مثال على أسئلة وأجوبة للذكاء الاصطناعي بناءً على قاعدة معرفية محلية
لنفترض أن لديك بعض المستندات النصية (ملفات PDF، مدونات، بيانات خاصة محلية، الخ) وترغب في إنشاء دردشة ذكاء اصطناعي (AI Q&A) بناءً على قاعدة معرفية محلية. من السهل تنفيذ هذه الوظيفة باستخدام LangChain. أدناه دليل خطوة بخطوة حول كيفية تحقيق هذه الوظيفة Q&A باستخدام LangChain.
- ملاحظة: نظرًا لتكلفة تدريب وحدة اللغة الكبيرة (LLM) ، فإن قاعدة المعرفة للنموذج اللغوي الكبير نفسه لن تتم تحديثها بشكل متكرر. الذكاء الاصطناعي يعرف فقط المحتوى الذي تم تدريبه عليه ولا يدرك المحتوى الجديد أو بيانات الشركات/الأفراد الخاصة، لذا من الضروري دمج قاعدة المعرفة المحلية مع النموذج اللغوي الكبير.
عملية الأسئلة والأجوبة بالذكاء الاصطناعي
-
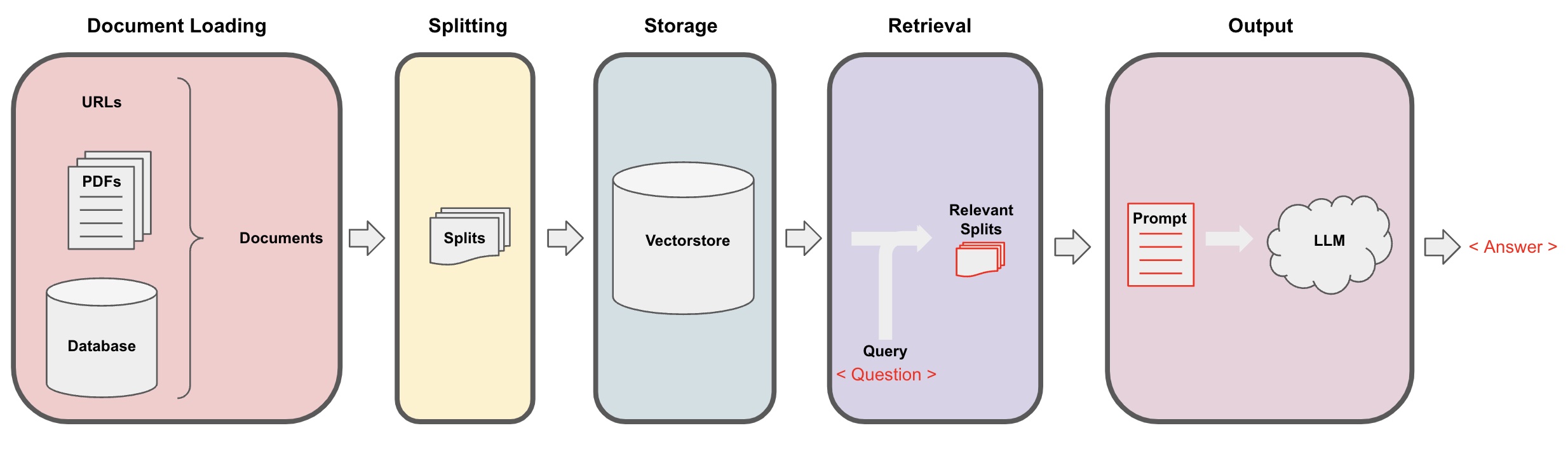
تحميل المستندات: أولاً، نحتاج إلى تحميل بيانات النصوص المحلية، والتي يمكن تحقيقها باستخدام مكون التحميل في LangChain. -
تقسيم المستندات: استخدم مُقسِّم النصوص في LangChain لتقسيم المستندات إلى شظايا نصية بحجم محدد. (ملحوظة: الغرض من تقسيم النصوص هو تسهيل البحث عن شظايا المحتوى ذات الصلة استنادًا إلى الأسئلة. وسبب آخر للتقسيم هو أن النموذج اللغوي الكبير لديه حد أقصى للرموز.) -
تخزين: بعد تقسيم المستندات، قم بحساب متجهات ميزات المستندات باستخدام نموذج التضمين ثم قم بتخزينها في قاعدة بيانات المتجهات. -
استرجاع: استنادًا إلى السؤال، اسأل قاعدة البيانات المتجهية لاسترجاع شظايا المستند المماثلة. -
الإنتاج: استخدم سلسلة الأسئلة والأجوبة في LangChain لأداء الأسئلة والأجوبة، وقم بربط شظايا المستند المتعلقة بالسؤال مع السؤال نفسه في رسائل AI التي صممتها، ثم قم بتمريرها إلى النموذج اللغوي الكبير للإجابة على السؤال. -
المحادثة(اختياري): من خلال إضافة مكون الذاكرة إلى سلسلة الأسئلة والأجوبة، يمكنك إضافة وظيفة ذاكرة الرسائل التاريخية للذكاء الاصطناعي لتسهيل حوارات الأسئلة والأجوبة متعددة الدورات.
