Хранилище векторов
- Перейдите на Интеграции, чтобы узнать о всех сторонних движках хранения векторов, официально поддерживаемых LangChain.
Самым распространенным решением для хранения и поиска неструктурированных данных является вычисление векторных признаков данных, а затем поиск похожих векторов на основе их сходства при запросе. Векторная база данных отвечает за предоставление движков хранения данных для хранения и запросов по векторам.
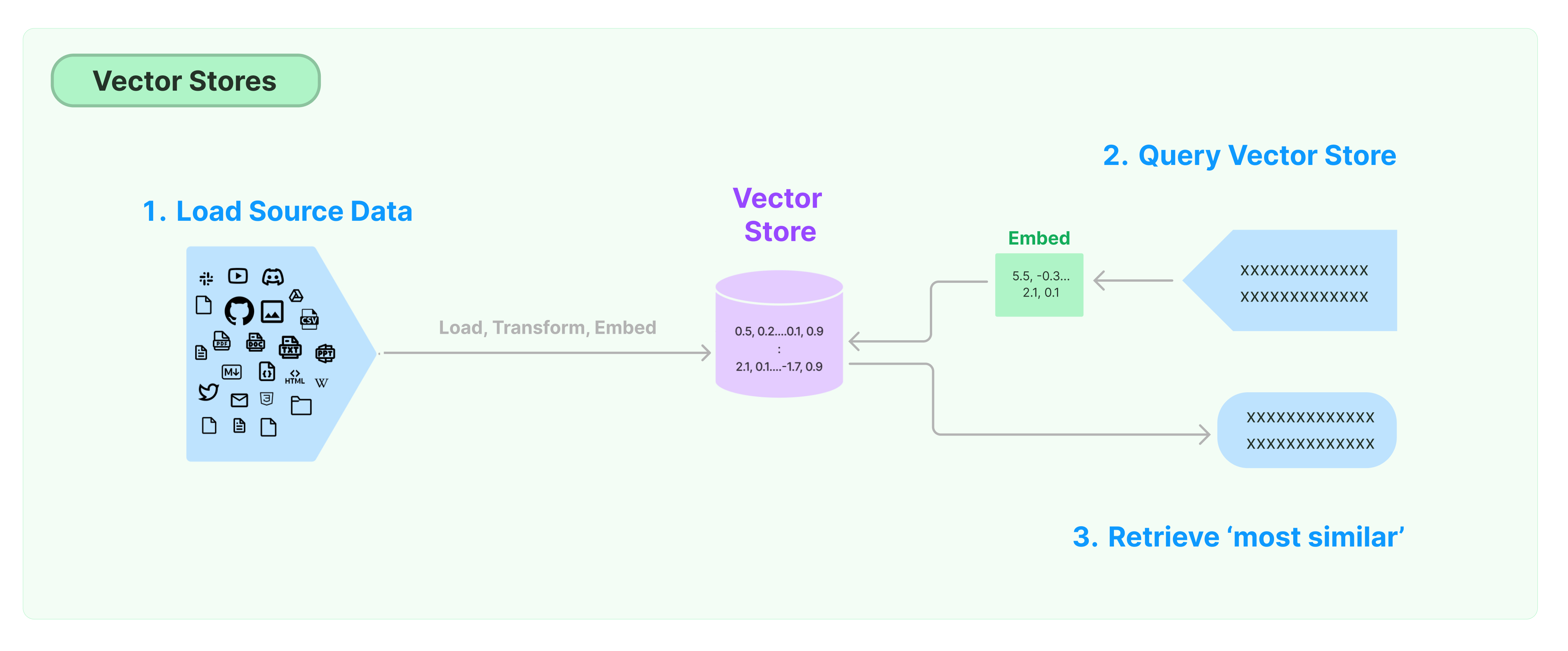
Начало работы с LangChain Vector Store
Это руководство представляет основные функциональные возможности, связанные с Хранилищами Векторов. Основным компонентом работы с векторным хранилищем является модель эмбеддинга (отвественная за вычисление векторов признаков). Поэтому рекомендуется изучить как рассчитывать текстовые векторы с помощью модели эмбеддинга текста перед изучением этой главы.
Существует много отличных движков хранения векторов. Ниже мы представляем использование 3 бесплатных и открытых движков хранения векторов в рамках фреймворка LangChain.
Chroma
В этой главе используется векторная база данных chroma, которая работает локально как библиотека Python.
pip install chromadb
Здесь мы используем модель эмбеддинга OpenAI для расчета векторов, поэтому нам потребуется получить ключ API OpenAI.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('Ключ API OpenAI:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
FAISS
В этой главе используется векторная база данных FAISS, которая использует библиотеку Facebook AI Similarity Search (FAISS).
pip install faiss-cpu
Здесь мы используем модель эмбеддинга OpenAI для расчета векторов, поэтому нам потребуется получить ключ API OpenAI.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('Ключ API OpenAI:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = FAISS.from_documents(documents, OpenAIEmbeddings())
Lance
В этой главе мы рассмотрим, как фреймворк LangChain использует векторную базу данных LanceDB.
pip install lancedb
Здесь мы используем модель эмбеддинга OpenAI для расчета векторов, поэтому нам потребуется получить ключ API OpenAI.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('Ключ API OpenAI:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import LanceDB
import lancedb
db = lancedb.connect("/tmp/lancedb")
table = db.create_table(
"my_table",
data=[
{
"vector": embeddings.embed_query("Hello World"),
"text": "Hello World",
"id": "1",
}
],
mode="overwrite",
)
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = LanceDB.from_documents(documents, OpenAIEmbeddings(), connection=table)
Поиск похожих векторов
query = "Что президент сказал Кетанджи Браун Джексон?"
docs = db.similarity_search(query)
print(docs[0].page_content)
Поиск сходства векторов
Используйте similarity_search_by_vector для выполнения поиска сходства на основе предоставленного вектора. Эта функция принимает вектор вложения в качестве параметра, а не строку.
embedding_vector = OpenAIEmbeddings().embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
print(docs[0].page_content)
Асинхронные операции
Хранение векторов часто работает как самостоятельный сервис и требует некоторых операций ввода-вывода. Поэтому используйте асинхронные вызовы к интерфейсу базы данных векторов. Это может улучшить производительность, так как вам не нужно тратить время на ожидание ответов от внешних сервисов.
Langchain поддерживает асинхронные операции для хранения векторов. Все методы могут быть вызваны с использованием своих асинхронных функций с префиксом a, указывающим async.
Qdrant - это хранилище векторов, которое поддерживает все асинхронные операции. Ниже приведен пример использования Qdrant.
pip install qdrant-client
from langchain_community.vectorstores import Qdrant
Создание асинхронного хранилища векторов
db = await Qdrant.afrom_documents(documents, embeddings, "http://localhost:6333")
Поиск по сходству
query = "What did the President say to Ketanji Brown Jackson?"
docs = await db.asimilarity_search(query)
print(docs[0].page_content)
Поиск на основе векторов
embedding_vector = embeddings.embed_query(query)
docs = await db.asimilarity_search_by_vector(embedding_vector)
Поиск с максимальной краевой релевантностью (MMR)
Максимальная краевая релевантность оптимизирует сходство с запросом и разнообразие между выбранными документами. Он также поддерживает асинхронный API.
query = "What did the President say to Ketanji Brown Jackson?"
found_docs = await qdrant.amax_marginal_relevance_search(query, k=2, fetch_k=10)
for i, doc in enumerate(found_docs):
print(f"{i + 1}.", doc.page_content, "\n")