Armazenamento de Vetor
- Acesse Integrações para conhecer todos os mecanismos de armazenamento de vetor de terceiros oficialmente suportados pela LangChain.
A solução mais comum para armazenar e pesquisar dados não estruturados é calcular vetores de características dos dados e, em seguida, buscar vetores semelhantes com base na semelhança de vetores ao fazer consultas. Um banco de dados de vetor é responsável por fornecer mecanismos de armazenamento de dados para armazenar e consultar vetores.
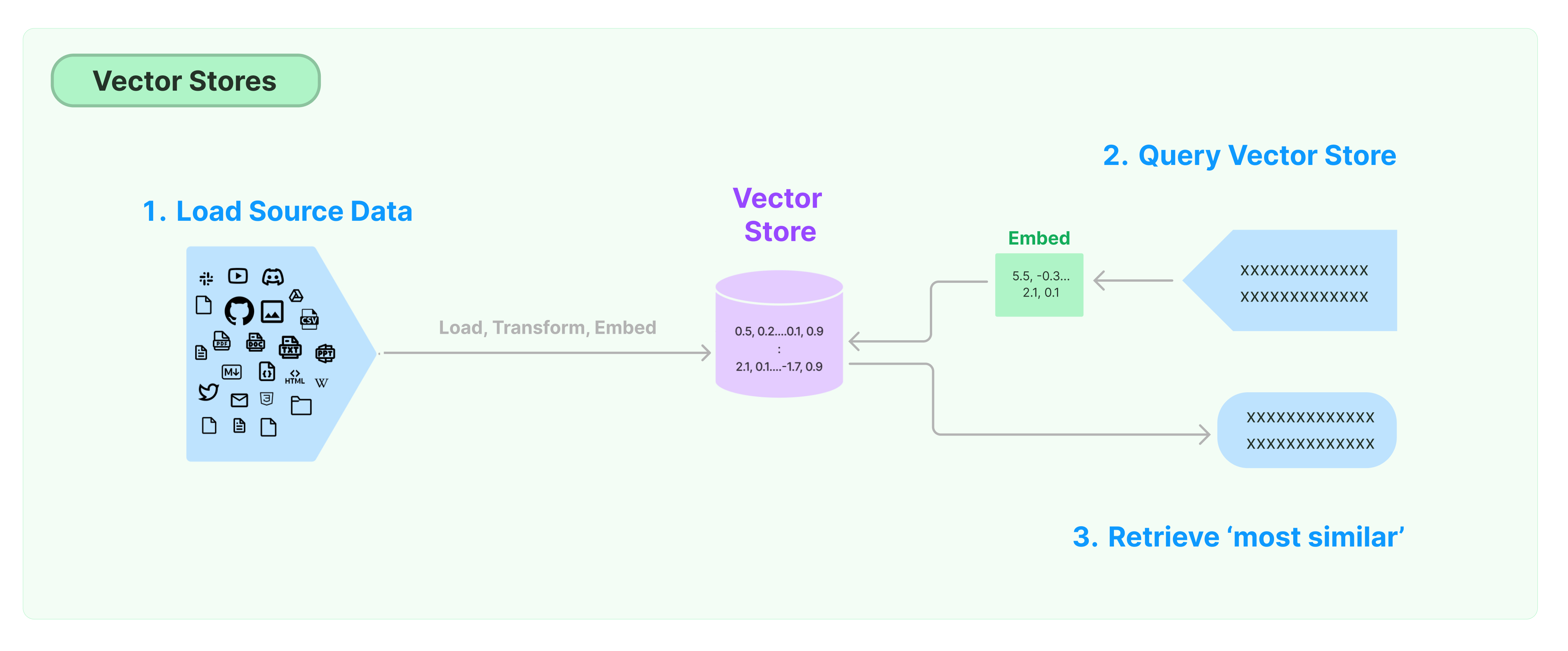
Começando com o Armazenamento de Vetor LangChain
Este guia apresenta as funcionalidades básicas relacionadas aos Armazenamentos de Vetor. O componente-chave que trabalha com o armazenamento de vetor é o modelo de incorporação (responsável por calcular vetores de características). Portanto, é recomendável aprender como calcular vetores de texto com o modelo de incorporação de texto antes de estudar este capítulo.
Existem muitos mecanismos excelentes de armazenamento de vetores. Abaixo, apresentamos o uso de 3 mecanismos de armazenamento de vetor gratuitos e de código aberto no framework LangChain.