عملية الأسئلة والأجوبة بالذكاء الاصطناعي موضحة في الرسم التوضيحي التالي:
البدء
لبدء سريع، يمكن للعملية أعلاه أن تُلفّ في كائن واحد VectorstoreIndexCreator. لنفترض أننا نريد إنشاء برنامج سؤال وجواب Q&A استنادًا إلى هذه مدونة، يمكن تحقيق ذلك ببضعة أسطر فقط من الكود:
- ملاحظة: لا يزال هذا الفصل يستخدم نموذج اللغة الكبير من OpenAI.
أولاً، قم بتعيين متغيرات البيئة وتثبيت الحزم المطلوبة:
pip install openai chromadb
export OPENAI_API_KEY="..."
ثم قم بتشغيل:
from langchain_community.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
index = VectorstoreIndexCreator().from_loaders([loader])
الآن، ابدأ في طرح الأسئلة:
index.query("ما هي فكرة تقسيم المهام؟")
تقسيم المهام هو تقنية لتقسيم المهام المعقدة إلى خطوات أصغر وأبسط. يمكن القيام بها باستخدام LLM مع رسائل بسيطة، تعليمات محددة للمهام أو إدخال بشري. Mindtrees (Yao et al.2023) هو مثال على تقنية تقسيم المهام، التي تستكشف احتمالات التفكير المتعددة في كل خطوة وتولّد أفكارًا متعددة في كل خطوة لإنشاء هيكل شجري.
البرنامج قيد التشغيل، ولكن كيف يتم تنفيذه تحت الغطاء؟ دعونا نقسم العملية خطوة بخطوة.
الخطوة 1: التحميل (تحميل بيانات المستند)
حدد DocumentLoader لتحميل البيانات المحددة إلى كائن Documents. يمثل كائن Document قطعة نصية (page_content) وبيانات ذات صلة.
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
- ملاحظة: يوفر Langchain محملات مختلفة لتحميل مريح لأنواع مختلفة من البيانات، يمكن الرجوع إليها في الفصول السابقة.
الخطوة 2: التقسيم (تقسيم المستندات)
نظرًا لأن الاستفسارات التي تقدمها النماذج الكبيرة لها حد أقصى لعدد الرموز لا يمكن تمرير الكثير من محتوى المستند إلى الذكاء الاصطناعي. من العادة يكون كافيًا تمرير شظايا المستند ذات الصلة، لذا نحتاج إلى معالجة شظايا المستند هنا.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 0)
all_splits = text_splitter.split_documents(data)
الخطوة 3. تخزين (تخزين الناقل الفضائي)
من أجل الاستعلام عن مقاطع الوثائق ذات الصلة بناءً على سؤال معين، نحتاج إلى حساب نواقل ميزات النص لمقاطع الوثيقة التي تم تقسيمها مسبقًا باستخدام نموذج تضمين، ثم تخزينها في قاعدة بيانات الناقل الفضائي.
هنا نستخدم قاعدة بيانات الناقل الفضائي الافتراضية "كروما" المقدمة من لانجتشين، ثم نستخدم نموذج التضمين المفتوح "openai".
- ملحوظة: يمكنك أيضًا اختيار نماذج مفتوحة المصدر أخرى كبديل لنموذج التضمين.
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
الخطوة 4. استرجاع (استعلام الوثائق ذات الصلة)
استرجع مقاطع الوثائق ذات الصلة بالسؤال من خلال البحث عن التشابه.
- ملحوظة: الغرض من هذه الخطوة هو إظهار وظيفة البحث عن التشابه في قاعدة الناقل الفضائي. تتضمن وظيفة هذه الخطوة تلقائيًا في سلسلة الأسئلة والأجوبة التي تم تجميعها بواسطة لانجتشين في الخطوة الخامسة.
question = "ما هي أساليب تقسيم المهام؟"
docs = vectorstore.similarity_search(question)
len(docs)
4
الخطوة 5. توليد (استخدام الذكاء الاصطناعي للرد على الأسئلة)
استخدم نموذج LLM/Chat (على سبيل المثال gpt-3.5-turbo) وسلسلة RetrievalQA لتلخيص المستندات المسترجعة في إجابة واحدة.
