI سوال و جواب کارروائی
-
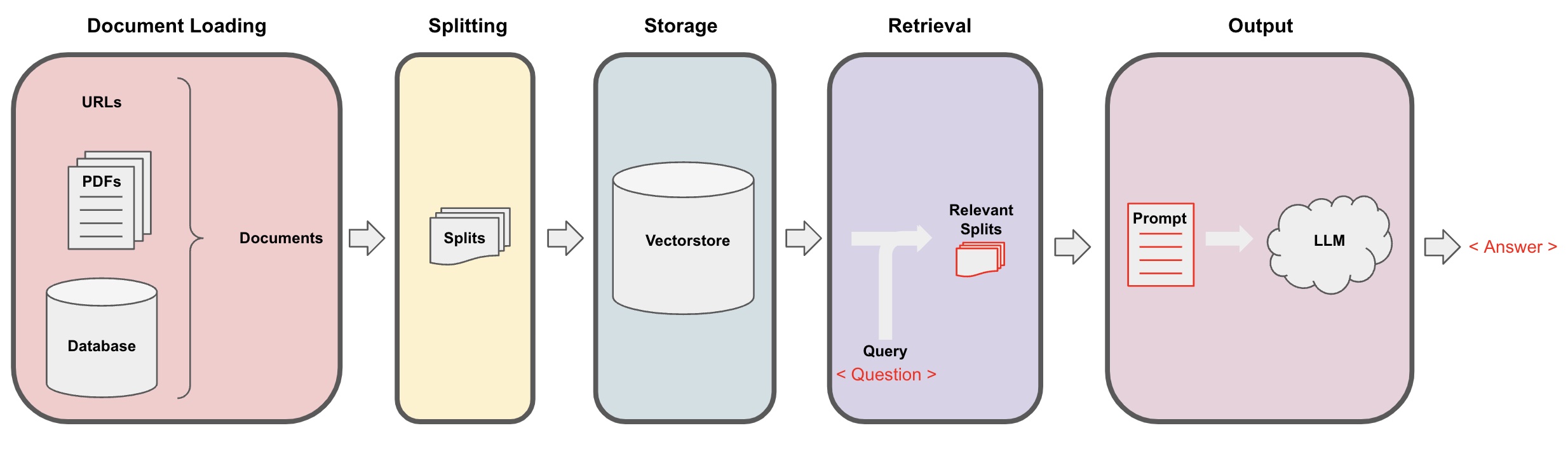
دستاویز کی لوڈنگ: پہلے، ہمیں اپنے مقامی مواد کو لوڈ کرنا ہو گا، جس کو لانگچین کے لوڈر کے ترکیب سے حاصل کیا جا سکتا ہے۔ -
دستاویز کوٹھوں میں تقسیم کرنا: لانگچین کے ٹیکسٹ اسپلٹر کا استعمال کریں تاکہ دستاویز کو مخصوص سائز کے ٹیکسٹ ٹکڑوں میں تقسیم کیا جا سکے۔ (نوٹ: ٹیکسٹ ٹکڑوں میں تقسیم کا مقصد سوالات کے مطابقتی مواد کے تلاش کو آسان بنانا ہے۔ تقسیم کا ایک اور مقصد یہ ہے کہ بڑے زبان ماڈل میں زیادہ سے زیادہ ٹوکن لاک ہے۔) -
ذخیرہ: دستاویز کو کوٹھوں میں تقسیم کرنے کے بعد، ایمبیڈنگ ماڈل کا استعمال کرتے ہوئے دستاویز کی خصوصیت سیاریاں حاصل کریں اور پھر انہیں ویکٹر ڈیٹا بیس میں ذخیرہ کریں۔ -
بازیابی: سوال کے مطابق، ویکٹر ڈیٹا بیس سے مشابہ دستاویز کے ٹکڑے بازیابی کرنے کے لیے سوال کریں۔ -
تخلیق: لانگچین کے QA چین کا استعمال کریں تاکہ Q&A کریں، سوال کے متعلق دستاویز کے ٹکڑے کو سوال کے ساتھ ملا کر آپ کی طرف سے ڈیزائن کی گئی AIپیشگوئیوں میں شامل کریں اور انہیں LLM کو پاس کریں تاکہ وہ سوال کا جواب دے۔ -
بات چیت(اختیاری): QA چین میں میموری کمپوننٹ شامل کرکے، آپ ملٹی-ٹرن Q&A ڈائیلاگ فیسلیٹیٹ کرنے کے لئے AI تاریخی پیغام یاد رکھنے کی کارروائی کرسکتے ہیں۔
AI سوال و جواب کارروائی کو مندرجہ ذیل خاکہ میں دکھایا گیا ہے:
شروع ہونا
تیزی سے شروع کرنے کے لئے، مندرجہ بالا کام کو ایک ہی اجزاء "ویکٹرسٹور انڈیکس کریئٹر" میں پیش کیا جا سکتا ہے۔ کہنے کے لئے ہم اس بلاگ پوسٹ پر مبنی ایک QA پروگرام بنانا چاہتے ہیں۔ چند لائن کوڈ کے ذریعے یہ کام کرسکتا ہے:
- نوٹ: یہ باب بھی ابھی بھی اوپن اے آئی کے بڑے زبان ماڈل کا استعمال کرتا ہے۔
پہلے، ماحولیاتی متغیرات سیٹ کریں اور مطلوبہ پیکیجز انسٹال کریں:
pip install openai chromadb
export OPENAI_API_KEY="..."
