ร้านขายเวกเตอร์
- ไปที่ การทำงานร่วมกัน เพื่อเรียนรู้เกี่ยวกับเครื่องมือเก็บเวกเตอร์บุคคลภาพของการสนับสนุนโดยอย่างเป็นทางการของ LangChain
สิ่งที่ทั่วไปที่สุดสำหรับการเก็บรักษาและค้นหาข้อมูลที่ไม่มีโครงสร้างคือการคำนวณเวกเตอร์ลักษณะของข้อมูล และจากนั้นค้นหาเวกเตอร์ที่คล้ายคลึงขึ้นมาบนการค้นหา เมื่อค้นหา ฐานข้อมูลเวกเตอร์รับผิดชอบในการให้เครื่องมือเก็บข้อมูลสำหรับการค้นหาเวกเตอร์
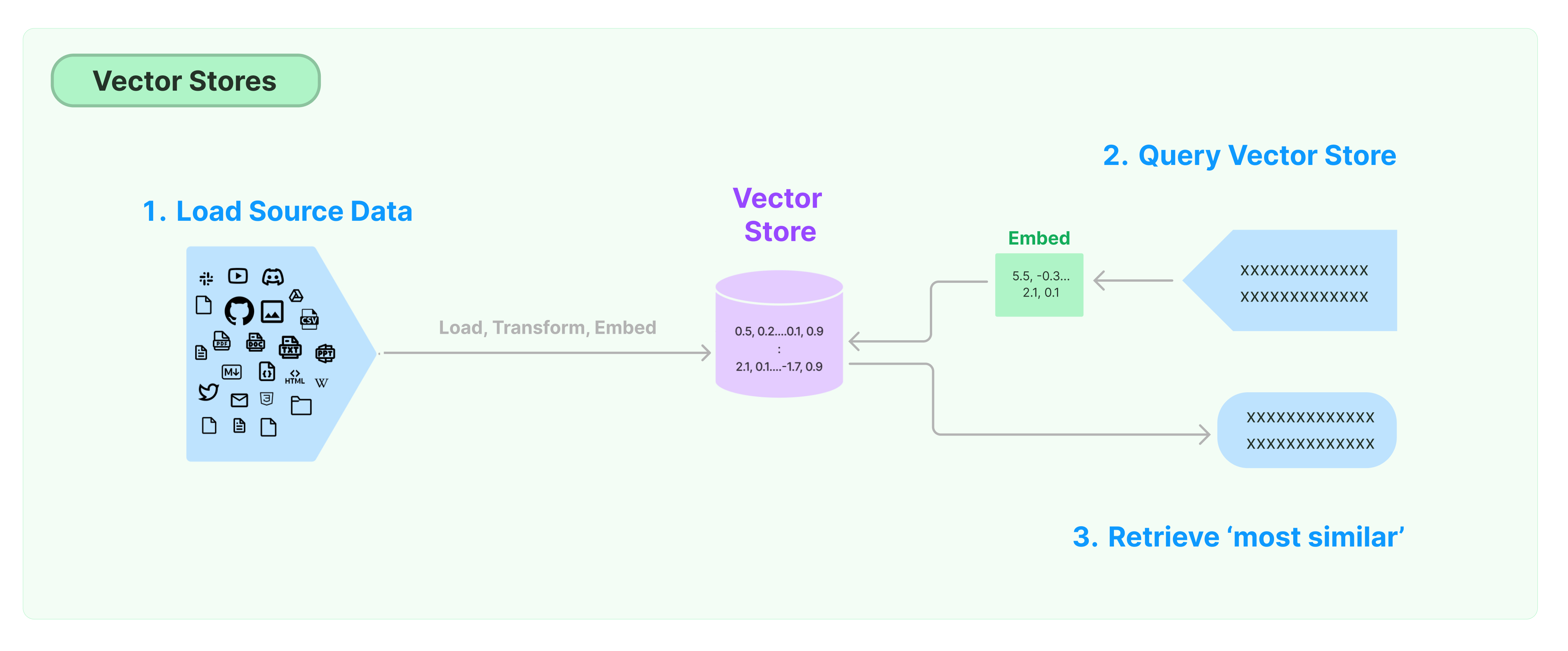
การเริ่มต้นกับ LangChain Vector Store
คู่มือนี้นำเสนอความสามารถพื้นฐานที่เกี่ยวข้องกับ Vector Stores ส่วนประกอบสำคัญในการทำงานกับการจัดเก็บเวกเตอร์คือ embedding model (ที่รับผิดชอบในการคำนวณเวกเตอร์ลักษณะ) ดังนั้น เราขอแนะนำให้เรียนรู้วิธีการคำนวณเวกเตอร์ของข้อความกับ text embedding model ก่อนการศึกษาบทนี้
มีหลาย Engine เก็บเวกเตอร์ที่ยอดเยี่ยม ด้านล่างนี้เราจะแนะนำการใช้งานของ 3 Engine ที่เป็นเวอร์ชันฟรีและโอเพ่นซอร์สในกรอบงาน LangChain
Chroma
บทนี้ใช้ฐานข้อมูลเวกเตอร์ชื่อ chroma ซึ่งทำงานแบบท้องถิ่นเป็น Python library
pip install chromadb
ที่นี่เราใช้ OpenAI embedding model เพื่อคำนวณเวกเตอร์ ดังนั้น เราต้องได้รับ OpenAI API key
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
FAISS
บทนี้ใช้ฐานข้อมูลเวกเตอร์ชื่อ FAISS ซึ่งใช้ไลบรารี Facebook AI Similarity Search (FAISS)
pip install faiss-cpu
ที่นี่เราใช้ OpenAI embedding model เพื่อคำนวณเวกเตอร์ ดังนั้น เราต้องได้รับ OpenAI API key
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = FAISS.from_documents(documents, OpenAIEmbeddings())
Lance
ในบทนี้ เราจะแนะนำว่ากรอบงาน LangChain ใช้องค์การเวกเตอร์ชื่อ LanceDB
pip install lancedb
ที่นี่เราใช้ OpenAI embedding model เพื่อคำนวณเวกเตอร์ ดังนั้น เราต้องได้รับ OpenAI API key
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import LanceDB
import lancedb
db = lancedb.connect("/tmp/lancedb")
table = db.create_table(
"my_table",
data=[
{
"vector": embeddings.embed_query("Hello World"),
"text": "Hello World",
"id": "1",
}
],
mode="overwrite",
)
