متجر الفيكتور
- انتقل إلى التكاملات لمعرفة كافة محركات تخزين الفيكتورات الخارجية المدعومة رسميًا من قبل لانغتشاين.
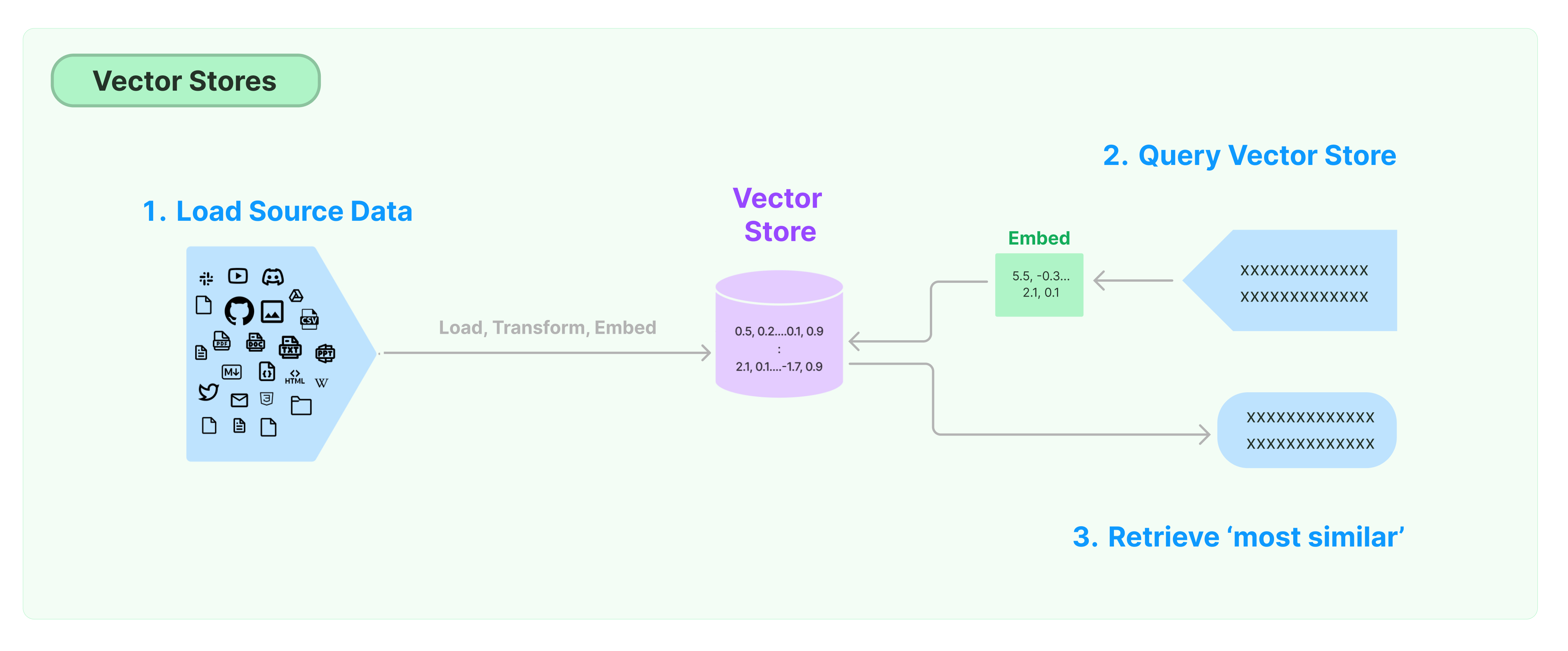
أحد أكثر الحلول شيوعًا لتخزين والبحث في البيانات غير المهيكلة هو حساب فيكتورات السمات للبيانات، ثم البحث عن فيكتورات مماثلة بناءً على التشابه الفيكتوري عند الاستعلام. قاعدة بيانات الفيكتورات مسؤولة عن توفير محركات تخزين البيانات لتخزين واستعلام الفيكتورات.
البدء مع مخزن الفيكتورات في لانغتشاين
يقدم هذا الدليل الوظائف الأساسية المتعلقة بمخازن الفيكتورات. المكون الرئيسي العامل مع تخزين الفيكتورات هو نموذج التضمين (المسؤول عن حساب فيكتورات السمات). لذلك، من المستحسن تعلم كيفية حساب فيكتورات النصوص باستخدام نموذج تضمين النصوص قبل دراسة هذا الفصل.
