Cửa Hàng Vector
- Đi đến Tích hợp để tìm hiểu về tất cả những hệ thống lưu trữ vector từ bên thứ ba được hỗ trợ chính thức bởi LangChain.
Giải pháp phổ biến nhất cho việc lưu trữ và tìm kiếm dữ liệu không cấu trúc là tính toán vector đặc trưng của dữ liệu, và sau đó tìm kiếm các vector tương tự dựa trên sự tương đồng vector khi truy vấn. Cơ sở dữ liệu vector chịu trách nhiệm cung cấp các hệ thống lưu trữ dữ liệu để lưu trữ và truy vấn các vector.
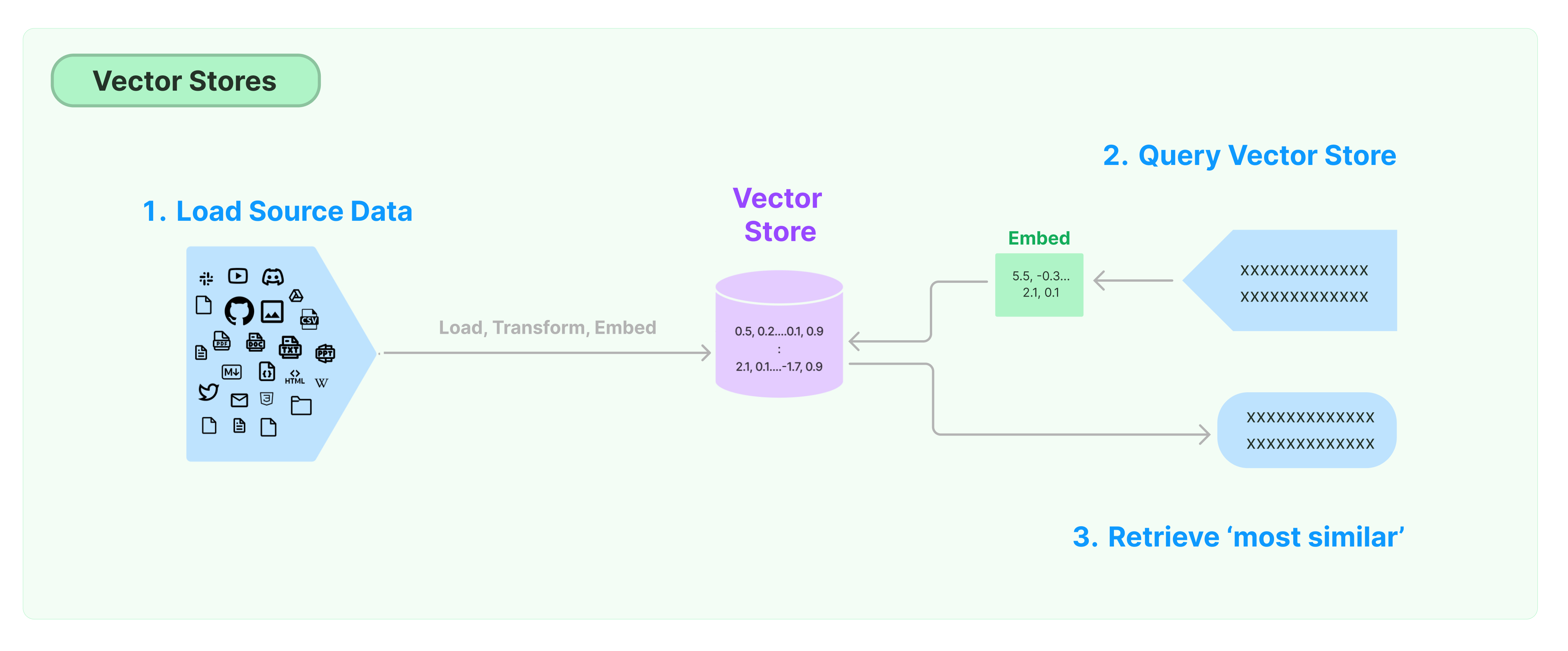
Bắt Đầu với Cửa Hàng Vector của LangChain
Hướng dẫn này giới thiệu về các chức năng cơ bản liên quan đến Cửa Hàng Vector. Thành phần chính làm việc với cửa hàng vector là mô hình nhúng (chịu trách nhiệm tính toán vector đặc trưng). Do đó, được khuyến nghị học cách tính toán vector văn bản với mô hình nhúng văn bản trước khi nghiên cứu chương này.
