AI 기반 로컬 지식 베이스의 Q&A 예제
로컬 텍스트 문서(PDF, 블로그, 로컬 기밀 데이터 등)를 사용하여 로컬 지식 베이스에 기반한 AI Q&A 챗봇을 생성하고자 한다면, LangChain을 사용하여 이 기능을 쉽게 구현할 수 있습니다. 아래는 LangChain을 사용하여 이러한 Q&A 기능을 달성하는 방법에 대한 단계별 안내입니다.
- 참고: LLM(대형 언어 모델)의 훈련 비용이 높기 때문에, 대형 언어 모델의 지식 베이스 자체는 자주 업데이트되지 않을 것입니다. AI는 훈련된 내용만 알고 있으며 새로운 콘텐츠나 기관/개인 기밀 데이터에 대해 알지 못하므로, 로컬 지식 베이스를 대형 언어 모델과 결합하는 것이 필요합니다.
AI Q&A 과정
-
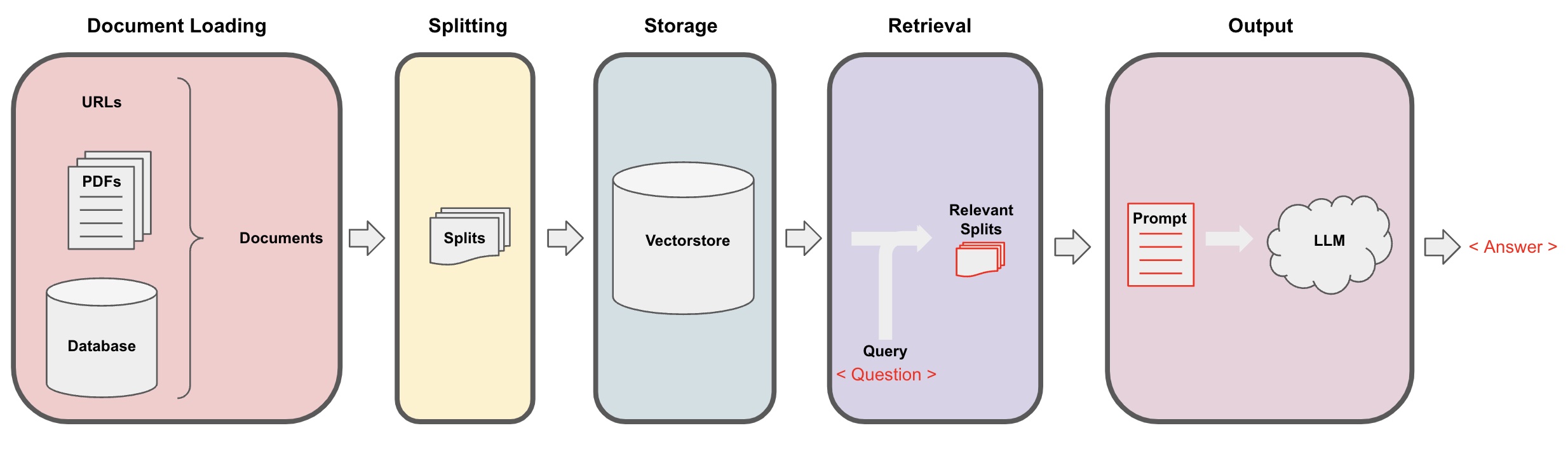
문서 로딩: 먼저, LangChain의 로더 구성 요소를 사용하여 로컬 텍스트 데이터를 로드해야 합니다. -
문서 분할: LangChain의 텍스트 분할기를 사용하여 문서를 지정된 크기의 텍스트 조각으로 분할합니다. (참고: 텍스트 분할의 목적은 질문에 기반하여 관련 콘텐츠 조각을 검색하기 쉽도록 하는 것입니다. 또 다른 이유는 대형 언어 모델의 최대 토큰 제한 때문입니다.) -
저장: 문서를 분할한 후, 임베딩 모델을 사용하여 문서 특징 벡터를 계산하고 이를 벡터 데이터베이스에 저장합니다. -
검색: 질문에 기반하여 벡터 데이터베이스를 쿼리하여 유사한 문서 조각을 검색합니다. -
생성: LangChain의 QA 체인을 사용하여 Q&A를 수행하고, 질문과 관련된 문서 조각을 AI 콕스 기준으로 연결하여 대형 언어 모델에 전달하여 질문에 답변합니다. -
대화(선택 사항): QA 체인에 메모리 구성 요소를 추가하여 AI의 과거 메시지 메모리 기능을 추가하여 다중 턴 Q&A 대화를 용이하게 할 수 있습니다.
