Exemple de questions-réponses basées sur une base de connaissances locale
Supposons que vous ayez des documents textuels (PDF, blogs, données privées locales, etc.) et que vous souhaitiez créer un chatbot de questions-réponses (Q&R) basé sur une base de connaissances locale. Il est facile d'implémenter cette fonctionnalité en utilisant LangChain. Voici un guide étape par étape sur la façon d'atteindre cette fonctionnalité Q&R en utilisant LangChain.
- Remarque : En raison du coût élevé de la formation du LLM (grand modèle de langage), la base de connaissances du grand modèle de langage lui-même ne sera pas fréquemment mise à jour. L'IA ne connaît que le contenu sur lequel elle a été formée et n'est pas au courant des nouveaux contenus ni des données privées d'entreprise ou personnelles, il est donc nécessaire de combiner la base de connaissances locale avec le grand modèle de langage.
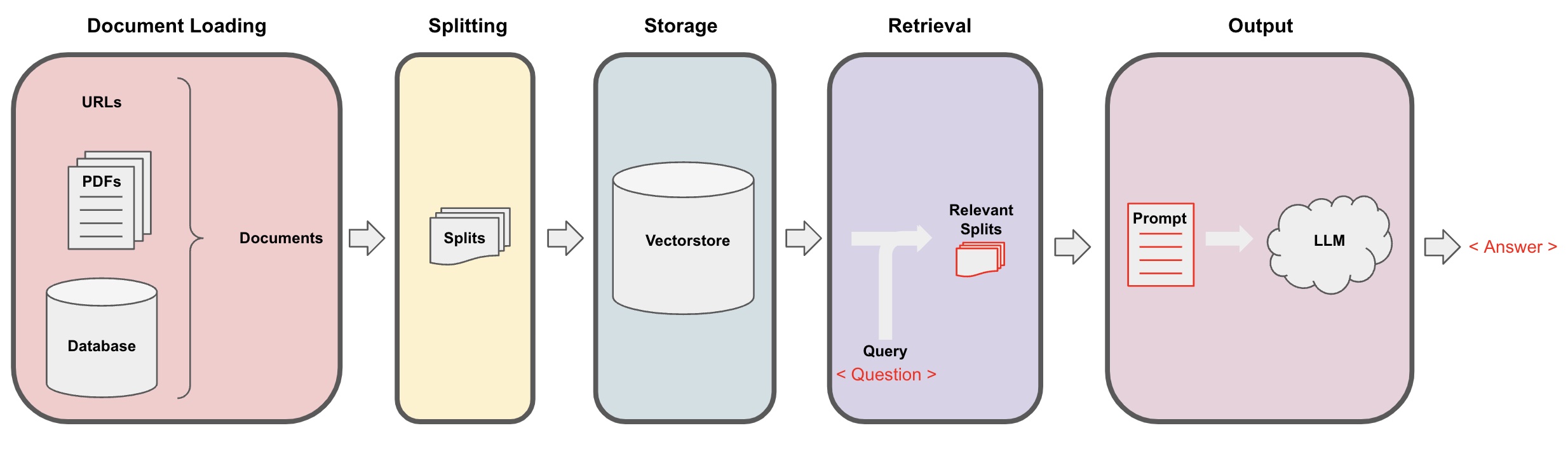
Processus de questions-réponses (Q&R) de l'IA
-
Chargement des documents: Tout d'abord, nous devons charger nos données textuelles locales, ce qui peut être réalisé à l'aide du composant de chargement de LangChain. -
Division des documents: Utilisez le séparateur de texte de LangChain pour segmenter les documents en fragments de texte de taille spécifiée. (Remarque : Le but de la segmentation du texte est de faciliter la recherche de fragments de contenu pertinents en fonction des questions. Une autre raison de la segmentation est que le grand modèle de langage a une limite maximale de jetons.) -
Stockage: Après avoir segmenté les documents, calculez les vecteurs caractéristiques des documents à l'aide d'un modèle d'incorporation, puis stockez-les dans une base de données vectorielle. -
Récupération: En fonction de la question, interrogez la base de données vectorielle pour récupérer des fragments de document similaires. -
Génération: Utilisez la chaîne de Q&R de LangChain pour effectuer des questions-réponses, concaténez les fragments de document liés à la question avec la question elle-même en prompts d'IA conçus par vous, et transmettez-les au LLM pour répondre à la question. -
Conversation(optionnel) : En ajoutant le composant Memory à la chaîne Q&R, vous pouvez ajouter une fonctionnalité de mémoire des messages historiques de l'IA pour faciliter les dialogues Q&R multi-tours.
