벡터 저장소
- 통합으로 이동하여 LangChain에서 공식적으로 지원하는 모든 서드 파티 벡터 저장 엔진에 대해 알아보세요.
비구조화된 데이터를 저장하고 검색하는 가장 일반적인 방법은 데이터의 특징 벡터를 계산하고, 쿼리할 때 벡터 유사성에 기반하여 유사한 벡터를 검색하는 것입니다. 벡터 데이터베이스는 벡터를 저장하고 쿼리하는 데이터 저장 엔진을 제공하는 것을 책임집니다.
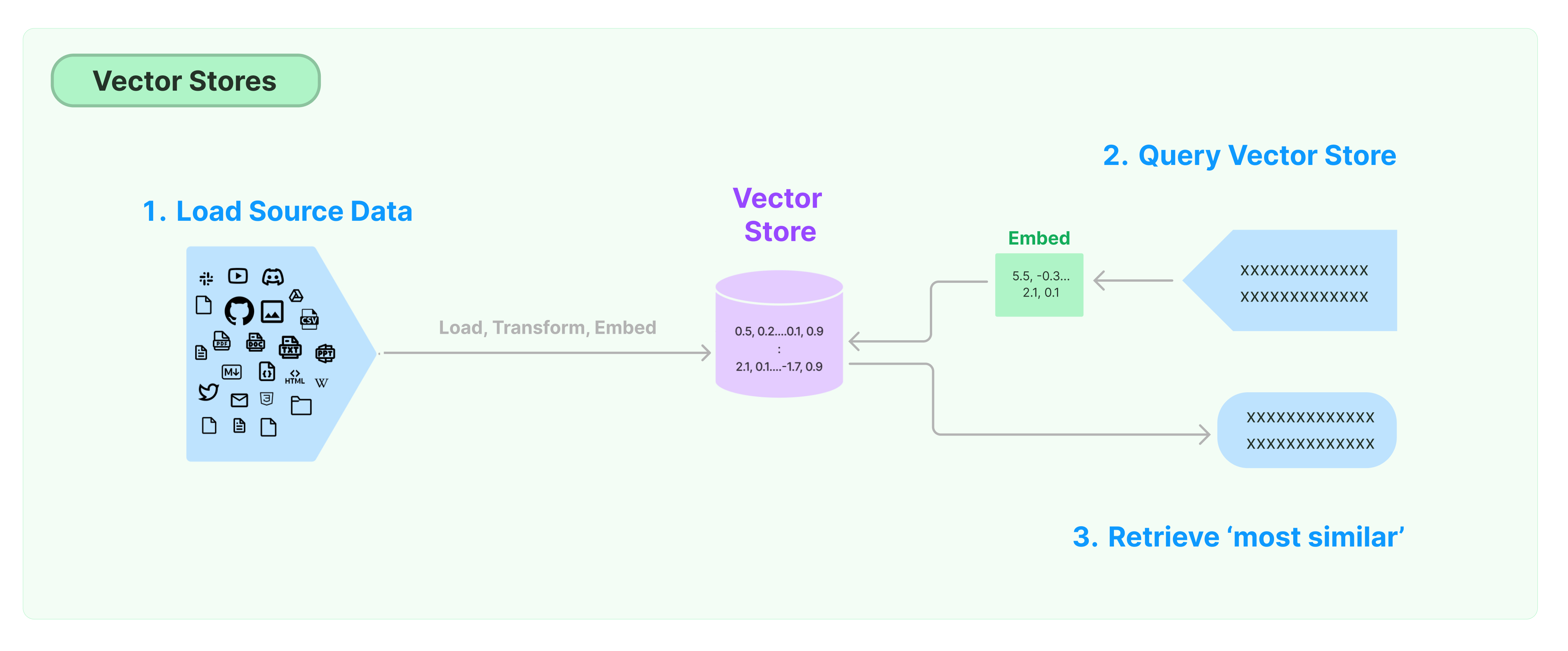
LangChain 벡터 저장소 시작하기
본 안내서는 벡터 저장소와 관련된 기본 기능을 소개합니다. 벡터 저장소와 함께 작동하는 주요 구성 요소는 임베딩 모델(특징 벡터를 계산하는 데 책임을 짐)입니다. 따라서 본 장을 공부하기 전에 텍스트 임베딩 모델로 텍스트 벡터를 어떻게 계산하는지 먼저 배우는 것이 좋습니다.
