
एक वेक्टर डेटाबेस एक अनुचित डेटा प्रतिरूपन से आता है जो अंधेरे मशीन सीखने के मॉडलों जैसे गहरे लर्निंग संरचनाओं से आता है। इन प्रतिरूपनों को सामान्यत: वेक्टर या एम्बेडिंग वेक्टर कहा जाता है, और ये डेटा की संक्षिप्त संस्करण होते हैं जो कि मशीन सीखने मॉडल्स को प्रश्नों का संपादन करने के लिए प्रशिक्षित करने के लिए प्रयोग किए जाते हैं, जैसे-मैथेमैटिकल विश्लेषण, भाषा पहचाना और बस्तु पहचान।
ये नए डेटाबेसों ने बहुत सारी अनुप्रयोगों में अत्यधिक प्रदर्शन दिखाया है, जैसे कि सांत्वना खोज और सुझाव प्रणालियों में।
क्या Qdrant है?
Qdrant एक ओपन-सोर्स वेक्टर डेटाबेस है जो आगे के पीढ़ी ए.आई. अनुप्रयोगों के लिए डिज़ाइन किया गया है। यह क्लाउड-नेटिव है और इम्बेडिंग्स को प्रबंधित करने के लिए रेस्टफुल और जीआरपीसी एपीआई प्रदान करता है। Qdrant विशेषताओं का गर्व है, जो छवि, आवाज़ और वीडियो खोज, और ए.आई. इंजन के साथ एकीकरण का समर्थन करता है।
वेक्टर डेटाबेस क्या होता है?
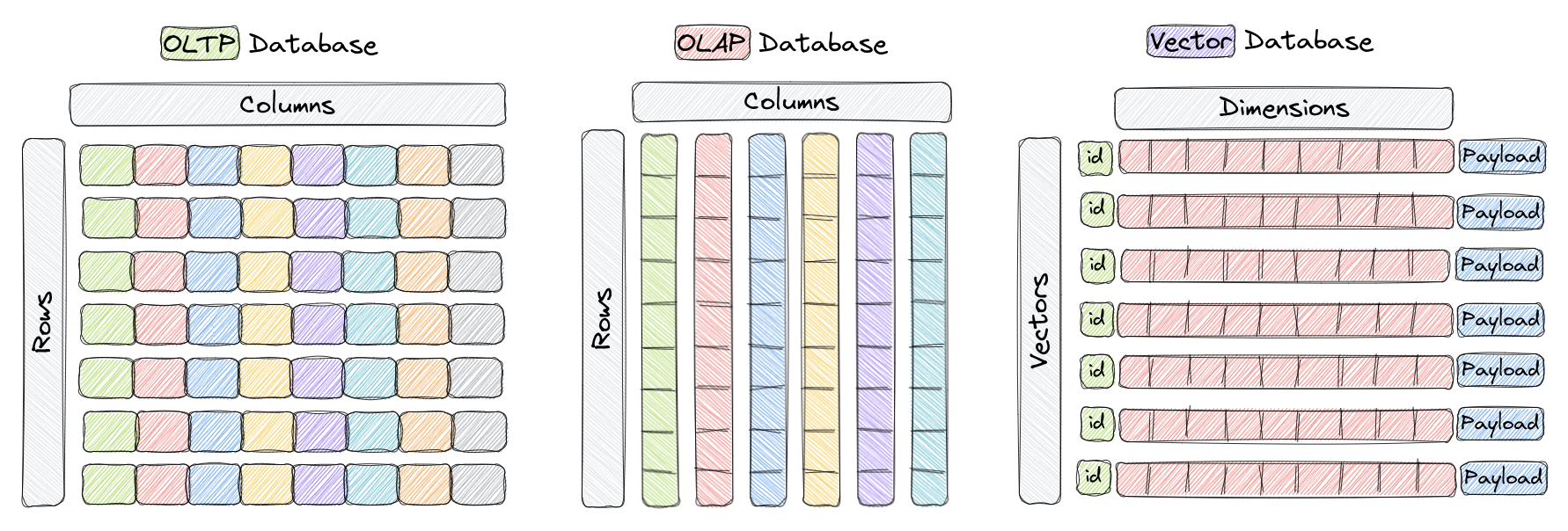
वेक्टर डेटाबेस वह डेटाबेस का प्रकार है जो उच्च-आयामी वेक्टर्स के दक्षन्य रूप से कुंजीबद्ध और पूछताछ के लिए विशेष रूप से डिज़ाइन किया गया है। पारंपरिक ओएलटीपी और ओएलएपी डेटाबेसों में (जैसा कि ऊपरी चित्र में दिखाया गया है) डेटा को पंक्तियों और स्तंभों (को तालिकाएँ कहा जाता है) में आयोजित किया जाता है, और प्रश्न इन स्तंभों में होते हैं। हालांकि, कुछ ऐप्लिकेशन्स में जैसे कि छवि पहचान, प्राकृतिक भाषा प्रसंस्करण, और सुझाव प्रणालियों में, डेटा अक्सर उच्च-आयामी अंतरिक्ष में वेक्टर के रूप में प्रस्तुत किया जाता है। ये वेक्टर, एक आईडी और भारी भरकम, वेक्टर डेटाबेसों में संग्रहित तत्वों का गठन करते हैं जैसे कि Qdrant में।
इस संदर्भ में, वेक्टर एक ऑब्जेक्ट या डेटा पॉइंट का गणितीय प्रतिनिधि होता है, जहाँ वेक्टर का प्रत्येक तत्व ऑब्जेक्ट की विशेषता या गुण का प्रतिनिधि करता है। उदाहरण के लिए, एक इमेज पहचान प्रणाली में, एक वेक्टर एक इमेज का प्रतिनिधित्व कर सकता है, जिसमें वेक्टर का प्रत्येक तत्व पिक्सेल का मान या पिक्सेल की विशेषता/वर्णन का प्रतिनिधित्व करता है। एक संगीत सुझाव प्रणाली में, प्रत्येक वेक्टर एक गाना का प्रतिनिधित्व करता है, जहाँ वेक्टर का प्रत्येक तत्व, जैसे कि रिद्धम, शैली, गाने के बोल, आदि का प्रतिनिधित्व करता है।