Có nhiều hệ thống lưu trữ vector tuyệt vời. Bên dưới, chúng tôi giới thiệu cách sử dụng 3 hệ thống lưu trữ vector miễn phí và mã nguồn mở trong khung công việc LangChain.
Chroma
Chương này sử dụng cơ sở dữ liệu vector chroma, chạy cục bộ như một thư viện Python.
pip install chromadb
Ở đây, chúng tôi sử dụng mô hình nhúng OpenAI để tính toán các vector, vì vậy chúng ta cần thu được khóa API từ OpenAI.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('Khóa API của OpenAI:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
FAISS
Chương này sử dụng cơ sở dữ liệu vector FAISS, sử dụng thư viện Tìm kiếm Tương đồng Trí Tuệ Nhân tạo (FAISS) của Facebook.
pip install faiss-cpu
Ở đây, chúng tôi sử dụng mô hình nhúng OpenAI để tính toán các vector, vì vậy chúng ta cần thu được khóa API từ OpenAI.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('Khóa API của OpenAI:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = FAISS.from_documents(documents, OpenAIEmbeddings())
Lance
Trong chương này, chúng tôi sẽ giới thiệu cách khung công việc LangChain sử dụng Cơ sở dữ liệu vector LanceDB.
pip install lancedb
Ở đây, chúng tôi sử dụng mô hình nhúng của OpenAI để tính toán vector, vì vậy chúng ta cần thu được khóa API từ OpenAI.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('Khóa API của OpenAI:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import LanceDB
import lancedb
db = lancedb.connect("/tmp/lancedb")
table = db.create_table(
"my_table",
data=[
{
"vector": embeddings.embed_query("Xin chào Thế Giới"),
"text": "Xin chào Thế Giới",
"id": "1",
}
],
mode="overwrite",
)
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = LanceDB.from_documents(documents, OpenAIEmbeddings(), connection=table)
Tìm Kiếm Tương Đồng
truy vấn = "Tổng thống nói gì với Ketanji Brown Jackson?"
tài liệu = db.similarity_search(query)
in tài liệu[0].Nội_dung_trang)
Tìm kiếm Độ tương đồng Vector
Sử dụng similarity_search_by_vector để thực hiện tìm kiếm độ tương đồng dựa trên vector đã cho. Hàm này nhận vector nhúng làm tham số thay vì một chuỗi.
embedding_vector = OpenAIEmbeddings().embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
print(docs[0].page_content)
Các Hoạt động Bất đồng bộ
Lưu trữ Vector thường chạy như một dịch vụ độc lập và yêu cầu một số hoạt động IO. Do đó, sử dụng cuộc gọi bất đồng bộ đến giao diện cơ sở dữ liệu vector. Điều này có thể cải thiện hiệu suất vì bạn không cần phí thời gian đợi phản hồi từ các dịch vụ bên ngoài.
Langchain hỗ trợ các hoạt động bất đồng bộ cho việc lưu trữ vector. Tất cả các phương thức có thể được gọi bằng các hàm bất đồng bộ của chúng với tiền tố a, chỉ dẫn async.
Qdrant là một lưu trữ vector hỗ trợ tất cả các hoạt động bất đồng bộ. Dưới đây là ví dụ sử dụng Qdrant.
pip install qdrant-client
from langchain_community.vectorstores import Qdrant
Tạo Lưu trữ Vector Bất đồng bộ
db = await Qdrant.afrom_documents(documents, embeddings, "http://localhost:6333")
Tìm kiếm Độ tương đồng
query = "Tổng thống nói gì với Ketanji Brown Jackson?"
docs = await db.asimilarity_search(query)
print(docs[0].page_content)
Tìm kiếm Dựa trên Vector
embedding_vector = embeddings.embed_query(query)
docs = await db.asimilarity_search_by_vector(embedding_vector)
Tìm kiếm Dựa Trên Biên Độ Lớn Nhất (Maximal Marginal Relevance - MMR)
Tìm kiếm Biên độ lớn nhất cực đại hóa độ tương đồng với truy vấn và sự đa dạng giữa các tài liệu được chọn. Nó cũng hỗ trợ một API bất đồng bộ.
query = "Tổng thống nói gì với Ketanji Brown Jackson?"
found_docs = await qdrant.amax_marginal_relevance_search(query, k=2, fetch_k=10)
for i, doc in enumerate(found_docs):
print(f"{i + 1}.", doc.page_content, "\n")