Almacenamiento de Vectores
- Ve a Integraciones para conocer todas las plataformas de almacenamiento de vectores de terceros oficialmente admitidas por LangChain.
La solución más común para almacenar y buscar datos no estructurados es calcular vectores de características de los datos y luego buscar vectores similares basados en la similitud de vectores al realizar consultas. Una base de datos de vectores es responsable de proporcionar motores de almacenamiento de datos para almacenar y consultar vectores.
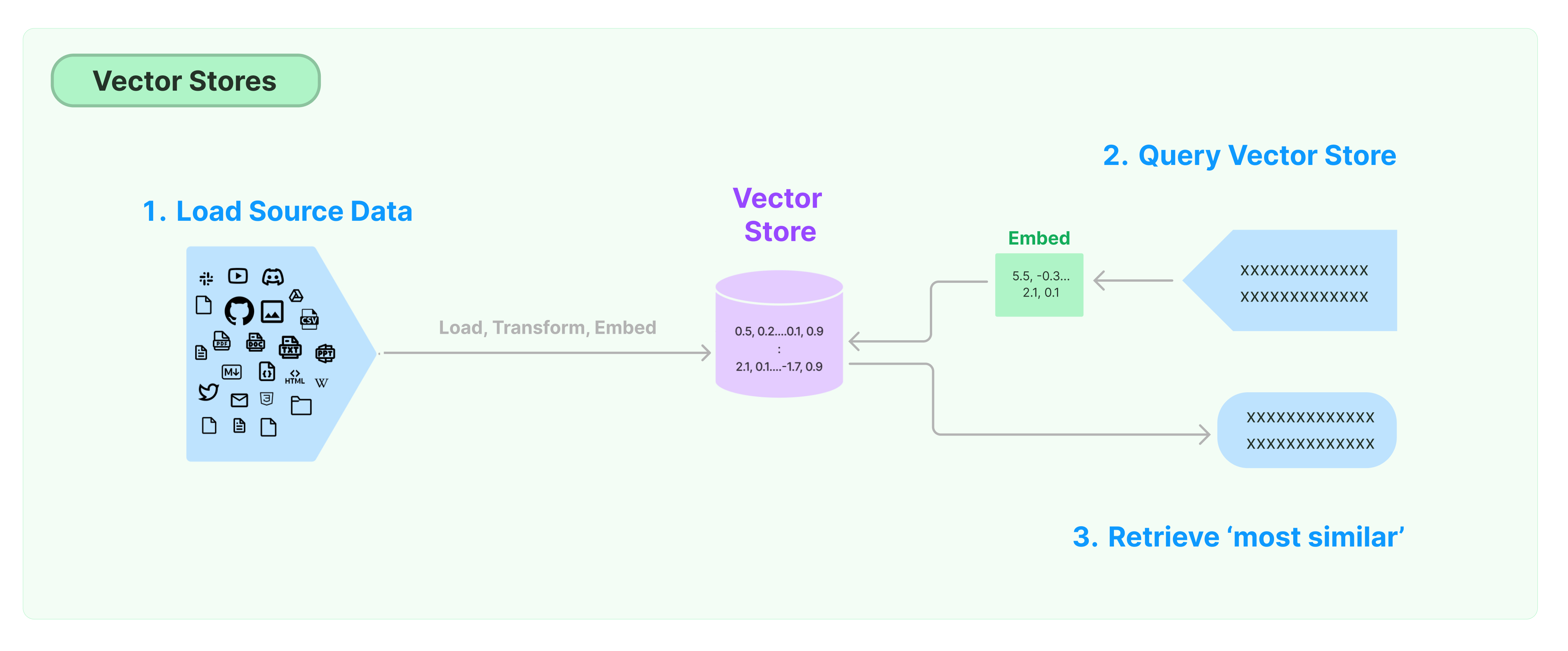
Primeros Pasos con LangChain Vector Store
Esta guía presenta las funcionalidades básicas relacionadas con Vector Stores. El componente clave para trabajar con el almacenamiento de vectores es el modelo de incrustación (responsable de calcular vectores de características). Por lo tanto, se recomienda aprender cómo calcular vectores de texto con el modelo de incrustación de texto antes de estudiar este capítulo.
