LLM स्मृति
अधिकांश LLM आधारित एप्लिकेशंस में वे-चैट इंटरफ़ेस की तरह है। AI वार्ता प्रक्रिया का एक महत्वपूर्ण कार्य है पिछले वार्ता में बोले गए जानकारी को संदर्भित करने की क्षमता, जबकि इंसान वार्ता प्रक्रिया में पिछली सामग्री को दोहराने की ज़रूरत नहीं होती। इंसान स्वचालित रूप से ऐतिहासिक जानकारी को याद करते हैं।
LLM क्षेत्र में ऐतिहासिक वार्ता सूचना को स्टोर करने की क्षमता को आम तौर पर "स्मृति" के रूप में संदर्भित किया जाता है, जैसे कि इंसान की स्मृति होती है। LangChain विभिन्न स्मृति कार्य के घटकों को एनकैप्सुलेट करता है, जो स्वतंत्र रूप से उपयोग किए जा सकते हैं या संयोजन से प्रयोग किए जा सकते हैं।
स्मृति घटकों को दो मूल आयामों - पढ़ना और लिखना - को अमल में लाने की आवश्यकता होती है।
LangChain के विभिन्न चेन कार्य घटकों के लिए यदि आप स्मृति कार्य को सक्षम करते हैं, तो यह संभावना है कि निम्नलिखित तरह का वैज्ञानिक तरह से काम करेगा:
- प्रारंभिक उपयोगकर्ता इनपुट प्राप्त करते समय, चेन टास्क स्मृति घटक से संबंधित ऐतिहासिक जानकारी का प्रश्न करने का प्रयास करेगा, और फिर इस ऐतिहासिक जानकारी और उपयोगकर्ता के इनपुट को प्रॉम्प्ट में जोड़कर, LLM को पार करने के लिए प्रेरित करेगा।
- LLM से वापसी सामग्री प्राप्त करते समय, यह स्वचालित रूप से स्मृति घटक में परिणाम स्टोर करेगा, ताकि आगे आसानी से पूछताछ की जा सके।
लैंगचैन में स्मृति क्षमता को लागू करने की प्रक्रिया नीचे दिए गए डायग्राम में दिखाई गई है:
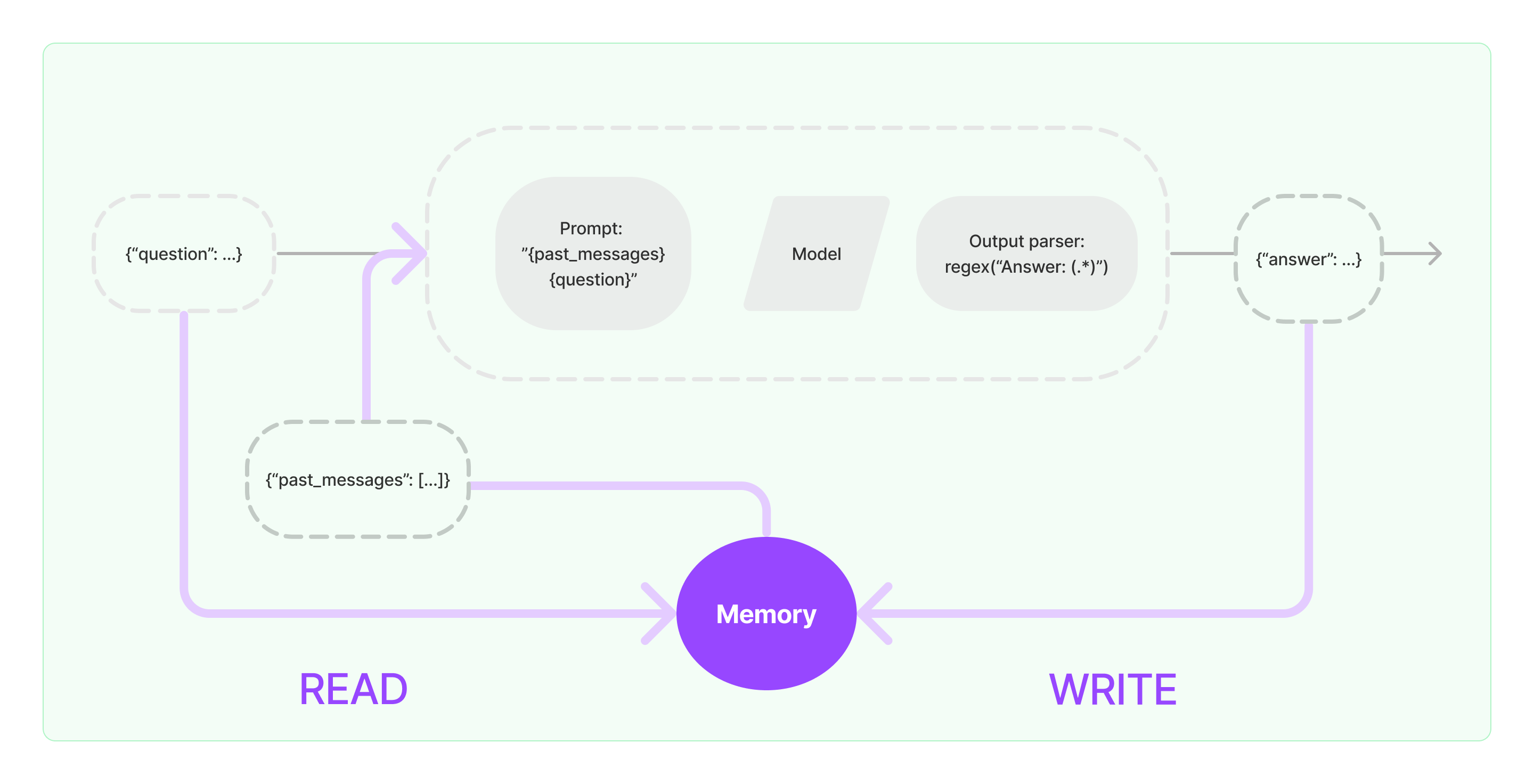
सिस्टम में स्मृति घटकों को सम्मिलित करना
स्मृति घटकों का उपयोग करने से पहले, निम्नलिखित दो सवालों का ध्यान रखना होगा:
- ऐतिहासिक संदेश डेटा को कैसे स्टोर करना है
- ऐतिहासिक संदेश डेटा का कैसे प्रश्न करना है