वेक्टर डेटाबेस उच्च-आयामी वेक्टर्स के अधिक संरचित और प्रश्न हेतु संशोधित किए गए हैं, अक्सर उपयुक्त डेटा संरचनाएँ और अनुक्रमणिका तकनीकों, जैसे कि संधारण निविगेबल स्मॉल वर्ल्ड (एचएनएसडब्ल्यू) और प्रोडक्ट क्वांटिज़ेशन का उपयोग करते हैं। इन डेटाबेस में उपयोग करने वाले दूरता अंकन संकेतक विशेषता, वास्तूतः अनुपस्थित है।
यहां इन तीन वेक्टर समानता एल्गोरिदम का संक्षिप्त परिचय है:
- कोसाइन समानता - कोसाइन समानता दो आइटमों के बीच समानता को मापती है। इसे दो बिंदुओं के बीच दूरी का मापक के रूप में देखा जा सकता है; हालांकि, दूरी का मापक की बजाय, यह दो आइटमों के बीच समानता को मापता है। यह सामान्यत: पाठ में दो दस्तावेज़ों या वाक्यों के बीच समानता की तुलना करने के लिए प्रयोग किया जाता है। कोसाइन समानता का उतपादन सीमा 0 से 1 तक का होता है, जहाँ 0 पूर्ण असमानता को और 1 पूर्ण समानता को दर्शाता है। यह दो आइटमों की तुलना करने का एक सरल और प्रभावी तरीका है!
- डॉट प्रोडक्ट - डॉट प्रोडक्ट समानता दूसरे दो आइटमों के बीच समानता का एक और मापक है, कोसाइन समानता के समान। संख्याओं के साथ काम करते हुए, इसका अक्सर मशीन सीखने और डेटा विज्ञान में प्रयोग होता है। डॉट प्रोडक्ट समानता उन संख्या को गुणा करने और फिर इन उत्पादों को जोड़ने से निकाली जाती है। एक अधिक योग को मानना दो अंकों के सेट्स के बीच अधिक समानता को दर्शाता है। यह दो संख्या सेट के बीच मेल एक मापक की तरह है।
- यूक्लिडियन दूरी - यूक्लिडियन दूरी अंतरिक्ष में दो बिंदुओं के बीच दूरी को मापने का तरीका, जिस तरह हम मानचित्र पर दो स्थानों के बीच दूरी को मापते हैं। इसे दो बिंदुओं के संयोजन के अंतर के वर्ग की जोड़ के वर्ग की मूल निकाल कर प्राप्त किया जाता है। यह दूरी मापन की विधि मशीन सीखने में दो डेटा बिंदुओं की समानता या विषमता का मापन करने के लिए सामान्यत: प्रयुक्त होती है, अन्य शब्दों में, समझने के लिए कि वे कितने दूर हैं।
अब जब हम जानते हैं की वेक्टर डेटाबेस क्या है और उनका संरचनात्मक रूप अन्य डेटाबेसों से कैसे भिन्न है, तो आइए इसको समझते हैं की वे क्यों महत्वपूर्ण हैं।
एक वेक्टर डेटाबेस क्यों आवश्यक है?
