Sklep z Wektorami
- Przejdź do Integracji, aby dowiedzieć się o wszystkich oficjalnie obsługiwanych silnikach przechowywania wektorów firm trzecich przez LangChain.
Najczęstszym rozwiązaniem do przechowywania i wyszukiwania danych niestrukturyzowanych jest obliczanie wektorów cech danych, a następnie wyszukiwanie podobnych wektorów na podstawie podobieństwa wektorów podczas zapytań. Baza danych wektorów jest odpowiedzialna za dostarczanie silników przechowywania danych do przechowywania i wyszukiwania wektorów.
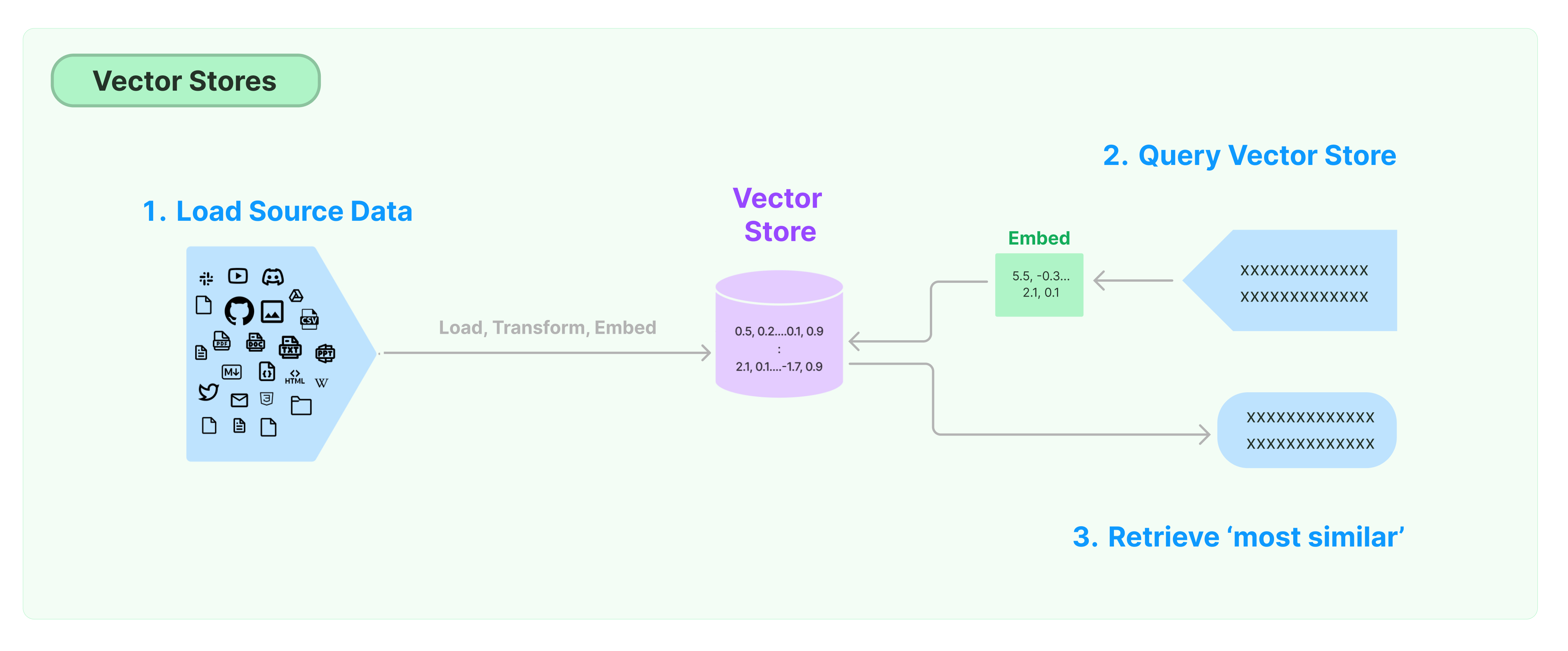
Rozpoczęcie pracy z Sklepem Wektorów LangChain
Przewodnik ten wprowadza podstawowe funkcje związane ze Sklepami Wektorów. Kluczowym komponentem współpracującym z przechowywaniem wektorów jest model zagnieżdżenia (odpowiedzialny za obliczanie wektorów cech). Dlatego zaleca się nauczenie się, jak obliczać wektory tekstowe z modelu zagnieżdżenia tekstu przed zgłębieniem tego rozdziału.
