Contoh Tanya Jawab AI Berdasarkan Basis Pengetahuan Lokal
Misalkan Anda memiliki beberapa dokumen teks (PDF, blog, data pribadi lokal, dll.) dan ingin membuat chatbot AI Tanya Jawab berdasarkan basis pengetahuan lokal. Mudah untuk menerapkan fungsionalitas ini menggunakan LangChain. Berikut adalah panduan langkah demi langkah tentang bagaimana mencapai fungsionalitas Q&A ini menggunakan LangChain.
- Catatan: Karena biaya tinggi untuk melatih LLM (large language model), basis pengetahuan dari large language model itu sendiri tidak akan sering diperbarui. AI hanya mengetahui konten yang telah dilatih dan tidak menyadari konten baru atau data pribadi perusahaan/pribadi, jadi penting untuk menggabungkan basis pengetahuan lokal dengan large language model.
Proses AI Q&A
-
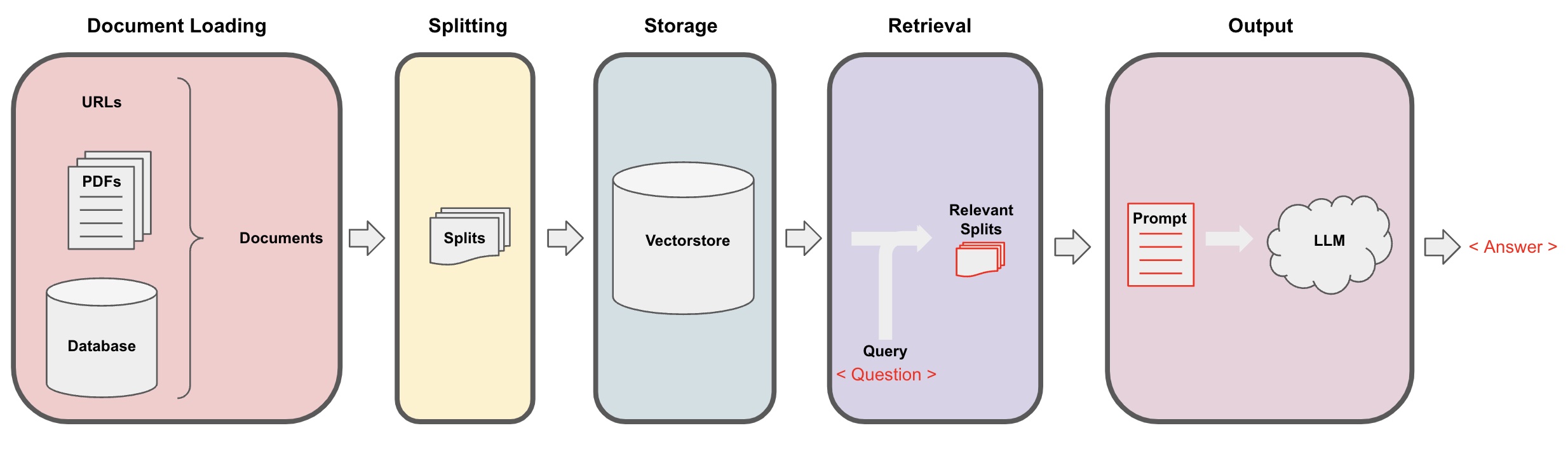
Pemuatan Dokumen: Pertama, kita perlu memuat data teks lokal kita, yang dapat dicapai menggunakan komponen pemuat (loader) dari LangChain. -
Pemisahan dokumen: Gunakan pemisah teks LangChain untuk membagi dokumen menjadi fragmen teks berukuran tertentu. (Catatan: Tujuan dari pemisahan teks adalah untuk memudahkan pencarian fragmen konten yang relevan berdasarkan pertanyaan. Alasan lain untuk pemisahan adalah bahwa large language model memiliki batas jumlah token maksimum.) -
Penyimpanan: Setelah membagi dokumen, hitung vektor fitur dokumen menggunakan model embedding dan kemudian simpan mereka di dalam basis data vektor. -
Pengambilan data: Berdasarkan pertanyaan, ajukan permintaan ke basis data vektor untuk mengambil fragmen dokumen yang serupa. -
Pembuatan: Gunakan rantai QA LangChain untuk melakukan Q&A, gabungkan fragmen dokumen yang terkait dengan pertanyaan beserta pertanyaan itu sendiri ke dalam prompt AI yang telah Anda desain, dan serahkan mereka ke LLM untuk menjawab pertanyaan. -
Percakapan(opsional): Dengan menambahkan komponen Memori ke dalam rantai QA, Anda dapat menambahkan fungsionalitas memori pesan historis AI untuk memudahkan dialog Q&A multi putaran.
