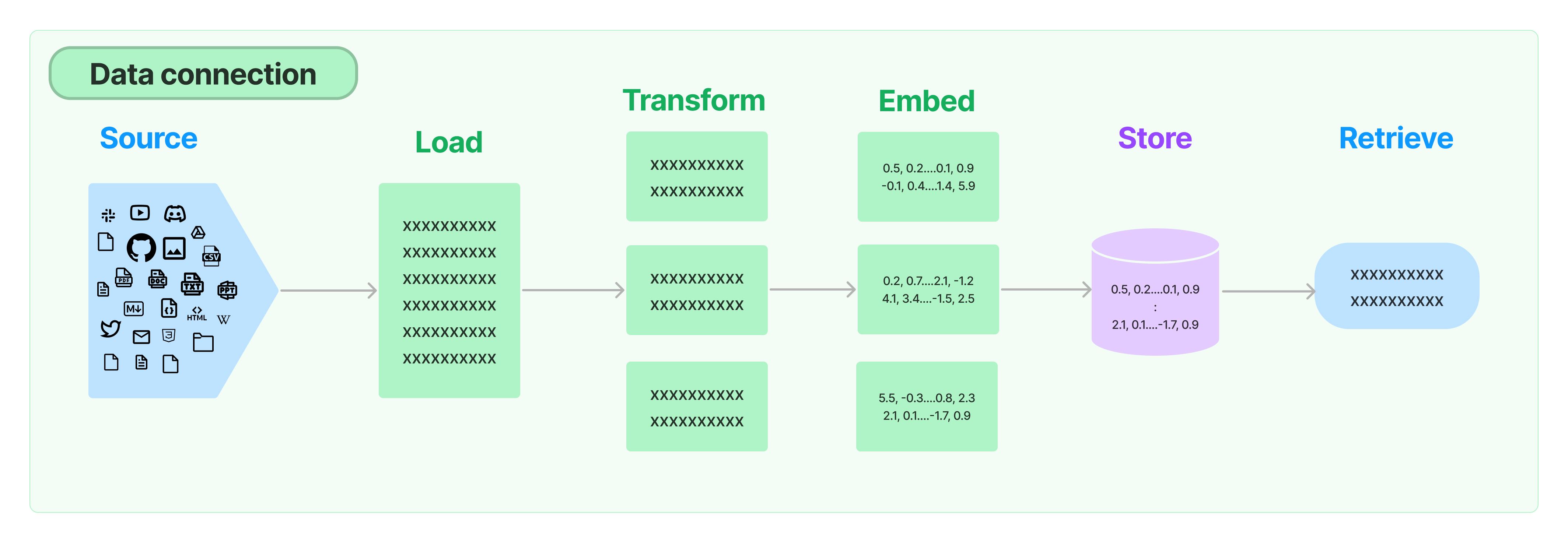
हालांकि भाषा मॉडल (LM) ट्रेन करने से बहुत सारी जानकारी होती है, लेकिन यह उद्यम निजी डेटा और नए डेटा के बारे में अभी तक नहीं जानता है। कई LM अनुप्रयोगों को उद्यम निजी डेटा क्वेरी करने की आवश्यकता होती है, फिर निजी डेटा को पृस्तावना में पृष्ठभूमि जानकारी के रूप में जोड़ते हैं, और उसे विशाल मॉडल में भोजन कराते हैं ताकि पृष्ठभूमि जानकारी के आधार पर सवालों का जवाब दिया जा सके। LangChain डेटा लोड करने, परिवर्तित करने, स्टोर करने और क्वेरी करने के लिए फ्रेमवर्क कॉम्पोनेंट प्रदान करता है।
LangChain के निजी डेटा को संभालने के लिए कॉम्पोनेंट्स में शामिल हैं:
- डॉक्यूमेंट लोडर: विभिन्न स्रोतों से डॉक्यूमेंट डेटा लोड करना समर्थन करता है।
- डॉक्यूमेंट कनवर्टर: डॉक्यूमेंट को विभाजित करता है, प्रश्न-उत्तर स्वरूप में कनवर्ट करता है, और अतिरिक्त डॉक्यूमेंट्स को हटा देता है।
- पाठ एम्बेडिंग मॉडल: अंरूपित पाठ को फ़ीचर वेक्टर में बदलता है जिससे सेमांटिक समानता खोज की समर्थन करता है, उदाहरण के लिए सवाल के समान सामग्री की क्वेरी कर सकता है।
- वेक्टर स्टोरेज: वेक्टर डेटा को संग्रहित करता है और खोजता है।
- रिट्रीवर: LangChain का संगृहीत उपयोगी वर्ग जो आपके डेटा को सरलता से क्वेरी करने के लिए होता है।