Magasin de vecteurs
- Allez sur Intégrations pour découvrir tous les moteurs de stockage de vecteurs tiers officiellement pris en charge par LangChain.
La solution la plus courante pour stocker et rechercher des données non structurées consiste à calculer des vecteurs de caractéristiques des données, puis à rechercher des vecteurs similaires en fonction de la similarité des vecteurs lors de la requête. Une base de données vectorielle est responsable de fournir des moteurs de stockage de données pour stocker et interroger des vecteurs.
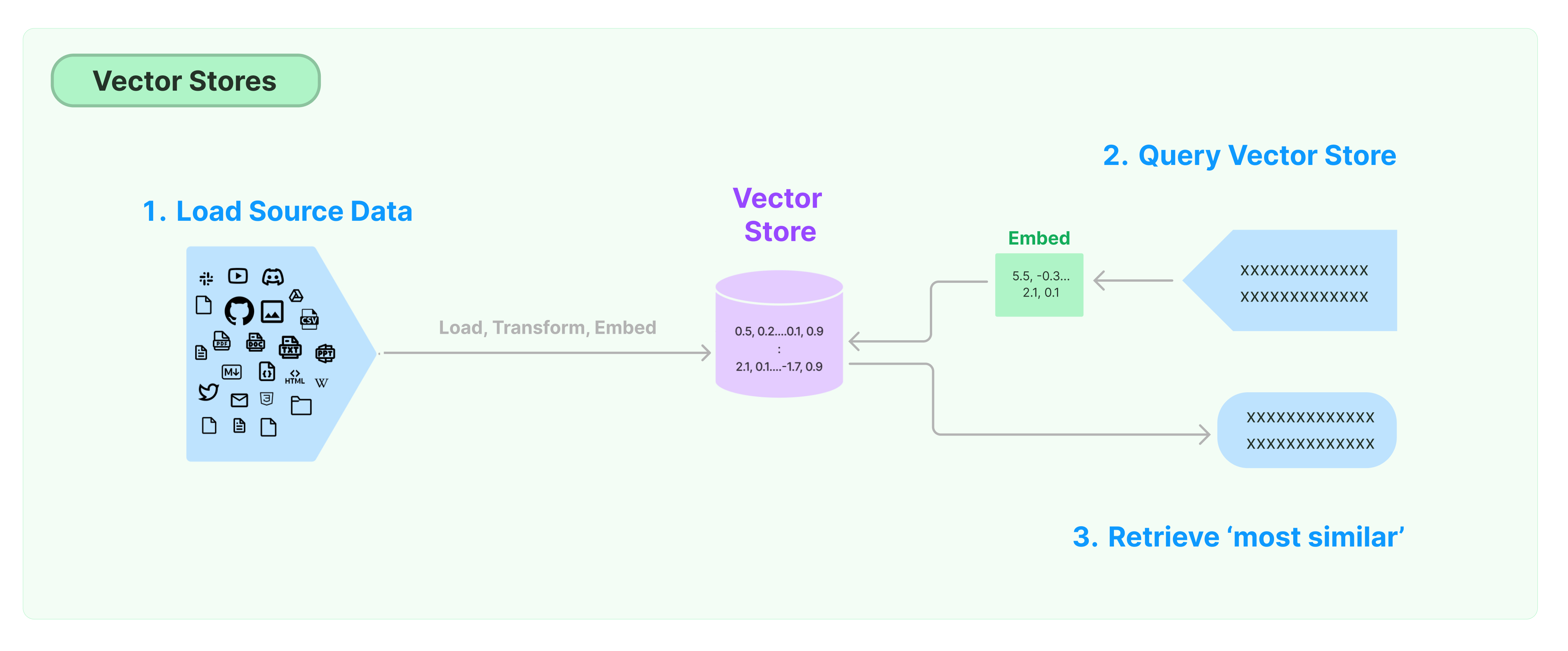
Premiers pas avec LangChain Vector Store
Ce guide présente les fonctionnalités de base relatives aux magasins de vecteurs. Le composant clé pour travailler avec le stockage de vecteurs est le modèle d'encastrement (responsable du calcul des vecteurs de caractéristiques). Il est donc recommandé d'apprendre à calculer des vecteurs de texte avec le modèle d'encastrement de texte avant d'étudier ce chapitre.