स्टोरेज: चैट संदेश सूची
अगर चैट मॉडल का प्रयोग किया जाए, तो वार्ता सामग्री एक चैट संदेशों की सूची होती है। LangChain ऐतिहासिक संदेश डेटा को स्टोर करने के लिए विभिन्न स्टोरेज इंजन समर्थन प्रदान करता है, सबसे सरल तरीका इसे मेमोरी में स्टोर करना होता है। व्यवहार में, सबसे आम तरीका इसे डेटाबेस में स्टोर करना होता है।
प्रश्न: वर्तमान वार्ता संदेशों को प्रश्न कैसे करें
LLM की स्मृति क्षमता को अमल में लाने के लिए, मुख्य रूप से होता है ऐतिहासिक संदेश सामग्री को प्रेरक सामग्री के रूप में जोड़ना। इस तरह, LLM उत्तर देते समय प्रेरक सामग्री का संदर्भ कर सकता है।
ऐतिहासिक संदेश सामग्री को स्टोर करना अल्प है, और एक अधिक चुनौतीपूर्ण आयाम वह है कि वर्तमान वार्ता सामग्री से संबंधित ऐतिहासिक संदेशों को कैसे प्रश्न पूछें। वर्तमान वार्ता से संबंधित ऐतिहासिक संदेशों का प्रश्न पूछने की मुख्य वजह, LLM की अधिकतम टोकन सीमा के कारण है; हम सभी ऐतिहासिक वार्ता सामग्री को प्रोम्प्ट में ठेल सकते हैं।
सामान्य ऐतिहासिक संदेश प्रश्न पूछने के रणनीतियों में शामिल है:
- केवल सबसे हाल के N संदेशों को प्रेरक सामग्री के रूप में पूछना
- ऐतिहासिक संदेशों का सार करने के लिए AI का उपयोग करना, सारांश प्रेरक सामग्री के रूप में
- वेक्टर डेटाबेस का उपयोग करके वर्तमान वार्ता के समान ऐतिहासिक संदेश पूछने के रूप में प्रेरक सामग्री के रूप में
from langchain_openai import ChatOpenAI
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = ChatOpenAI()
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"तुम एक अच्छे चैटबॉट हो जो एक मानव के साथ बातचीत कर रहे हो।"
),
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
conversation({"question": "नमस्ते"})