ローカル知識ベースに基づいたAI Q&Aの例
テキスト文書(PDF、ブログ、ローカルのプライベートデータなど)を持っており、ローカル知識ベースに基づいたAI Q&Aチャットボットを作成したいとします。LangChainを使用してこのQ&A機能を実装することは簡単です。以下は、LangChainを使用してこのQ&A機能を実現する手順のステップバイステップガイドです。
- 注:LLM(large language model)のトレーニングコストが高いため、大規模言語モデル自体の知識ベースは頻繁に更新されません。このAIは、トレーニングされたコンテンツのみを知っており、新しいコンテンツや企業/個人のプライベートデータには対応していませんので、ローカル知識ベースと大規模言語モデルを組み合わせる必要があります。
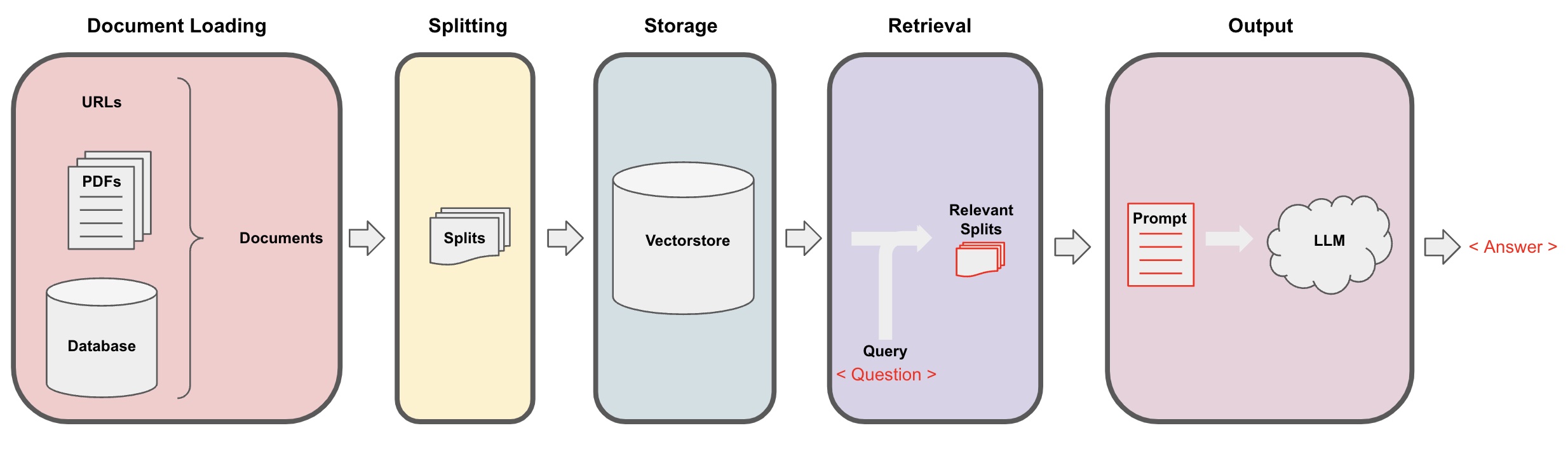
AI Q&Aのプロセス
-
ドキュメントの読み込み:まず、LangChainのローダーコンポーネントを使用してローカルのテキストデータを読み込む必要があります。 -
ドキュメントの分割:LangChainのテキスト分割ツールを使用してドキュメントを指定されたサイズのテキストフラグメントに分割します。(注:テキストの分割の目的は、質問に基づいて関連するコンテンツフラグメントを検索しやすくすることです。分割の別の理由は、大規模言語モデルには最大トークン制限があるためです。) -
ストレージ:ドキュメントを分割した後、埋め込みモデルを使用してドキュメントの特徴ベクトルを計算し、それらをベクトルデータベースに保存します。 -
検索:質問に基づいて、ベクトルデータベースから類似のドキュメントフラグメントを取得します。 -
生成:LangChain QAチェーンを使用してQ&Aを実行し、質問に関連するドキュメントフラグメントを質問自体と連結し、自分で設計したAIプロンプトとしてLLMに渡して質問に答えさせます。 -
会話(オプション):QAチェーンにMemoryコンポーネントを追加することで、マルチターンのQ&Aダイアログを容易にするAIの履歴メッセージメモリ機能を追加できます。
AI Q&Aプロセスは、以下の図で説明されています:
はじめに
上記のプロセスを1つのオブジェクトVectorStoreIndexCreatorにまとめることで、素早く開始できます。たとえば、このブログ投稿を元にQA Q&Aプログラムを作成したいとします。次の数行のコードで実現できます:
- 注:このチャプターでは引き続きOpenAIの大規模言語モデルを使用します。
まず、環境変数を設定し、必要なパッケージをインストールします:
pip install openai chromadb
export OPENAI_API_KEY="..."
次に実行してください:
from langchain_community.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
index = VectorstoreIndexCreator().from_loaders([loader])
さて、質問を始めましょう:
index.query("タスク分解とは何ですか?")