Le processus de questions-réponses de l'IA est illustré dans le diagramme suivant :
Pour commencer
Pour démarrer rapidement, le processus ci-dessus peut être encapsulé dans un seul objet VectorstoreIndexCreator. Supposons que nous voulions créer un programme de Q&R basé sur cet article de blog. Cela peut être réalisé avec seulement quelques lignes de code :
- Remarque : Ce chapitre utilise toujours le grand modèle de langage OpenAI.
Tout d'abord, définissez les variables d'environnement et installez les packages requis :
pip install openai chromadb
export OPENAI_API_KEY="..."
Ensuite, exécutez :
from langchain_community.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
index = VectorstoreIndexCreator().from_loaders([loader])
Maintenant, commencez à poser des questions :
index.query("Qu'est-ce que la décomposition des tâches?")
La décomposition des tâches est une technique permettant de diviser des tâches complexes en étapes plus petites et plus simples. Cela peut être fait en utilisant LLM avec des prompts simples, des instructions spécifiques à la tâche ou une entrée humaine. Mindtrees (Yao et al.2023) est un exemple de technique de décomposition des tâches, qui explore de multiples possibilités de raisonnement à chaque étape et génère de multiples idées à chaque étape pour créer une structure arborescente.
Le programme s'exécute, mais comment est-il implémenté en interne ? Démontons le processus étape par étape.
Étape 1. Chargement (Chargement des données de document)
Spécifiez un DocumentLoader pour charger les données spécifiées dans un objet Documents. L'objet Document représente un morceau de texte (page_content) et des métadonnées associées.
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
- Remarque : Langchain fournit divers chargeurs pour charger facilement différents types de données, qui peuvent être consultés dans les chapitres précédents.
Étape 2. Division (Division des documents)
Parce que les prompts du grand modèle ont une limite maximale de jetons, nous ne pouvons pas passer trop de contenu de document à l'IA. Il est généralement suffisant de passer des fragments de document pertinents, nous devons donc traiter les découpes de document ici.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 0)
all_splits = text_splitter.split_documents(data)
Étape 3. Stockage (Stockage vectoriel)
Pour pouvoir interroger des fragments de document pertinents en fonction d'une question, nous devons calculer les vecteurs de caractéristiques textuelles pour les fragments de document précédemment séparés à l'aide d'un modèle d'incorporation, puis les stocker dans une base de données vectorielle.
Ici, nous utilisons la base de données vectorielle par défaut "chroma" fournie par Langchain, puis utilisons le modèle d'incorporation openai.
- Remarque : Vous pouvez également choisir d'autres modèles open source comme remplacement pour le modèle d'incorporation.
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
Étape 4. Récupération (Interrogation des documents pertinents)
Récupérer les fragments de document liés à la question grâce à une recherche de similarité.
- Remarque : Le but de cette étape est de démontrer la fonction de recherche de similarité de la base de données vectorielle. La fonctionnalité de cette étape est automatiquement incluse dans la chaîne Q&R encapsulée par Langchain à la 5ème étape.
question = "Quelles sont les méthodes de décomposition des tâches ?"
docs = vectorstore.similarity_search(question)
len(docs)
4
Étape 5. Génération (Utilisation de l'IA pour répondre aux questions)
Utiliser le modèle LLM/Chat (par exemple, gpt-3.5-turbo) et la chaîne RetrievalQA pour condenser le document récupéré en une seule réponse.