پھر چلائیں:
from langchain_community.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
index = VectorstoreIndexCreator().from_loaders([loader])
اب سوالات پوچھیں:
index.query("What is task decomposition?")
Task decomposition is a technique to break down complex tasks into smaller, simpler steps. It can be done using LLM with simple prompts, task-specific instructions, or human input. Mindtrees (Yao et al.2023) is an example of task decomposition technique, which explores multiple reasoning possibilities at each step and generates multiple ideas at each step to create a tree structure.
پروگرام چل رہا ہے، لیکن اس کو ہوڈ کے نیچے کیسے پیش کیا گیا ہے؟ چلتے ہیں اس پروسیس کو قدم با قدم شکنیں۔
قدم 1. لوڈ کریں (دستاویز ڈیٹا کی لوڈنگ)
DocumentLoader کو مخصوص ڈیٹا لوڈ کرنے کے لئے Documents آبجیکٹ میں دستاویز کو لوڈ کریں۔ Document آبجیکٹ متن (page_content) اور متعلقہ میٹا ڈیٹا کا مظاہرہ کرتا ہے۔
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
- نوٹ: لانگچین مختلف قسم کے ڈیٹا کو آسانی سے لوڈ کرنے کے لئے مختلف لوڈر فراہم کرتا ہے، جو پچھلے بابوں میں دیکھے جا سکتے ہیں۔
قدم 2. (دستاویز کوٹھوں میں تقسیم کرنا)
بڑے ماڈل پرومپٹ میں زیادہ سے زیادہ ٹوکن کی حد ہوتی ہے، ہم زیادہ سے زیادہ دستاویز مواد AI کو منتقل نہیں کر سکتے۔ عموماً موضوعات کے متعلق دستاویز ٹکڑے منتقل کرنا کافی ہوتا ہے، لہذا ہمیں یہاں دستاویز کے ٹکڑے پروسیس کرنے کی ضرورت ہے۔
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 0)
all_splits = text_splitter.split_documents(data)
مرحلہ 3. ذخیرہ کریں (ورکٹر ذخیرہ)
سوال کے مطابقت سے متعلق دستاویز کے ٹکڑوں کو دریافت کرنے کے لئے ہمیں پہلے سے تقسیم شدہ دستاویز کے متنی خصوصیات کا ویکٹر ڈیٹا بیس میں حساب لگانے کی ضرورت ہوتی ہے، اور پھر انہیں اس میں ذخیرہ کرنا پڑتا ہے۔
یہاں ہم لینگچین کی طرف سے فراہم کردہ ڈیفالٹ ویکٹر ڈیٹا بیس "کروما" کا استعمال کرتے ہیں، اور پھر اوپن اے آئی ایمبیڈنگ ماڈل کا استعمال کرتے ہیں۔
- نوٹ: آپ اس کے علاوہ دوسرے کھولے سورس ماڈلز کا بھی اندراج کرنے کے لئے ایمبیڈنگ ماڈل کی جگہ منتخب کر سکتے ہیں۔
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
مرحلہ 4. دریافت (متعلقہ دستاویز کا سوال کریں)
سوال کے ذریعے متعلقہ دستاویز کے ٹکڑے دریافت کریں۔
- نوٹ: اس مرحلے کا مقصد ویکٹر ڈیٹا بیس کی مماثلت تلاش کی کارروائی کو ظاہر کرنا ہے۔ اس مرحلے کی کارکردگی لینگچین میں 5 ویں مرحلہ میں Langchain کی طرف سے بندھا ہے۔
question = "ٹاسک کی تجزیے کے کیا طریقے ہیں؟"
docs = vectorstore.similarity_search(question)
len(docs)
4
مرحلہ 5. پیدا کریں (سوالات کا جواب دینے کے لئے اے آئی استعمال کریں)
لینگ ای یل / چیٹ ماڈل (مثلاً gpt-3.5-turbo) اور ریٹریوالکیوای چین کا استعمال کرتے ہوئے حاصل کردہ دستاویز کو ایک جواب میں مختصر کریں۔
- ٹپ:
ریٹریوالکیوایایک چین ہے جو لینگ چین نے بندھایا ہے، جو مقامی علمی بیس پر مبنی ای اےئ سوال جواب دینے کی کارکردگی کو نافذ کرنے کی صلاحیت رکھتا ہے۔
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectorstore.as_retriever())