Proses AI Q&A diilustrasikan dalam diagram berikut:
Memulai
Untuk memulai secara cepat, proses di atas dapat dibungkus dalam objek tunggal VectorstoreIndexCreator. Misalkan kita ingin membuat program Q&A berdasarkan blog post. Ini dapat dicapai dengan hanya beberapa baris kode:
- Catatan: Bab ini masih menggunakan large language model dari OpenAI.
Pertama, atur variabel lingkungan dan instal paket yang diperlukan:
pip install openai chromadb
export OPENAI_API_KEY="..."
Lalu jalankan:
from langchain_community.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
index = VectorstoreIndexCreator().from_loaders([loader])
Sekarang, mulailah bertanya:
index.query("Apa itu dekomposisi tugas?")
Dekomposisi tugas adalah teknik untuk memecah tugas kompleks menjadi langkah-langkah lebih kecil dan sederhana. Hal ini dapat dilakukan menggunakan LLM dengan prompt sederhana, instruksi khusus tugas, atau input manusia. Mindtrees (Yao et al.2023) adalah contoh dari teknik dekomposisi tugas, yang mengeksplorasi kemungkinan penalaran multiple setiap langkah dan menghasilkan banyak ide pada setiap langkah untuk membuat struktur pohon.
Program berjalan, tetapi bagaimana implementasinya di balik layar? Mari kita bahas prosesnya langkah per langkah.
Langkah 1. Memuat (Memuat Data Dokumen)
Tentukan DocumentLoader untuk memuat data yang ditentukan ke dalam objek Documents. Objek Document mewakili potongan teks (page_content) dan metadata terkait.
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
- Catatan: Langchain menyediakan berbagai pemuat untuk memudahkan pemuatan berbagai jenis data, yang dapat merujuk ke bab-bab sebelumnya.
Langkah 2. Memisahkan (Memisahkan Dokumen)
Karena prompt model besar memiliki batas token maksimum, kita tidak dapat melewati terlalu banyak konten dokumen ke AI. Biasanya sudah cukup untuk melewati fragmen dokumen yang relevan, jadi kita perlu memproses bagian potongan dokumen di sini.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 0)
all_splits = text_splitter.split_documents(data)
Langkah 3. Penyimpanan (Penyimpanan Vektor)
Untuk mencari fragmen dokumen yang relevan berdasarkan pertanyaan, kita perlu menghitung vektor fitur teks untuk fragmen dokumen yang sudah terpisah sebelumnya menggunakan model embedding, dan kemudian menyimpannya dalam basis data vektor.
Di sini kita menggunakan basis data vektor default "chroma" yang disediakan oleh Langchain, dan kemudian menggunakan model embedding openai.
- Catatan: Anda juga dapat memilih model open source lain sebagai pengganti untuk model embedding.
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
Langkah 4. Dapatkan (Pertanyaan Dokumen Terkait)
Dapatkan fragmen dokumen yang terkait dengan pertanyaan melalui pencarian kemiripan.
- Catatan: Tujuan langkah ini adalah untuk mendemonstrasikan fungsi pencarian kemiripan dari basis data vektor. Fungsi dari langkah ini sudah secara otomatis termasuk dalam rantai Q&A yang dienkapsulasi oleh Langchain dalam langkah ke-5.
pertanyaan = "Apa saja metode dekomposisi tugas?"
dokumen = vectorstore.similarity_search(pertanyaan)
len(dokumen)
4
Langkah 5. Hasilkan (Menggunakan KI untuk menjawab pertanyaan)
Gunakan model LLM/Chat (misalnya gpt-3.5-turbo) dan rantai RetrievalQA untuk merangkum dokumen yang didapatkan menjadi satu jawaban.