タスク分解は、複雑なタスクをより小さな単純なステップに分解するテクニックです。単純なプロンプトを使用したLLM、タスク固有の指示、または人間の入力を使用して行うことができます。Mindtrees(Yao et al.2023)は、各ステップで複数の推論可能性を探索し、各ステップで複数のアイデアを生成してツリー構造を作成するタスク分解テクニックの例です。
プログラムは実行されていますが、実際にはどのように実装されているのでしょうか?では、プロセスをステップごとに詳しく見ていきましょう。
ステップ1. 読み込み(ドキュメントデータの読み込み)
指定したデータをDocumentsオブジェクトにロードするためにDocumentLoaderを指定します。Documentオブジェクトは、テキスト(page_content)と関連するメタデータを表します。
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
- 注:Langchainにはさまざまなローダーが用意されており、さまざまな種類のデータを便利にロードすることができます。これは以前の章で参照できます。
ステップ3. 格納(ベクトル格納)
質問に基づいて関連する文書断片をクエリするために、以前に分割された文書断片のテキスト特徴ベクトルを埋め込みモデルを使用して計算し、ベクトルデータベースに格納する必要があります。
ここでは、Langchainが提供するデフォルトのベクトルデータベース「chroma」を使用し、その後、openaiの埋め込みモデルを使用します。
- 注意: 埋め込みモデルの代わりに他のオープンソースモデルを選択することもできます。
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
ステップ4. 検索(関連文書のクエリ)
類似性検索を通じて質問に関連する文書断片を取得します。
- 注意: このステップの目的は、ベクトルデータベースの類似性検索機能を実証することです。このステップの機能は、Langchainによって5番目のステップでカプセル化されたQ&Aチェーンに自動的に含まれています。
question = "タスク分解の方法は何ですか?"
docs = vectorstore.similarity_search(question)
len(docs)
4
ステップ5. 生成(AIを使用した質問への回答)
LLM/Chatモデル(例: gpt-3.5-turbo)およびRetrievalQAチェーンを使用して、取得した文書断片を1つの回答にまとめます。
- ヒント:
RetrievalQAは、ローカル知識ベースに基づいたAI質問応答を実装できるLangChainによってカプセル化されたチェーンです。
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectorstore.as_retriever())
qa_chain({"query": question})
{
'query': 'タスク分解の方法は何ですか?',
'result': 'タスク分解の方法には次のものがあります:\n\n1. 簡単なプロンプト: この方法では、タスクをより小さなサブゴールに分解するために簡単なプロンプトや質問を使用します。例えば、「XYZの手順」とプロンプトされ、XYZを達成するためのサブゴールをリストアップするようにエージェントに要求されます。\n\n2. タスク固有の指示: この方法では、エージェントのタスクを分解するためにタスク固有の指示が提供されます。例えば、小説を書くというタスクの場合、エージェントに「ストーリーの概要を起案する」というサブゴールを指示できます。\n\n3. 人間の入力: この方法では、人間の入力をタスク分解プロセスに組み込みます。人間は、複雑なタスクをより管理しやすいサブゴールに分解するためにガイダンス、フィードバック、提案を提供します。\n\nこれらの方法は、複雑なタスクを効率的に処理することを目的としています。'
}
"RetrievalQA"チェーンに"LLM"または"ChatModel"を渡すことができます。
ヒント: このチュートリアルでは、LangChainに組み込まれた
RetrievalQAチェーンを使用して知識ベースの質問応答を実装しています。実際には、LangChainの新しいバージョンでは、LangChain Expression Language(LCEL)式を使用して、類似の質問応答チェーンを簡単にカスタマイズできます。詳細については、LCELに関する関連セクションを参照してください。
カスタムプロンプトテンプレート
以前にRetrievalQAチェーンを使用する際、プロンプト単語を設定せずに、langchainの組み込みプロンプトテンプレートを使用しました。以下では、プロンプト単語テンプレートをカスタマイズします。
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
template ="""
以下のコンテキストに基づいて質問に答えてください。
答えがわからない場合は「わからない」と言って、答えをでっち上げないでください。
回答は3文以内にし、簡潔にしてください。
回答の最後にはいつも「ご質問ありがとうございます!」と言ってください。
{context}
質問: {question}
回答:
"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)
result = qa_chain({"query": question})
result["result"]
AI Q&A応答の参照
AIの回答をドキュメントに基づいて返すには、RetrievalQAの代わりにRetrievalQAWithSourcesChainを使用してください。
from langchain.chains import RetrievalQAWithSourcesChain
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(llm, retriever=vectorstore.as_retriever())
result = qa_chain({"question": question})
result
ブログリンクに基づいて質問に答える前の例に基づいて、返される結果は以下のとおりです。これにより、AIが特定のブログURLに基づいて質問に答えたことがわかります。
{
'question': 'タスク分解の方法は何ですか?',
'answer': 'タスク分解の方法には、(1)LLMと簡単なプロンプトを使用すること、(2)タスク固有の手順を使用すること、および(3)それに内在する人間の入力を利用することが含まれます。\n',
'sources': 'https://lilianweng.github.io/posts/2023-06-23-agent/'
}