هناك العديد من محركات تخزين الفيكتورات الممتازة. فيما يلي، نقدم استخدام 3 محركات تخزين الفيكتورات المجانية ومفتوحة المصدر في إطار لانغتشاين.
كروما
في هذا الفصل، سنستخدم قاعدة بيانات الفيكتورات كروما، والتي تعمل محليًا كمكتبة Python.
pip install chromadb
هنا، سنستخدم نموذج تضمين OpenAI لحساب الفيكتورات، لذا نحتاج إلى الحصول على مفتاح API الخاص بـ OpenAI.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
فايس
في هذا الفصل، سنستخدم قاعدة بيانات الفيكتورات فايس، والتي تستخدم مكتبة Facebook AI Similarity Search (FAISS).
pip install faiss-cpu
هنا، سنستخدم نموذج تضمين OpenAI لحساب الفيكتورات، لذا نحتاج إلى الحصول على مفتاح API الخاص بـ OpenAI.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = FAISS.from_documents(documents, OpenAIEmbeddings())
لانس
في هذا الفصل، سنقدم كيفية استخدام إطار لانغتشاين لقاعدة بيانات الفيكتورات LanceDB.
pip install lancedb
هنا، سنستخدم نموذج تضمين OpenAI لحساب الفيكتورات، لذا نحتاج إلى الحصول على مفتاح API الخاص بـ OpenAI.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import LanceDB
import lancedb
db = lancedb.connect("/tmp/lancedb")
table = db.create_table(
"my_table",
data=[
{
"vector": embeddings.embed_query("Hello World"),
"text": "Hello World",
"id": "1",
}
],
mode="overwrite",
)
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = LanceDB.from_documents(documents, OpenAIEmbeddings(), connection=table)
البحث عن التشابه
query = "ماذا قال الرئيس لكيتانجي براون جاكسون؟"
docs = db.similarity_search("ماذا قال الرئيس لكيتانجي براون جاكسون؟")
print(docs[0].page_content)
البحث عن التشابه العام
استخدم similarity_search_by_vector لإجراء البحث عن التشابه بناءً على الناقل المعطى. تأخذ هذه الوظيفة ناقل تضمين كمعلمة بدلاً من سلسلة.
embedding_vector = OpenAIEmbeddings().embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
print(docs[0].page_content)
العمليات الغير متزامنة
يعمل تخزين النواقص بصورة مستقلة غالبًا ويتطلب بعض عمليات الإدخال/الإخراج. لذلك ، استخدم الاستدعاءات الغير متزامنة لواجهة قاعدة البيانات الناقصة. يمكن أن يحسن هذا الأداء حيث لا داعي لإضاعة الوقت في انتظار الردود من الخدمات الخارجية.
يدعم Langchain العمليات الغير متزامنة لتخزين النواقص. يمكن استدعاء جميع الأساليب باستخدام وظائفها الغير متزامنة ببادئة a ، مما يشير إلى async.
Qdrant هو تخزين نواقص يدعم جميع العمليات الغير متزامنة. فيما يلي مثال باستخدام Qdrant.
pip install qdrant-client
from langchain_community.vectorstores import Qdrant
إنشاء تخزين نواقص غير متزامن
db = await Qdrant.afrom_documents(documents, embeddings, "http://localhost:6333")
البحث عن التشابه
query = "ماذا قال الرئيس لـ كيتانجي براون جاكسون؟"
docs = await db.asimilarity_search(query)
print(docs[0].page_content)
البحث بناءً على الناقل
embedding_vector = embeddings.embed_query(query)
docs = await db.asimilarity_search_by_vector(embedding_vector)
البحث بناءً على النواقص القائم
يقوم Maximal Marginal Relevance بتحسين التشابه مع الاستعلام والتنوع بين الوثائق المحددة. كما يدعم واجهة برمجة التطبيقات الغير متزامنة.
query = "ماذا قال الرئيس لـ كيتانجي براون جاكسون؟"
found_docs = await qdrant.amax_marginal_relevance_search(query, k=2, fetch_k=10)
for i, doc in enumerate(found_docs):
print(f"{i + 1}.", doc.page_content, "\n")