Beispiel einer KI-Frage-Antwort basierend auf lokaler Wissensdatenbank
Angenommen, Sie haben einige Textdokumente (PDFs, Blogs, lokale private Daten usw.) und möchten einen KI-Frage-Antwort-Chatbot basierend auf einer lokalen Wissensdatenbank erstellen. Es ist einfach, diese Funktionalität mit LangChain zu implementieren. Nachfolgend finden Sie eine schrittweise Anleitung, wie Sie diese Q&A-Funktionalität mithilfe von LangChain erreichen können.
- Hinweis: Aufgrund der hohen Kosten für das Training des LLM (großes Sprachmodell) wird die Wissensdatenbank des großen Sprachmodells selbst nicht häufig aktualisiert. Die KI kennt nur die Inhalte, auf denen sie trainiert wurde, und ist nicht über neue Inhalte oder Unternehmens-/persönliche private Daten informiert. Daher ist es notwendig, die lokale Wissensdatenbank mit dem großen Sprachmodell zu kombinieren.
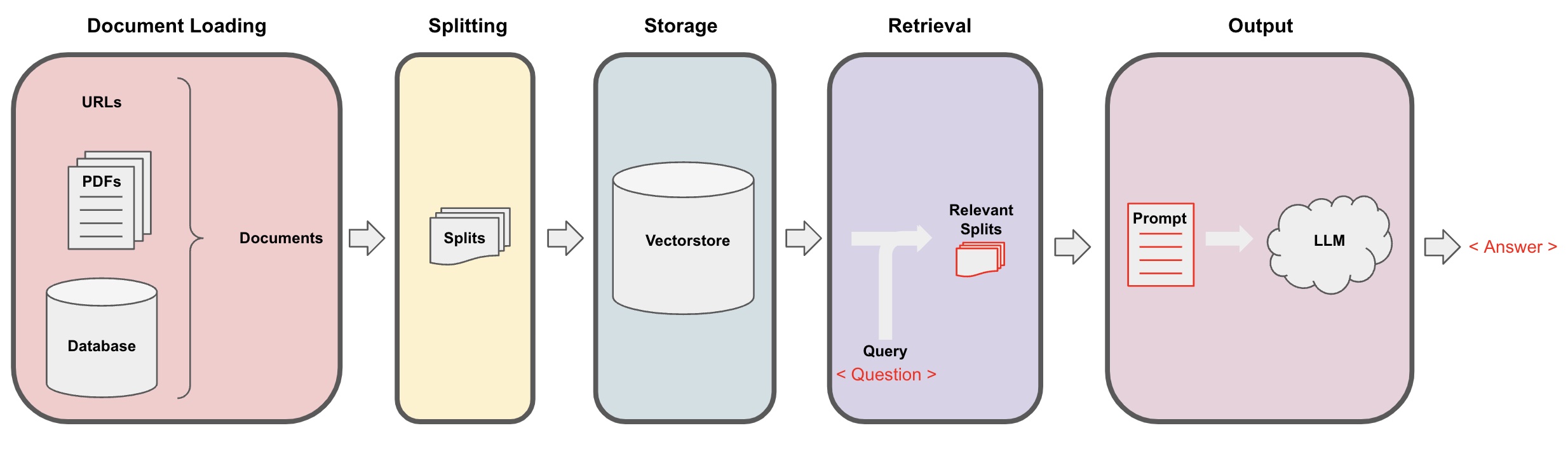
KI-Frage-Antwort-Prozess
-
Dokumentenladung: Zuerst müssen wir unsere lokalen Textdaten laden, was mit dem Loader-Komponenten von LangChain erreicht werden kann. -
Dokumentenaufteilung: Verwenden Sie LangChain's Text-Splitter, um die Dokumente in spezifische Textfragmente bestimmter Größe zu segmentieren. (Hinweis: Der Zweck der Textsegmentierung besteht darin, die relevanten Inhaltsfragmente basierend auf den Fragen zu erleichtern. Ein weiterer Grund für die Segmentierung ist, dass das große Sprachmodell eine maximale Token-Begrenzung hat.) -
Speicherung: Nach der Segmentierung der Dokumente berechnen Sie die Merkmalsvektoren der Dokumente mit einem Einbettungsmodell und speichern Sie sie dann in einer Vektordatenbank. -
Abruf: Basierend auf der Frage, greifen Sie auf die Vektordatenbank zu, um ähnliche Dokumentfragmente abzurufen. -
Generierung: Verwenden Sie die LangChain-QA-Kette, um Q&A durchzuführen, konkatenieren Sie die Dokumentfragmente, die sich auf die Frage beziehen, mit der Frage selbst zu KI-Prompts, die von Ihnen entworfen wurden, und leiten Sie sie zur Beantwortung der Frage an das LLM weiter. -
Unterhaltung(optional): Durch Hinzufügen der Memory-Komponente zur QA-Kette können Sie die Funktionalität der KI-Historienachrichtenspeicherung hinzufügen, um eine Multi-Turn-Q&A-Dialoge zu erleichtern.