Existen muchos motores de almacenamiento de vectores excelentes. A continuación, presentamos el uso de 3 motores de almacenamiento de vectores gratuitos y de código abierto en el marco de LangChain.
Chroma
En este capítulo se utiliza la base de datos de vectores chroma, que se ejecuta localmente como una librería de Python.
pip install chromadb
Aquí, utilizamos el modelo de incrustación de OpenAI para calcular los vectores, por lo que necesitamos obtener la clave API de OpenAI.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('Clave API de OpenAI:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
FAISS
En este capítulo se utiliza la base de datos de vectores FAISS, que utiliza la biblioteca Facebook AI Similarity Search (FAISS).
pip install faiss-cpu
Aquí, utilizamos el modelo de incrustación de OpenAI para calcular los vectores, por lo que necesitamos obtener la clave API de OpenAI.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('Clave API de OpenAI:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = FAISS.from_documents(documents, OpenAIEmbeddings())
Lance
En este capítulo, presentaremos cómo el marco de LangChain utiliza la base de datos de vectores LanceDB.
pip install lancedb
Aquí, utilizamos el modelo de incrustación de OpenAI para calcular vectores, por lo que necesitamos obtener la clave API de OpenAI.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('Clave API de OpenAI:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import LanceDB
import lancedb
db = lancedb.connect("/tmp/lancedb")
table = db.create_table(
"mi_tabla",
data=[
{
"vector": embeddings.embed_query("Hola Mundo"),
"texto": "Hola Mundo",
"id": "1",
}
],
mode="sobrescribir",
)
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = LanceDB.from_documents(documents, OpenAIEmbeddings(), connection=table)
Búsqueda de Similitud
consulta = "¿Qué le dijo el Presidente a Ketanji Brown Jackson?"
docs = db.similarity_search(consulta)
print(docs[0].contenido_pagina)
Búsqueda de similitud de vectores
Utilice similarity_search_by_vector para realizar una búsqueda de similitud basada en el vector proporcionado. Esta función toma un vector de incrustación como parámetro en lugar de una cadena.
vector_de_incrustación = OpenAIEmbeddings().embed_query(consulta)
docs = db.similarity_search_by_vector(vector_de_incrustación)
print(docs[0].page_content)
Operaciones Asíncronas
El almacenamiento de vectores a menudo se ejecuta como un servicio independiente y requiere algunas operaciones de E/S. Por lo tanto, utilice llamadas asíncronas a la interfaz de la base de datos de vectores. Esto puede mejorar el rendimiento ya que no tiene que perder tiempo esperando respuestas de servicios externos.
Langchain admite operaciones asíncronas para el almacenamiento de vectores. Todos los métodos pueden ser llamados utilizando sus funciones asíncronas con el prefijo a, indicando async.
Qdrant es un almacenamiento de vectores que admite todas las operaciones asincrónicas. A continuación se muestra un ejemplo utilizando Qdrant.
pip install qdrant-client
from langchain_community.vectorstores import Qdrant
Creación de almacenamiento de vectores asíncrono
db = await Qdrant.afrom_documents(documents, embeddings, "http://localhost:6333")
Búsqueda de similitud
consulta = "¿Qué dijo el presidente a Ketanji Brown Jackson?"
docs = await db.asimilarity_search(consulta)
print(docs[0].page_content)
Búsqueda basada en vectores
vector_de_incrustación = embeddings.embed_query(consulta)
docs = await db.asimilarity_search_by_vector(vector_de_incrustación)
Búsqueda de Máximo Margen de Relevancia (MMR)
El Máximo Margen de Relevancia optimiza la similitud con la consulta y la diversidad entre los documentos seleccionados. También admite una API asíncrona.
consulta = "¿Qué dijo el presidente a Ketanji Brown Jackson?"
docs_encontrados = await qdrant.amax_marginal_relevance_search(consulta, k=2, fetch_k=10)
for i, doc in enumerate(docs_encontrados):
print(f"{i + 1}.", doc.page_content, "\n")