वेक्टर डेटाबेस विभिन्न ऐप्लिकेशन में महत्वपूर्ण भूमिका निभाते हैं जो समानता खोज की आवश्यकता है, जैसे सिफारिश सिस्टम, सामग्री-आधारित छवि पुनर्प्राप्ति, और व्यक्तिगत खोज। कुशल सूचकांक और खोज तकनीकों का लाभ लेते हुए, वेक्टर डेटाबेस संरूपित डेटा को वेक्टर्स के रूप में अधिक तेजी से और अधिक सटीकता से प्राप्त कर सकते हैं, उपयोगकर्ता के प्रश्न के लिए सबसे प्रासंजिक परिणाम प्रस्तुत करते हैं।
इसके अलावा, वेक्टर डेटाबेस का उपयोग करने के अन्य लाभ निम्नलिखित हैं:
- उच्च-आयामी डेटा की कुशल भंडारण और सूचीकरण।
- लाखों डेटा बिंदुओं के साथ बड़े पैमाने पर डेटासेट को संभालने की क्षमता।
- वास्तविक समय में विश्लेषण और प्रश्नों का समर्थन।
- चित्रों, वीडियो, और प्राकृतिक भाषा के टेक्स्ट जैसे परिरूपण के देशी से बने वेक्टरों को संभालने की क्षमता।
- मशीन लर्निंग और कृत्रिम बुद्धिमत्ता अनुप्रयोगों की प्रदर्शन को सुधारना और लेटेंसी कम करना।
- निष्क्रिय समाधानों की तुलना में डेवलपमेंट और डिप्लॉयमेंट के समय और लागत में कमी।
कृपया ध्यान दें कि एक वेक्टर डेटाबेस का उपयोग करने के विशेष लाभ आपके संगठन के उपयोग मामलों और चयनित डेटाबेस की क्षमताओं पर निर्भर कर सकते हैं।
अब, चलो Qdrant संरचना का उच्च स्तरीय मूल्यांकन करते हैं।
Qdrant संरचना का उच्च स्तरीय अवलोकन
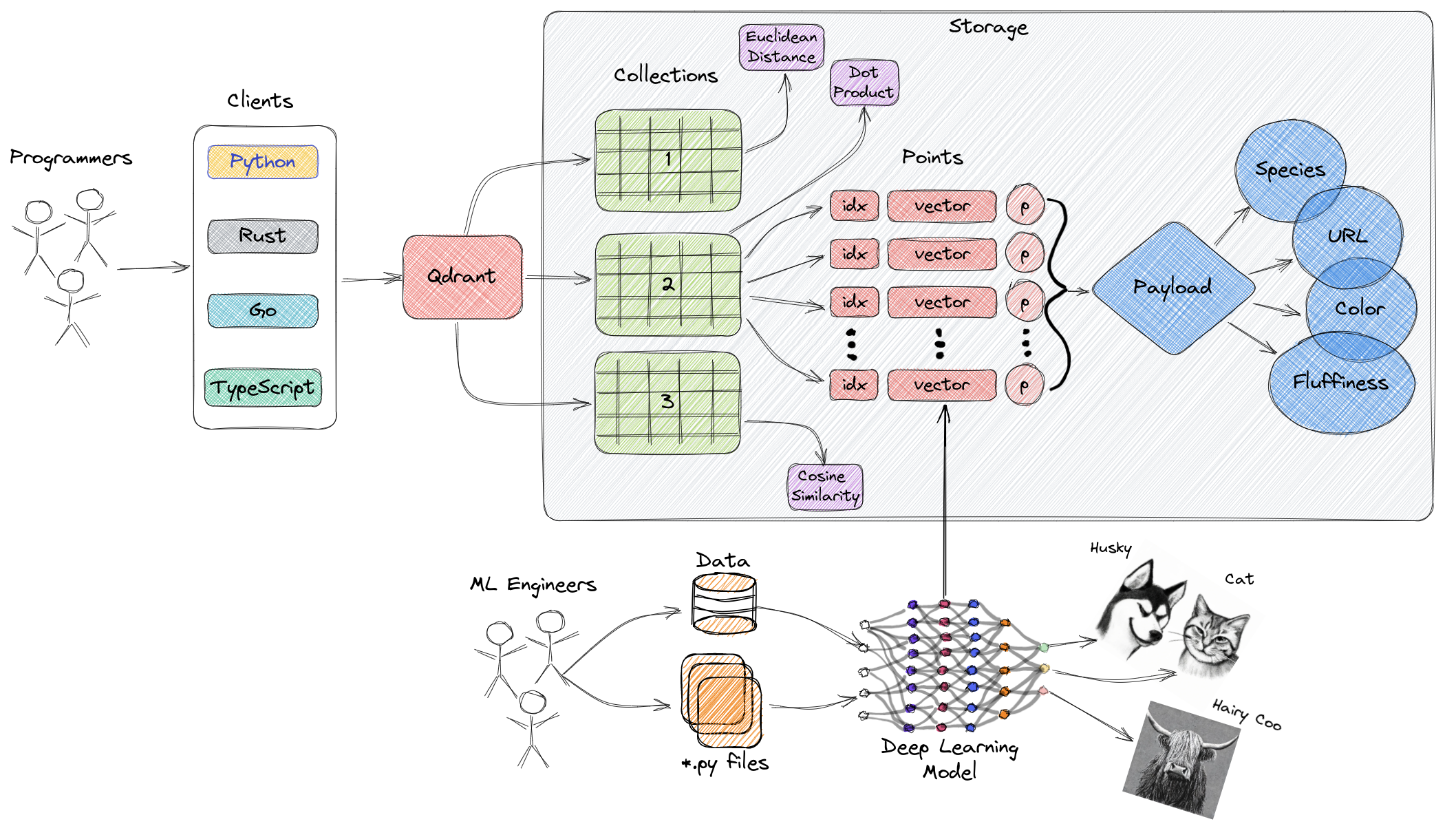
उपरोक्त आरेख में, Qdrant के मुख्य घटकों का उच्च स्तरीय अवलोकन प्रदान करता है। निम्नलिखित Qdrant से संबंधित प्रमुख शब्द हैं:
- संग्रह: संग्रह नामित बिन्दुओं (वेक्टर्स के साथ लोड़) का एक समूह होते हैं। सरल शब्दों में, संग्रह MySQL में तालिकाओं के समान होते हैं, और बिंदुओं के तालिकाओं में डेटा के पंक्तियों के समान होते हैं। इन बिंदुओं के बीच खोज की जा सकती है। एक ही संग्रह के भीतर प्रत्येक वेक्टर का समान आयाम होना चाहिए और एक ही मात्रा का चयन करके तुलना की जानी चाहिए। नामी वेक्टर्स का उपयोग करने के लिए एका बिंदुओं में वेक्टर्स को कई बार रखने के लिए प्रयोग किया जा सकता है, प्रत्येक का अपना आयाम होता है और हर वेक्टर को एक ही मानक आयाम का चयन करके तुलना की जा सकती है।
- माप: वेक्टरों के बीच समानता को मापने के लिए एक माप जो कई स्थापना करता है, जो संग्रह बनाते समय चयनित करना होता है। माप चयन प्राप्ति के विधि पर निर्भर होता है, विशेषकर, न्यूरल नेटवर्क्स के उपयोग के लिए नए प्रश्न को एनकोड करने (माप वह समानता algorithm होता है जिसे हम चुनते हैं)।
- बिंदु: बिंदुओं, Qdrant द्वारा ऑपरेट किए जाने वाले मूल्य से बने एंटिटी होते हैं, जो वेक्टर, वैकल्पिक आईडी, और payloads से बने होते हैं (माइक्रोसॉफ्ट टेबल में डेटा की पंक्तियों के समानू).
- ID: वेक्टर की अद्वितीय पहचानकर्ता।
- वेक्टर: उच्च-आयामी प्रतिनिधि डेटा, जैसे छवियाँ, ऑडियो, दस्तावेज, वीडियो, आदि।
- Payload: वेक्टर के साथ जोड़े जाने वाले एक जेसन ऑब्जेक्ट (प्रमुखत: वेक्टर के साथ संबंधित व्यावसायिक गुणधर्मों को संचित करने के लिए प्रयोग होता है)।
- स्टोरेज: Qdrant दो स्टोरेज विकल्प का उपयोग कर सकता है—मेमोरी स्टोरेज (सभी वेक्टर्स को मेमोरी में संग्रहित करते हुए, सबसे उच्च गति प्रदान करते हुए, क्योंकि डिस्क पहुंच केवल सटीकता के लिए उपयोग की जाती है) और मेममैप स्टोरेज (डिस्क पर फ़ाइलों से जुड़ी एक वर्चुअल पता स्थान बनाता है)।
- ग्राहक: आप Qdrant के प्रोग्रामिंग भाषा SDKs का उपयोग करके या उसकी REST API का सीधा इंटरैक्शन करके Qdrant से जुड़ सकते हैं।