Der KI-Frage-Antwort-Prozess ist in folgendem Diagramm dargestellt:
Erste Schritte
Um einen schnellen Einstieg zu erhalten, kann der obige Prozess in ein einzelnes Objekt VectorstoreIndexCreator eingepackt werden. Angenommen, wir möchten ein Q&A-Programm auf Basis dieses Blog-Posts erstellen. Dies kann mit nur wenigen Codezeilen erreicht werden:
- Hinweis: Dieses Kapitel verwendet weiterhin das große Sprachmodell von OpenAI.
Legen Sie zunächst die Umgebungsvariablen fest und installieren Sie die erforderlichen Pakete:
pip install openai chromadb
export OPENAI_API_KEY="..."
Führen Sie dann aus:
from langchain_community.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
index = VectorstoreIndexCreator().from_loaders([loader])
Stellen Sie nun Fragen:
index.query("Was ist Aufgabenzerlegung?")
Aufgabenzerlegung ist eine Technik, um komplexe Aufgaben in kleinere, einfachere Schritte zu zerlegen. Dies kann mithilfe von LLM mit einfachen Aufforderungen, aufgabenbezogenen Anweisungen oder menschlicher Eingabe erfolgen. Mindtrees (Yao et al.2023) ist ein Beispiel für eine Aufgabenzerlegungstechnik, die bei jedem Schritt mehrere Denkmöglichkeiten erkundet und bei jedem Schritt mehrere Ideen generiert, um eine Baumstruktur zu erstellen.
Das Programm läuft, aber wie wird es im Hintergrund implementiert? Lassen Sie uns den Prozess Schritt für Schritt durchgehen.
Schritt 1. Laden (Laden von Dokumentendaten)
Legen Sie einen DocumentLoader fest, um die angegebenen Daten in ein Documents-Objekt zu laden. Das Document-Objekt repräsentiert einen Textabschnitt (page_content) und zugehörige Metadaten.
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
- Hinweis: Langchain bietet verschiedene Loader zum bequemen Laden verschiedener Datentypen, auf die in den vorherigen Kapiteln verwiesen werden kann.
Schritt 2. Aufteilen (Aufteilen von Dokumenten)
Aufgrund der maximalen Tokenbegrenzung von großen Modell-Aufforderungen können wir nicht zu viel Dokumentinhalt an die KI übergeben. Es ist in der Regel ausreichend, relevante Dokumentfragmente zu übergeben, daher müssen wir hier die Dokumentschnitte verarbeiten.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 0)
all_splits = text_splitter.split_documents(data)
Schritt 3. Speichern (Vektor-Speicher)
Um relevante Dokumentfragmente basierend auf einer Frage abzufragen, müssen wir die Text-Merkmalvektoren für die zuvor aufgeteilten Dokumentfragmente mithilfe eines Einbettungsmodells berechnen und dann in einer Vektordatenbank speichern.
Hier verwenden wir die standardmäßige Vektordatenbank "chroma", die von Langchain zur Verfügung gestellt wird, und dann das OpenAI-Einbettungsmodell.
- Hinweis: Sie können auch andere Open-Source-Modelle als Ersatz für das Einbettungsmodell auswählen.
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
Schritt 4. Abrufen (Abfrage relevanter Dokumente)
Rufen Sie Dokumentfragmente ab, die mit der Frage zusammenhängen, mithilfe einer Ähnlichkeitssuche.
- Hinweis: Der Zweck dieses Schrittes ist es, die Funktion der Ähnlichkeitssuche der Vektordatenbank zu demonstrieren. Die Funktionalität dieses Schrittes ist automatisch im Q&A-Chain von Langchain im 5. Schritt enthalten.
question = "Was sind die Methoden zur Aufgabenzerlegung?"
docs = vectorstore.similarity_search(question)
len(docs)
4
Schritt 5. Generieren (Verwendung von KI zur Beantwortung von Fragen)
Verwenden Sie das LLM/Chat-Modell (z.B. gpt-3.5-turbo) und die RetrievalQA-Kette, um das abgerufene Dokument in eine einzige Antwort zu kondensieren.
- Tipp:
RetrievalQAist eine von LangChain verkapselte Kette, die in der Lage ist, KI-Fragen auf Basis einer lokalen Wissensbasis zu beantworten.
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectorstore.as_retriever())
qa_chain({"query": question})
Referenz für KI-Fragen-Antwort
Verwenden Sie RetrievalQAWithSourcesChain anstelle von RetrievalQA, um die Antworten der KI basierend auf dem zugehörigen Dokument zurückzugeben.
from langchain.chains import RetrievalQAWithSourcesChain
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(llm, retriever=vectorstore.as_retriever())
result = qa_chain({"question": question})
result
Unter Berücksichtigung des vorherigen Beispiels zur Beantwortung von Fragen basierend auf Blog-Links lauten die zurückgegebenen Ergebnisse wie folgt, sodass wir sehen können, dass KI die Frage basierend auf der spezifischen Blog-URL beantwortet hat:
{
'question': 'Welche Methoden gibt es zur Aufgabenzerlegung?',
'answer': 'Methoden zur Aufgabenzerlegung umfassen (1) die Verwendung von LLM und einfachen Eingabeaufforderungen, (2) die Verwendung von aufgabenspezifischen Anweisungen und (3) die Einbeziehung menschlicher Eingaben darin.\n',
'sources': 'https://lilianweng.github.io/posts/2023-06-23-agent/'
}