- Tip:
RetrievalQAadalah sebuah rantai yang dienkapsulasi oleh LangChain, mampu mengimplementasikan pertanyaan-jawaban KI berdasarkan basis pengetahuan lokal.
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectorstore.as_retriever())
qa_chain({"query": pertanyaan})
{
'query': 'Apa saja metode dekomposisi tugas?',
'result': 'Metode dekomposisi tugas meliputi:\n\n1. Tuntutan Sederhana: Metode ini memanfaatkan tuntutan sederhana atau pertanyaan untuk memandu agen dalam mendekomposisi tugas menjadi sub-target yang lebih kecil. Sebagai contoh, agen dapat diberi tuntutan "Langkah untuk XYZ" dan diminta untuk menyebutkan sub-target untuk mencapai XYZ.\n\n2. Petunjuk Khusus Tugas: Dalam metode ini, petunjuk khusus tugas disediakan untuk memandu proses dekomposisi bagi agen. Misalnya, jika tugasnya adalah menulis novel, agen dapat diinstruksikan untuk "Membuat draf garis besar cerita" sebagai sub-target.\n\n3. Masukan Manusia: Metode ini melibatkan pemberian masukan manusia ke dalam proses dekomposisi tugas. Manusia dapat memberikan bimbingan, umpan balik, dan saran untuk membantu agen dalam memecah tugas kompleks menjadi sub-target yang dapat dikelola.\n\nMetode-metode ini bertujuan untuk menangani tugas kompleks secara efisien dengan mendekomposisinya menjadi bagian yang lebih kecil, yang lebih dapat dikelola.'
}
Perhatikan bahwa Anda dapat melewatkan "LLM" atau "ChatModel" ke rantai "RetrievalQA".
Tip: Tutorial ini menggunakan rantai "RetrievalQA" bawaan dalam LangChain untuk mengimplementasikan pertanyaan-jawaban berbasis pengetahuan. Pada kenyataannya, untuk versi baru LangChain, menggunakan ekspresi Bahasa LangChain (LCEL), mudah untuk menyesuaikan rantai pertanyaan-jawaban serupa. Silakan merujuk ke bagian yang relevan tentang LCEL.
Template Promosi Kustom
Ketika menggunakan rantai RetrievalQA sebelumnya, kita tidak menyetel kata promosi dan menggunakan templat kata promosi bawaan dari langchain. Sekarang, mari kita kustomisasi templat kata promosi.
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
template ="""Jawablah pertanyaan berdasarkan konteks di bawah ini.
Jika Anda tidak tahu jawabannya, cukup katakan "Saya tidak tahu," dan jangan mencoba untuk membuat jawaban.
Jawabannya harus dalam 3 kalimat, dan singkat.
Selalu katakan "Terima kasih atas pertanyaannya!" di akhir jawaban.
{context}
Pertanyaan: {question}
Jawab: """
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)
hasil = qa_chain({"query": pertanyaan})
hasil["result"]
Referensi untuk Respon Pertanyaan dan Jawaban Kecerdasan Buatan
Gunakan RetrievalQAWithSourcesChain daripada RetrievalQA untuk mengembalikan jawaban AI berdasarkan dokumen mana.
from langchain.chains import RetrievalQAWithSourcesChain
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(llm, retriever=vectorstore.as_retriever())
result = qa_chain({"question": pertanyaan})
result
Mengembangkan contoh sebelumnya dalam menjawab pertanyaan berdasarkan tautan blog, hasil yang dikembalikan adalah sebagai berikut, memungkinkan kita untuk melihat bahwa AI menjawab pertanyaan berdasarkan URL blog tertentu:
{
'question': 'Apa saja metode untuk dekomposisi tugas?',
'answer': 'Metode dekomposisi tugas meliputi (1) menggunakan LLM dan petunjuk sederhana, (2) menggunakan instruksi khusus tugas, dan (3) melibatkan masukan manusia di dalamnya.\n',
'sources': 'https://lilianweng.github.io/posts/2023-06-23-agent/'
}