ভেক্টর স্টোর
- ইন্টিগ্রেশন এ যান ল্যাংচেইন দ্বারা সরদিদ সমর্থিত তৃতীয় পক্ষ ভেক্টর স্টোরেজ ইঞ্জিনগুলি সম্পর্কে জানতে।
অ্যানস্ট্রাকচার্ড ডেটার সংরক্ষণ এবং অনুসন্ধানের জন্য সবচেয়ে সাধারণ সমাধান হলো ডেটার ফিচার ভেক্টর গণনা করা এবং প্রশ্ন করার সময় ভেক্টর সাদৃশ্যের ভিত্তিতে অনুরূপ ভেক্টর অনুসন্ধান করা। একটি ভেক্টর ডেটাবেস ভেক্টর সংরক্ষণ ইঞ্জিন প্রদান করার জন্য দায়িত্বপ্রাপ্ত।
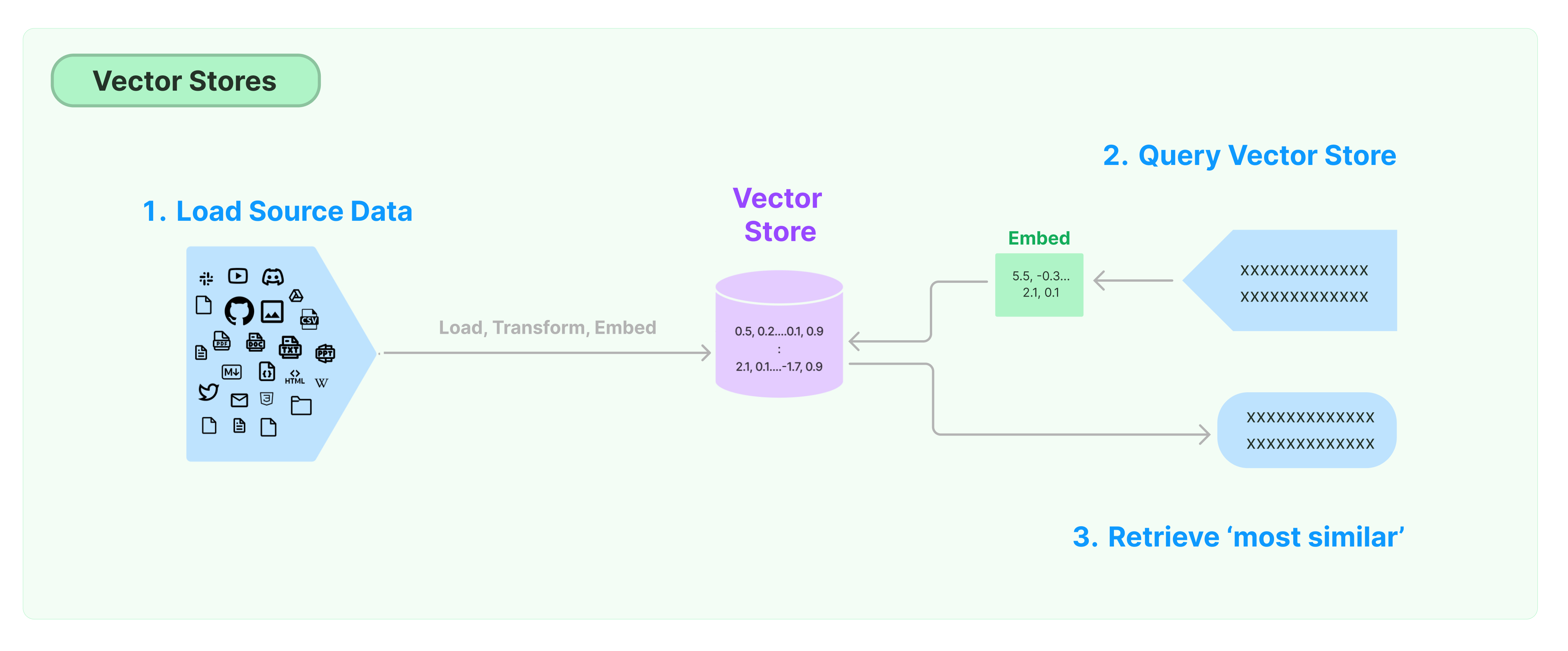
ল্যাংচেইন ভেক্টর স্টোর দিয়ে শুরু হওয়া
এই গাইডটি ভেক্টর স্টোর সম্পর্কিত মৌলিক কার্যক্ষমতাগুলির মধ্যে পরিচিত করা যায়। টেক্সট ভেক্টর গণনা করার জন্য টেক্সট এম্বেডিং মডেল নির্ধারণ করার আগে এই অধ্যায়টি অধ্যয়ন করার আগে প্রস্তাবিত হয়।
একাধিক সুস্বাদু ভেক্টর স্টোর ইঞ্জিন আছে। নীচে, ল্যাংচেইন ফ্রেমওয়ার্কে 3 টি বিনামূল্যে এবং ওপেন-সোর্স ভেক্টর স্টোর ইঞ্জিনের ব্যবহার প্রস্তাবিত হয়।
ক্রোমা
এই অধ্যায়টি chroma ভেক্টর ডাটাবেস ব্যবহার করে, যা পাইথন লাইব্রেরিহীন একটি স্থানীয় স্থানকরণ হয়।
pip install chromadb
এখানে, আমরা ওপেনএআই এম্বেডিং মডেল ব্যবহার করে ভেক্টর গণনা করার জন্য, তাই আমাদের ওপেনএআই API কী অর্জন করতে হয়।
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
ফাইস
এই অধ্যায়টি FAISS ভেক্টর ডাটাবেস ব্যবহার করে, যা ফেসবুক এআই সিমিল্যারিটি সার্চ (FAISS) লাইব্রেরি ব্যবহার করে।
pip install faiss-cpu
এখানে, আমরা ওপেনএআই এম্বেডিং মডেল ব্যবহার করে ভেক্টর গণনা করার জন্য, তাই আমাদের ওপেনএআই API কী অর্জন করতে হয়।
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = FAISS.from_documents(documents, OpenAIEmbeddings())
ল্যান্স
এই অধ্যায়টিতে আমরা দেখাব কীভাবে ল্যাংচেইন ফ্রেমওয়ার্ক ল্যান্সডি বি ভেক্টর ডাটাবেস ব্যবহার করে।
pip install lancedb
এখানে, আমরা চেষ্টা করি OpenAI-এর এম্বেডিং মডেল ব্যবহার করে ভেক্টর গণনা করার জন্য, তাই আমাদের ওপেনএআই API কী অর্জন করতে হয়।
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import LanceDB
import lancedb
db = lancedb.connect("/tmp/lancedb")
table = db.create_table(
"my_table",
data=[
{
"vector": embeddings.embed_query("Hello World"),
"text": "Hello World",
"id": "1",
}
],
mode="overwrite",
)