Chroma
Este capítulo utiliza o banco de dados de vetor chroma, que roda localmente como uma biblioteca Python.
pip install chromadb
Aqui, utilizamos o modelo de incorporação da OpenAI para calcular os vetores, portanto, precisamos obter a chave da API da OpenAI.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('Chave da API da OpenAI:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
documentos_brutos = TextLoader('../../../state_of_the_union.txt').load()
divisor_texto = CharacterTextSplitter(tamanho_segmento=1000, sobreposicao_segmento=0)
documentos = divisor_texto.dividir_documentos(documentos_brutos)
db = Chroma.from_documents(documentos, OpenAIEmbeddings())
FAISS
Este capítulo utiliza o banco de dados de vetor FAISS, que utiliza a biblioteca Facebook AI Similarity Search (FAISS).
pip install faiss-cpu
Aqui, utilizamos o modelo de incorporação da OpenAI para calcular os vetores, portanto, precisamos obter a chave da API da OpenAI.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('Chave da API da OpenAI:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
documentos_brutos = TextLoader('../../../state_of_the_union.txt').load()
divisor_texto = CharacterTextSplitter(tamanho_segmento=1000, sobreposicao_segmento=0)
documentos = divisor_texto.dividir_documentos(documentos_brutos)
db = FAISS.from_documents(documentos, OpenAIEmbeddings())
Lance
Neste capítulo, vamos introduzir como o framework LangChain utiliza o banco de dados de vetor LanceDB.
pip install lancedb
Aqui, utilizamos o modelo de incorporação da OpenAI para calcular vetores, portanto, precisamos obter a chave da API da OpenAI.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('Chave da API da OpenAI:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import LanceDB
import lancedb
db = lancedb.connect("/tmp/lancedb")
tabela = db.create_table(
"minha_tabela",
dados=[
{
"vetor": embeddings.embed_query("Olá Mundo"),
"texto": "Olá Mundo",
"id": "1",
}
],
modo="sobrescrever",
)
documentos_brutos = TextLoader('../../../state_of_the_union.txt').load()
divisor_texto = CharacterTextSplitter(tamanho_segmento=1000, sobreposicao_segmento=0)
documentos = divisor_texto.dividir_documentos(documentos_brutos)
db = LanceDB.from_documents(documentos, OpenAIEmbeddings(), conexão=tabela)
Busca de Semelhança
consulta = "O que o Presidente disse para Ketanji Brown Jackson?"
docs = db.similarity_search(consulta)
print(docs[0].conteúdo_da_página)
Pesquisa de Similaridade de Vetores
Utilize similarity_search_by_vector para realizar uma busca de similaridade com base no vetor fornecido. Essa função recebe um vetor de incorporação como parâmetro, em vez de uma string.
vetor_de_incorporação = OpenAIEmbeddings().embed_query(query)
docs = db.similarity_search_by_vector(vetor_de_incorporação)
print(docs[0].page_content)
Operações Assíncronas
O armazenamento de vetores frequentemente funciona como um serviço independente e requer algumas operações de E/S. Portanto, utilize chamadas assíncronas para a interface do banco de dados de vetores. Isso pode melhorar o desempenho, pois você não precisa esperar pelas respostas de serviços externos.
O Langchain suporta operações assíncronas para o armazenamento de vetores. Todos os métodos podem ser chamados usando suas funções assíncronas com o prefixo a, indicando async.
Qdrant é um armazenamento de vetores que suporta todas as operações assíncronas. Abaixo está um exemplo usando o Qdrant.
pip install qdrant-client
from langchain_community.vectorstores import Qdrant
Criação Assíncrona de Armazenamento de Vetores
db = await Qdrant.afrom_documents(documentos, incorporações, "http://localhost:6333")
Busca de Similaridade
query = "O que o Presidente disse para Ketanji Brown Jackson?"
docs = await db.asimilarity_search(query)
print(docs[0].page_content)
Busca Baseada em Vetores
vetor_de_incorporação = incorporações.embed_query(query)
docs = await db.asimilarity_search_by_vector(vetor_de_incorporação)
Busca de Relevância Marginal Máxima (MMR)
A Relevância Marginal Máxima otimiza a similaridade com a consulta e a diversidade entre os documentos selecionados. Também oferece suporte a uma API assíncrona.
query = "O que o Presidente disse para Ketanji Brown Jackson?"
docs_encontrados = await qdrant.amax_marginal_relevance_search(query, k=2, fetch_k=10)
for i, doc in enumerate(docs_encontrados):
print(f"{i + 1}.", doc.page_content, "\n")