많은 훌륭한 벡터 저장 엔진이 있습니다. 아래에서는 LangChain 프레임워크에서 3가지 무료 오픈 소스 벡터 저장 엔진의 사용법을 소개합니다.
Chroma
본 장에서는 chroma 벡터 데이터베이스를 사용하며, 이는 Python 라이브러리로 로컬에서 실행됩니다.
pip install chromadb
여기서 우리는 OpenAI 임베딩 모델을 사용하여 벡터를 계산하므로, OpenAI API 키를 획득해야 합니다.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
FAISS
본 장에서는 Facebook AI 유사도 검색(FAISS) 라이브러리를 활용하는 FAISS 벡터 데이터베이스를 사용합니다.
pip install faiss-cpu
여기서 우리는 OpenAI 임베딩 모델을 사용하여 벡터를 계산하므로, OpenAI API 키를 획득해야 합니다.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = FAISS.from_documents(documents, OpenAIEmbeddings())
Lance
본 장에서는 LangChain 프레임워크가 LanceDB 벡터 데이터베이스를 사용하는 방법을 소개합니다.
pip install lancedb
여기서 우리는 OpenAI의 임베딩 모델을 사용하여 벡터를 계산하므로, OpenAI API 키를 획득해야 합니다.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import LanceDB
import lancedb
db = lancedb.connect("/tmp/lancedb")
table = db.create_table(
"my_table",
data=[
{
"vector": embeddings.embed_query("Hello World"),
"text": "Hello World",
"id": "1",
}
],
mode="overwrite",
)
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = LanceDB.from_documents(documents, OpenAIEmbeddings(), connection=table)
유사성 검색
query = "대통령이 Ketanji Brown Jackson에게 무엇이라고 말했나요?"
docs = db.similarity_search(query)
print(docs[0].page_content)
벡터 유사도 검색
similarity_search_by_vector를 사용하여 주어진 벡터를 기반으로 유사도 검색을 수행합니다. 이 함수는 문자열 대신 임베딩 벡터를 매개변수로 사용합니다.
embedding_vector = OpenAIEmbeddings().embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
print(docs[0].page_content)
비동기 작업
벡터 저장소는 종종 독립적인 서비스로 실행되며 일부 IO 작업이 필요합니다. 따라서 벡터 데이터베이스 인터페이스에 대해 비동기 호출을 사용하세요. 외부 서비스로부터의 응답을 기다리는 시간을 낭비하지 않아 성능을 향상시킬 수 있습니다.
Langchain은 벡터 저장소를 위한 비동기 작업을 지원합니다. 모든 메서드는 async 접두사를 사용하여 비동기 함수를 통해 호출할 수 있습니다.
Qdrant는 모든 비동기 작업을 지원하는 벡터 저장소입니다. 아래는 Qdrant를 사용하는 예시입니다.
pip install qdrant-client
from langchain_community.vectorstores import Qdrant
비동기 벡터 저장소 생성
db = await Qdrant.afrom_documents(documents, embeddings, "http://localhost:6333")
유사도 검색
query = "대통령이 Ketanji Brown Jackson에게 무엇을 말했나요?"
docs = await db.asimilarity_search(query)
print(docs[0].page_content)
벡터 기반 검색
embedding_vector = embeddings.embed_query(query)
docs = await db.asimilarity_search_by_vector(embedding_vector)
최대 주변 관계 (MMR) 검색
최대 주변 관계는 쿼리와 선택된 문서 간의 유사도 및 다양성을 최적화합니다. 또한 비동기 API를 지원합니다.
query = "대통령이 Ketanji Brown Jackson에게 무엇을 말했나요?"
found_docs = await qdrant.amax_marginal_relevance_search(query, k=2, fetch_k=10)
for i, doc in enumerate(found_docs):
print(f"{i + 1}.", doc.page_content, "\n")