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = LanceDB.from_documents(documents, OpenAIEmbeddings(), connection=table)
সাদৃশ্য সার্চ
query = "প্রেসিডেন্ট কেতনজি ব্রাউন জ্যাকসনকে কি বলেছিলেন?"
docs = db.similarity_search(query)
print(docs[0].page_content)
ভেক্টর সাদৃশ্য অনুসন্ধান
similarity_search_by_vector ব্যবহার করে দেওয়া ভেক্টরের উপর ভিত্তি করে সাদৃশ্য অনুসন্ধান করুন। এই ফাংশনটি একটি স্ট্রিং প্যারামিটারের পরিবর্তে এমবেডিং ভেক্টর নেয়।
embedding_vector = OpenAIEmbeddings().embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
print(docs[0].page_content)
অসিঞ্চিত অপারেশন
ভেক্টর স্টোরেজ সাধারণভাবে একটি স্বাধীন সেবা হিসেবে চালিত হয় এবং কিছু আইও অপারেশনের প্রয়োজন হয়। তথ্যের বাইরেও থেকে প্রতিক্রিয়া অপেক্ষা করার জন্য সময় অপচয় না করতে, ভেক্টর ডাটাবেস ইন্টারফেসের জন্য অসিঞ্চিত কল ব্যবহার করুন।
ল্যাংচেন ভেক্টর স্টোরেজের জন্য অনিবার্য অসিঞ্চিত অপারেশন সমর্থন করে। সব পদ্ধতিগুলির জন্য অসিঞ্চিত ফাংশন ব্যবহার করতে হয়, যা a উপসর্গ সহ অধিকাংশ পদ্ধতিকে নির্দেশ করে।
Qdrant একটি ভেক্টর স্টোরেজ যা সমস্ত অসিঞ্চিত অপারেশন সমর্থন করে। নিচে একটি Qdrant ব্যবহারের উদাহরণ দেওয়া হয়।
pip install qdrant-client
from langchain_community.vectorstores import Qdrant
অসিঞ্চিত ভেক্টর স্টোরেজ তৈরি
db = await Qdrant.afrom_documents(documents, embeddings, "http://localhost:6333")
সাদৃশ্য অনুসন্ধান
query = "দুনিয়ার প্রেসিডেন্ট কেতনজি ব্রাউন জ্যাকসন-কে কী বললেন?"
docs = await db.asimilarity_search(query)
print(docs[0].page_content)
ভেক্টর ভিত্তিক অনুসন্ধান
embedding_vector = embeddings.embed_query(query)
docs = await db.asimilarity_search_by_vector(embedding_vector)
সর্বাধিক সীমানা উপরের মৌলিকতা (MMR) অনুসন্ধান
সর্বাধিক সীমানা উপরের মৌলিকতা অনুসন্ধান করলে আপনি সামগ্রিক ডকুমেন্টগুলির মধ্যে যোগদানের প্রাধান্যতা অনুভূত করবেন। এটি অসিঞ্চিত API সমর্থন করে।
query = "দুনিয়ার প্রেসিডেন্ট কেতনজি ব্রাউন জ্যাকসন-কে কী বললেন?"
found_docs = await qdrant.amax_marginal_relevance_search(query, k=2, fetch_k=10)
for i, doc in enumerate(found_docs):
print(f"{i + 1}.", doc.page_content, "\n")