- Astuce :
RetrievalQAest une chaîne encapsulée par LangChain, capable de mettre en œuvre une question-réponse IA basée sur une base de connaissances locale.
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectorstore.as_retriever())
qa_chain({"query": question})
{
'query': 'Quelles sont les méthodes de décomposition des tâches ?',
'result': 'Les méthodes de décomposition des tâches comprennent :\n\n1. Prompts simples : Cette méthode utilise des prompts ou des questions simples pour guider l'agent dans la décomposition de la tâche en sous-objectifs plus petits. Par exemple, l'agent peut être guidé avec "Étapes pour XYZ" et invité à énumérer les sous-objectifs pour réaliser XYZ.\n\n2. Instructions spécifiques à la tâche : Dans cette méthode, des instructions spécifiques à la tâche sont fournies pour guider le processus de décomposition pour l'agent. Par exemple, si la tâche est d'écrire un roman, l'agent peut être instruit de "Rédiger un synopsis de l'histoire" en tant que sous-objectif.\n\n3. Entrée humaine : Cette méthode implique l'intégration de l'entrée humaine dans le processus de décomposition des tâches. Les humains peuvent fournir des conseils, des retours et des suggestions pour aider l'agent à découper des tâches complexes en sous-objectifs gérables.\n\nCes méthodes visent à gérer efficacement des tâches complexes en les décomposant en parties plus petites et plus gérables.'
}
Notez que vous pouvez passer "LLM" ou "ChatModel" à la chaîne "RetrievalQA".
Astuce : Ce tutoriel utilise la chaîne intégrée
RetrievalQAdans LangChain pour mettre en œuvre une question-réponse basée sur les connaissances. En réalité, pour la nouvelle version de LangChain, en utilisant des expressions LangChain Expression Language (LCEL), il est facile de personnaliser une chaîne similaire de question-réponse. Veuillez vous référer à la section pertinente sur LCEL.
Modèle de prompt personnalisé
Lors de l'utilisation de la chaîne RetrievalQA précédemment, nous n'avons pas défini de mot de prompt et avons utilisé le modèle de mot de prompt intégré de langchain. Maintenant, personnalisons le modèle de mot de prompt.
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
template ="""Répondez à la question en vous basant sur le contexte ci-dessous.
Si vous ne connaissez pas la réponse, dites simplement "Je ne sais pas" et ne cherchez pas à inventer une réponse.
La réponse doit être en 3 phrases maximum et rester concise.
Terminez toujours par "Merci pour votre question !" à la fin de la réponse.
{context}
Question : {question}
Réponse : """
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)
result = qa_chain({"query": question})
result["result"]
Référence pour la réponse de l'IA aux questions et réponses
Utilisez RetrievalQAWithSourcesChain au lieu de RetrievalQA pour obtenir les réponses de l'IA basées sur le document source.
from langchain.chains import RetrievalQAWithSourcesChain
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(llm, retriever=vectorstore.as_retriever())
result = qa_chain({"question": question})
result
En partant de l'exemple précédent répondant aux questions en se basant sur des liens de blogs, les résultats retournés sont les suivants, nous permettant de voir que l'IA a répondu à la question en se basant sur une URL de blog spécifique :
{
'question': 'Quels sont les méthodes de décomposition des tâches?',
'answer': 'Les méthodes de décomposition des tâches incluent (1) l'utilisation de LLM et de simples instructions, (2) l'utilisation d'instructions spécifiques à la tâche, et (3) l'implication d'une entrée humaine en son sein.\n',
'sources': 'https://lilianweng.github.io/posts/2023-06-23-agent/'
}