Il existe de nombreux excellents moteurs de stockage de vecteurs. Ci-dessous, nous présentons l'utilisation de 3 moteurs de stockage de vecteurs gratuits et open-source dans le cadre de LangChain.
Chroma
Ce chapitre utilise la base de données de vecteurs chroma, qui s'exécute localement en tant que bibliothèque Python.
pip install chromadb
Ici, nous utilisons le modèle d'encastrement OpenAI pour calculer les vecteurs, donc nous avons besoin d'obtenir la clé API OpenAI.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('Clé API OpenAI :')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
documents_bruts = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(taille_bloc=1000, chevauchement_bloc=0)
documents = text_splitter.split_documents(documents_bruts)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
FAISS
Ce chapitre utilise la base de données de vecteurs FAISS, qui utilise la bibliothèque Facebook AI Similarity Search (FAISS).
pip install faiss-cpu
Ici, nous utilisons le modèle d'encastrement OpenAI pour calculer les vecteurs, donc nous avons besoin d'obtenir la clé API OpenAI.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('Clé API OpenAI :')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
documents_bruts = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(taille_bloc=1000, chevauchement_bloc=0)
documents = text_splitter.split_documents(documents_bruts)
db = FAISS.from_documents(documents, OpenAIEmbeddings())
Lance
Dans ce chapitre, nous introduirons comment le framework LangChain utilise la base de données de vecteurs LanceDB.
pip install lancedb
Ici, nous utilisons le modèle d'encastrement d'OpenAI pour calculer les vecteurs, donc nous avons besoin d'obtenir la clé API OpenAI.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('Clé API OpenAI :')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import LanceDB
import lancedb
db = lancedb.connect("/tmp/lancedb")
table = db.create_table(
"ma_table",
data=[
{
"vecteur": embeddings.embed_query("Bonjour le monde"),
"texte": "Bonjour le monde",
"id": "1",
}
],
mode="overwrite",
)
documents_bruts = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(taille_bloc=1000, chevauchement_bloc=0)
documents = text_splitter.split_documents(documents_bruts)
db = LanceDB.from_documents(documents, OpenAIEmbeddings(), connection=table)
Recherche de similarité
requête = "Qu'a dit le Président à Ketanji Brown Jackson ?"
docs = db.similarity_search(requête)
print(docs[0].contenu_page)
Recherche de similarité vectorielle
Utilisez similarity_search_by_vector pour effectuer une recherche de similarité basée sur le vecteur donné. Cette fonction prend un vecteur d'incorporation en paramètre au lieu d'une chaîne de caractères.
embedding_vector = OpenAIEmbeddings().embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
print(docs[0].page_content)
Opérations asynchrones
Le stockage vectoriel fonctionne souvent comme un service indépendant et nécessite des opérations d'entrée/sortie. Par conséquent, utilisez des appels asynchrones à l'interface de la base de données vectorielle. Cela peut améliorer les performances car vous n'avez pas à attendre inutilement les réponses des services externes.
Langchain prend en charge les opérations asynchrones pour le stockage vectoriel. Toutes les méthodes peuvent être appelées à l'aide de leurs fonctions asynchrones avec le préfixe a, indiquant async.
Qdrant est un stockage vectoriel qui prend en charge toutes les opérations asynchrones. Voici un exemple d'utilisation de Qdrant.
pip install qdrant-client
from langchain_community.vectorstores import Qdrant
Création asynchrone de stockage vectoriel
db = await Qdrant.afrom_documents(documents, embeddings, "http://localhost:6333")
Recherche de similarité
query = "Que a dit le président à Ketanji Brown Jackson ?"
docs = await db.asimilarity_search(query)
print(docs[0].page_content)
Recherche basée sur un vecteur
embedding_vector = embeddings.embed_query(query)
docs = await db.asimilarity_search_by_vector(embedding_vector)
Recherche de pertinence maximale marginale (MMR)
La pertinence maximale marginale optimise la similarité avec la requête et la diversité entre les documents sélectionnés. Elle prend également en charge une API asynchrone.
query = "Que a dit le président à Ketanji Brown Jackson ?"
found_docs = await qdrant.amax_marginal_relevance_search(query, k=2, fetch_k=10)
for i, doc in enumerate(found_docs):
print(f"{i + 1}.", doc.page_content, "\n")