qa_chain({"query": question})
{
'query': 'ٹاسک کی تجزیے کے کیا طریقے ہیں؟',
'result': 'ٹاسک کی تجزیے کے طریقے میں شامل ہیں:\n\n1. آسان پرومپٹس: یہ طریقہ سادہ پرومپٹس یا سوالات استعمال کرتا ہے تاکہ ایجنٹ کو تسک کو چھوٹے سے چھوٹے سب-مقاصد میں تقسیم کرنے کے لئے ہدایت مل سکے۔ مثال کے طور پر، ایجنٹ کو "XYZ کے لئے مراحل" کے ساتھ متعلق سوال کی ہدایت دی جا سکتی ہے اور کہا جا سکتا ہے کہ XYZ حاصل کرنے کے لئے سب-مقاصد کی فہرست بنائی جائے۔\n\n2. ٹاسک-مخصوص ہدایات: اس طریقہ میں، ٹاسک-مخصوص ہدایات فراہم کی جاتی ہیں جو ایجنٹ کو تسک کے تجزیے کی عمل کاری میں ہدایت دینے کے لئے استعمال کی جاتی ہیں۔ مثلاً، اگر تسک یہ ہے کہ ایک ناول لکھنا ہے، تو ایجنٹ کو ہدایت دی جا سکتی ہے کہ "ایک کہانی کی خاکہ تیار کریں" جیسا ایک سب-مقصد۔\n\n3. انسانی ان پٹ: یہ طریقہ تسک کے تجزیے کی عمل کاری میں انسانی ان پٹ کو شامل کرنے کی تھا، انسان ایجنٹ کو ہدایات، واپسی اور سفارشات فراہم کر سکتے ہیں تاکہ بڑے تسک کو قابل انتظام سب-مقاصد میں تقسیم کیا جا سکے۔\n\nیہ تراکیب مختصر سے مختصر تسکوں کو قابو کرنے کیلئے بنائی گئی ہیں۔'
}
نوٹ کریں کہ آپ "LLM" یا "ChatModel" کو "RetrieveQA" چین کو منتقل کر سکتے ہیں۔
ٹپ: یہ وہ زبانیں استعمال کرتی ہے جو LangChain Expression Language (LCEL)، کے لئے آسانی کے ساتھ مشابہت رکھتی ہیں، اور هاقایٔق کے لطافے کے لئے، ایک مشابہ سوال جواب چین کو کسٹمائز کرنا آسان ہے۔ مہربانی کرکے متعلقہ حصے پر LCEL میں موجودہ سیکشن سے رجوع کریں۔
کسٹم پرومپٹ ٹیمپلیٹ
جب ہم پہلے "RetrievalQA" چین کا استعمال کر رہے تے، تو ہم نے ایک پرومپٹ لفظ تعین نہیں کیا اور لینگچین کے ترتیب شدہ پرومپٹ ورڈ ٹیمپلیٹ کا استعمال کیا۔ اب ہم اس پرومپٹ ورڈ ٹیمپلیٹ کو اپنی مرضی کے مطابق ترتیب دیں۔
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
template ="""سوال کا جواب مندرجہ ذیل سیاق و سباق پر مبنی کریں۔
اگر آپ جواب نہیں جانتے تو بس "مجھے معلوم نہیں" کہہ دیں، اور جواب جعلی نہیں دینے کی کوشش کریں۔
جواب 3 جملوں کے اندر ہونا چاہئے، اور یہ مختصر رکھیں۔
ہر صورت میں جواب کے آخر میں "آپ کے سوال کا شکریہ!" کہیں۔
{context}
سوال: {question}
جواب: """
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)
result = qa_chain({"query": question})
result["result"]
from langchain.chains import RetrievalQAWithSourcesChain
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(llm, retriever=vectorstore.as_retriever())
result = qa_chain({"question": question})
result
پچھلے مثال پر مبنی ہوکر بلاگ لنکس کی بنیاد پر سوالات کے جواب بیان کرنے کے، واپسی نتائج مندرجہ ذیل ہیں، ہمیں یہ دیکھنے کی اجازت دیتی ہے کہ اے آئی مخصوص بلاگ یو آر ایل پر مبنی سوال کا جواب دیتا ہے:
{
'question': 'What are the methods for task decomposition?',
'answer': 'ہم تہریک کی تراکیب میں شامل (1) LLM اور سادہ پرامپٹ استعمال کرنا، (2) ٹاسک کے خود مخصوص ہدایات کا استعمال کرنا، اور (3) اس کے اندر انسانی ان پٹ کرنا شامل ہے۔\n',
'sources': 'https://lilianweng.github.io/posts/2023-06-23-agent/'
}