AI Q&A 과정은 다음 다이어그램에 설명되어 있습니다:
시작하기
위의 과정을 단일 객체 "VectorstoreIndexCreator"에 포장하여 빠르게 시작할 수 있습니다. 이 블로그 포스트를 기반으로 한 QA Q&A 프로그램을 만들고자 한다고 가정해보겠습니다. 이를 몇 줄의 코드로 구현할 수 있습니다:
- 참고: 이 장에서는 여전히 OpenAI의 대형 언어 모델을 사용합니다.
먼저 환경 변수를 설정하고 필요한 패키지를 설치합니다:
pip install openai chromadb
export OPENAI_API_KEY="..."
그런 다음 실행합니다:
from langchain_community.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
index = VectorstoreIndexCreator().from_loaders([loader])
이제 질문을 시작합니다:
index.query("일각 분해란 무엇인가요?")
일각 분해는 복잡한 작업을 더 작고 간단한 단계로 분해하는 기술입니다. 간단한 콕스를 사용하거나 작업별 지침 또는 인간 입력을 사용하여 수행할 수 있습니다. Mindtrees(Yao et al.2023)는 일각 분해 기법의 한 예로, 각 단계에서 여러 추론 가능성을 탐색하고 각 단계에서 여러 아이디어를 생성하여 나무 구조를 생성합니다.
프로그램이 실행 중이지만, 이는 내부적으로 어떻게 구현되었을까요? 과정을 단계별로 살펴보겠습니다.
단계 1. 로딩 (문서 데이터 로딩)
지정된 데이터를 로드하기 위해 "DocumentLoader"를 지정하여 "Documents" 객체에 데이터를 로드합니다. "Document" 객체는 텍스트(page_content)와 관련 메타데이터를 나타냅니다.
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
- 참고: Langchain은 다양한 로더를 제공하여 다양한 유형의 데이터를 편리하게 로드할 수 있으며, 이에 대한 자세한 내용은 이전 장을 참조하십시오.
단계 2. 분할 (문서 분할)
대형 모델 콕스에는 최대 토큰 제한이 있기 때문에 AI에게 너무 많은 문서 콘텐츠를 전달할 수 없습니다. 일반적으로 관련 문서 조각을 전달하는 것이 충분하므로 여기서 문서 슬라이스를 처리해야 합니다.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 0)
all_splits = text_splitter.split_documents(data)
단계 3. 저장 (벡터 저장)
질문에 기반하여 관련 문서 단편을 조회하기 위해서, 이전에 분할된 문서 단편에 대한 텍스트 특징 벡터를 계산하고 벡터 데이터베이스에 저장해야 합니다.
여기서는 Langchain에서 제공하는 기본 벡터 데이터베이스 "chroma"를 사용하고, 그 후에 openai 임베딩 모델을 사용합니다.
- 참고: 임베딩 모델의 대체로 다른 오픈 소스 모델을 선택할 수도 있습니다.
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
단계 4. 조회 (관련 문서 검색)
유사성 검색을 통해 질문과 관련된 문서 단편을 검색합니다.