Istnieje wiele doskonałych silników przechowywania wektorów. Poniżej przedstawiamy sposób korzystania z trzech darmowych i otwartych silników przechowywania wektorów w ramach platformy LangChain.
Chroma
W tym rozdziale używamy bazy danych wektorów chroma, która działa lokalnie jako biblioteka Python.
pip install chromadb
Tutaj używamy modelu zagnieżdżenia OpenAI do obliczania wektorów, więc musimy uzyskać klucz API OpenAI.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('Klucz API OpenAI:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
FAISS
W tym rozdziale używamy bazy danych wektorów FAISS, która wykorzystuje bibliotekę Facebook AI Similarity Search (FAISS).
pip install faiss-cpu
Tutaj używamy modelu zagnieżdżenia OpenAI do obliczania wektorów, więc musimy uzyskać klucz API OpenAI.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('Klucz API OpenAI:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = FAISS.from_documents(documents, OpenAIEmbeddings())
Lance
W tym rozdziale przedstawimy, jak framework LangChain wykorzystuje bazę danych wektorów LanceDB.
pip install lancedb
Tutaj używamy modelu zagnieżdżenia OpenAI do obliczania wektorów, więc musimy uzyskać klucz API OpenAI.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('Klucz API OpenAI:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import LanceDB
import lancedb
db = lancedb.connect("/tmp/lancedb")
table = db.create_table(
"my_table",
data=[
{
"vector": embeddings.embed_query("Hello World"),
"text": "Hello World",
"id": "1",
}
],
mode="overwrite",
)
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = LanceDB.from_documents(documents, OpenAIEmbeddings(), connection=table)
Wyszukiwanie podobieństwa
zapytanie = "Co prezydent powiedział Ketanji Brown Jackson?"
dokumenty = db.similarity_search(zapytanie)
print(dokumenty[0].page_content)
Wyszukiwanie podobieństw wektorowych
Aby wykonać wyszukiwanie podobieństw na podstawie danego wektora, użyj funkcji similarity_search_by_vector. Ta funkcja przyjmuje wektor osadzenia jako parametr, a nie ciąg znaków.
wektor_osadzenia = OpenAIEmbeddings().embed_query(zapytanie)
dokumenty = db.similarity_search_by_vector(wektor_osadzenia)
print(dokumenty[0].page_content)
Operacje asynchroniczne
Przechowywanie wektorów często działa jako niezależna usługa i wymaga pewnych operacji wejścia-wyjścia. Dlatego używaj asynchronicznych wywołań interfejsu bazy danych wektorowej. Może to poprawić wydajność, ponieważ nie trzeba czekać na odpowiedzi z zewnętrznych usług.
Langchain obsługuje operacje asynchroniczne dla przechowywania wektorów. Wszystkie metody można wywołać za pomocą ich funkcji asynchronicznych z prefiksem a, oznaczających async.
Qdrant to przechowywanie wektorów, które obsługuje wszystkie operacje asynchroniczne. Poniżej znajduje się przykład użycia Qdrant.
pip install qdrant-client
from langchain_community.vectorstores import Qdrant
Tworzenie asynchronicznego przechowywania wektorów
db = await Qdrant.afrom_documents(dokumenty, osadzenia, "http://localhost:6333")
Wyszukiwanie podobieństw
zapytanie = "Co prezydent powiedział do Ketanji Brown Jackson?"
dokumenty = await db.asimilarity_search(zapytanie)
print(dokumenty[0].page_content)
Wyszukiwanie oparte na wektorach
wektor_osadzenia = osadzenia.embed_query(zapytanie)
dokumenty = await db.asimilarity_search_by_vector(wektor_osadzenia)
Wyszukiwanie maksymalnej marginesowej zależności (MMR)
Maksymalna marginesowa zależność optymalizuje podobieństwo do zapytania i zróżnicowanie między wybranymi dokumentami. Obsługuje również interfejs asynchroniczny.
zapytanie = "Co prezydent powiedział do Ketanji Brown Jackson?"
znalezione_dokumenty = await qdrant.amax_marginal_relevance_search(zapytanie, k=2, fetch_k=10)
for i, doc in enumerate(znalezione_dokumenty):
print(f"{i + 1}.", doc.page_content, "\n")