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = LanceDB.from_documents(documents, OpenAIEmbeddings(), connection=table)
การค้นหาความคล้ายคลึง
query = "What did the President say to Ketanji Brown Jackson?"
docs = db.similarity_search(query)
print(docs[0].page_content)
ค้นหาความคล้ายคลึงแบบเวกเตอร์
ใช้ similarity_search_by_vector เพื่อทำการค้นหาความคล้ายคลึงโดยใช้เวกเตอร์ที่กำหนดไว้ ฟังก์ชันนี้รับเวกเตอร์ซึ่งเป็นการฝังเอาท์เป็นพารามิเตอร์แทนที่จะใช้สตริง
embedding_vector = OpenAIEmbeddings().embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
print(docs[0].page_content)
การดำเนินงานแบบไม่สัมพันธ์
การเก็บรักษาเวกเตอร์มักทำงานเป็นบริการอิสระและต้องการการดำเนินงานของไอโอ ดังนั้น ให้ใช้การเรียกใช้แบบไม่สัมพันธ์เมื่อเชื่อมต่อกับอินเตอร์เฟซเก็บเวกเตอร์ สิ่งนี้สามารถเพิ่มประสิทธิภาพได้เนื่องจากไม่ต้องเสียเวลารอคำตอบจากบริการภายนอก
Langchain รองรับการดำเนินงานแบบไม่สัมพันธ์สำหรับการเก็บเวกเตอร์ ทุกระบบสามารถเรียกใช้เมทอดแบบไม่สัมพันธ์ของตนเองด้วยคำนำหน้า a ที่หมายถึง async
Qdrant คือระบบเก็บเวกเตอร์ที่รองรับการดำเนินงานแบบไม่สัมพันธ์ทุกอย่าง ต่อไปคือตัวอย่างการใช้ Qdrant
pip install qdrant-client
from langchain_community.vectorstores import Qdrant
การสร้างการจัดเก็บเวกเตอร์แบบไม่สัมพันธ์
db = await Qdrant.afrom_documents(documents, embeddings, "http://localhost:6333")
ค้นหาความคล้ายคลึง
query = "What did the President say to Ketanji Brown Jackson?"
docs = await db.asimilarity_search(query)
print(docs[0].page_content)
การค้นหาโดยใช้เวกเตอร์
embedding_vector = embeddings.embed_query(query)
docs = await db.asimilarity_search_by_vector(embedding_vector)
การค้นหาด้วย Maximal Marginal Relevance (MMR)
Maximal Marginal Relevance ปรับปรุงความคล้ายคลึงกับคิดสำคัญที่สุดและความหลากหลายระหว่างเอกสารที่เลือกไว้ ระบบนี้ยังรองรับ API แบบไม่สัมพันธ์
query = "What did the President say to Ketanji Brown Jackson?"
found_docs = await qdrant.amax_marginal_relevance_search(query, k=2, fetch_k=10)
for i, doc in enumerate(found_docs):
print(f"{i + 1}.", doc.page_content, "\n")