- نصيحة:
RetrievalQAهي سلسلة مجمعة من قبل LangChain، قادرة على تنفيذ الإجابة على الأسئلة القائمة على المعرفة الاصطناعية بناءً على قاعدة المعرفة المحلية.
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectorstore.as_retriever())
qa_chain({"query": question})
{
'query': 'ما هي أساليب تقسيم المهام؟',
'result': 'أساليب تقسيم المهام تشمل:\n\n1. التحفيز البسيط: يستخدم هذا الأسلوب استفسارات أو أسئلة بسيطة لتوجيه العامل في تقسيم المهمة إلى أهداف فرعية أصغر. على سبيل المثال، يمكن توجيه العامل بـ "خطوات لتحقيق XYZ" وطلب قائمة بالأهداف الفرعية لتحقيق XYZ.\n\n2. التعليمات المحددة للمهمة: في هذا الأسلوب، يتم توفير تعليمات محددة للمهمة لتوجيه عملية التقسيم للعامل. على سبيل المثال، إذا كانت المهمة هي كتابة رواية، يمكن تعليم العامل بـ "صياغة مخطط للقصة" كهدف فرعي.\n\n3. المساهمة البشرية: يشمل هذا الأسلوب دمج المساهمة البشرية في عملية تقسيم المهمة. يمكن للبشر توجيه العامل، وتقديم ملاحظات واقتراحات لمساعدته في تقسيم المهام الكبيرة إلى أهداف فرعية قابلة للإدارة.\n\nهذه الأساليب تهدف إلى التعامل بكفاءة مع المهام المعقدة من خلال تقسيمها إلى أجزاء أصغر وأكثر قابلية للإدارة.'
}
يرجى ملاحظة أنه يمكنك تمرير "LLM" أو "ChatModel" إلى سلسلة "RetrievalQA".
نصيحة: يستخدم هذا البرنامج التعليمي سلسلة "RetrievalQA" المضمنة في LangChain لتنفيذ الإجابة على الأسئلة التي تعتمد على المعرفة. في الواقع، للإصدار الجديد من LangChain، باستخدام تعابير لغة LangChain Expression Language (LCEL)، من السهل تخصيص سلسلة إجابة على الأسئلة مماثلة. يرجى الرجوع إلى القسم المعني فيما يتعلق بـ LCEL.
قالب الاستفسار المخصص
عند استخدام سلسلة "RetrievalQA" مسبقًا، لم نقم بتعيين كلمة استفسار واستخدمنا قالب كلمة الاستفسار المدمج من لانجتشين. الآن، دعنا نخصص قالب كلمة الاستفسار.
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
template ="""قم بالرد على السؤال بناءً على السياق أدناه.
إذا لم تكن تعرف الإجابة، فقط قل "لا أعرف"، ولا تحاول تصنيع إجابة.
يجب أن تكون الإجابة خلال 3 جمل، واجعلها موجزة.
قل دائمًا "شكرًا على سؤالك!" في نهاية الإجابة.
{context}
السؤال: {question}
الإجابة: """
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)
result = qa_chain({"query": question})
result["result"]
مرجع لإجابة الذكاء الاصطناعي على الأسئلة
استخدم RetrievalQAWithSourcesChain بدلاً من RetrievalQA لإعادة إجابات الذكاء الاصطناعي بناءً على أي مستند.
from langchain.chains import RetrievalQAWithSourcesChain
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(llm, retriever=vectorstore.as_retriever())
result = qa_chain({"question": question})
result
استنادًا إلى المثال السابق للرد على الأسئلة باستخدام روابط المدونات، فإن النتائج المرجعية هي كالتالي، مما يسمح لنا برؤية أن الذكاء الاصطناعي قد أجاب على السؤال بناءً على رابط المدونة المحدد:
{
'question': 'ما هي الأساليب المستخدمة لتفكيك المهام؟',
'answer': 'تشمل أساليب تفكيك المهام (1) استخدام LLM والاستفسارات البسيطة، (2) استخدام تعليمات محددة للمهمة، و (3) إشراك إدخال بشري ضمنها.\n',
'sources': 'https://lilianweng.github.io/posts/2023-06-23-agent/'
}