- 참고: 이 단계의 목적은 벡터 데이터베이스의 유사성 검색 기능을 보여주는 것입니다. 이 단계의 기능은 Langchain에 의해 자동으로 묶인 Q&A 체인에서 5단계에서 포함됩니다.
question = "작업 분해의 방법은 무엇인가요?"
docs = vectorstore.similarity_search(question)
len(docs)
4
단계 5. 생성 (AI를 사용하여 질문에 답변하기)
검색된 문서를 단일한 답변으로 요약하기 위해 LLM/Chat 모델 (예: gpt-3.5-turbo)과 RetrievalQA 체인을 사용합니다.
- 팁:
RetrievalQA는 로컬 지식 베이스를 기반으로 하는 AI 질문 응답을 구현하는 LangChain에 의해 묶인 체인입니다.
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectorstore.as_retriever())
qa_chain({"query": question})
{
'query': '작업 분해의 방법은 무엇인가요?',
'result': '작업 분해의 방법은 다음과 같습니다:\n\n1. 간단한 프롬프트: 이 방법은 작업을 더 작은 하위 목표로 세분화하기 위해 간단한 프롬프트나 질문을 사용합니다. 예를 들어, "XYZ에 대한 단계"와 같은 질문으로 에이전트에게 XYZ를 달성하기 위한 하위 목표를 나열하도록 할 수 있습니다.\n\n2. 작업별 지침: 이 방법은 에이전트의 작업 세분화 프로세스를 안내하기 위해 작업별 지침을 제공합니다. 예를 들어, 소설을 쓰는 작업의 경우, 에이전트에게 "이야기 개요 초안 작성"과 같은 하위 목표로 지시할 수 있습니다.\n\n3. 인간의 입력: 이 방법은 인간의 입력을 작업 분해 프로세스에 통합합니다. 인간은 복잡한 작업을 관리 가능한 하위 목표로 세분화하는 데 도움을 주기 위해 지침, 피드백 및 제안을 제공할 수 있습니다.\n\n이러한 방법은 복잡한 작업을 효율적으로 처리하기 위해 그것을 더 작고 관리하기 쉬운 부분으로 분해합니다.'
}
이 때 "LLM" 또는 "ChatModel"을 "RetrievalQA" 체인에 전달할 수 있습니다.
팁: 이 튜토리얼은 LangChain에 묶인 내장
RetrievalQA체인을 사용하여 지식 기반 질문 응답을 구현합니다. 실제로, LangChain의 새 버전에서는 LangChain 표현언어 (LCEL) 표현을 사용하여 비슷한 질문 응답 체인을 쉽게 사용자 정의할 수 있습니다. LCEL 관련 섹션을 참조해 주세요.
사용자 정의 프롬프트 템플릿
이전에 RetrievalQA 체인을 사용할 때, 프롬프트 단어를 설정하지 않고 langchain의 내장 프롬프트 단어 템플릿을 사용했습니다. 이제 프롬프트 워드 템플릿을 사용자 정의해 봅시다.
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
template ="""아래 컨텍스트를 기반으로 질문에 답변해 주세요.
답을 모르는 경우 "모르겠어요"라고 말하고, 대답을 꾸미려고 하지 마세요.
답변은 3문장 이내로 간결하게 해 주세요.
답변의 끝에는 항상 "질문해 주셔서 감사합니다!"라고 말해 주세요.
{context}
질문: {question}
답변: """
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)
result = qa_chain({"query": question})
result["result"]
from langchain.chains import RetrievalQAWithSourcesChain
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(llm, retriever=vectorstore.as_retriever())
result = qa_chain({"question": question})
result
이전 블로그 링크를 기반으로 질문에 답변하는 예제를 보완하여, 반환된 결과는 다음과 같습니다. 이를 통해 AI가 특정 블로그 URL을 기반으로 질문에 답변했음을 확인할 수 있습니다.
{
'question': '작업 분해를 위한 방법은 무엇인가요?',
'answer': '작업 분해 방법에는 (1) LLM과 간단한 프롬프트 사용, (2) 작업 특정 지침 사용, (3) 그 안에 인간 입력을 포함하는 것 등이 있습니다.\n',
'sources': 'https://lilianweng.github.io/posts/2023-06-23-agent/'
}