Vektör Mağazası
- Tüm resmi olarak desteklenen LangChain tarafından üçüncü taraf vektör depolama motorları hakkında bilgi edinmek için Entegrasyonlar sayfasına gidin.
Yapılandırılmamış verilerin depolanması ve aranması için en yaygın çözüm, verilerin özellik vektörlerini hesaplamak ve sorgulama yaparken benzer vektörlere dayalı olarak vektör benzerliğini aramaktır. Bir vektör veritabanı, vektörlerin depolanması ve sorgulanması için veri depolama motorlarını sağlamaktan sorumludur.
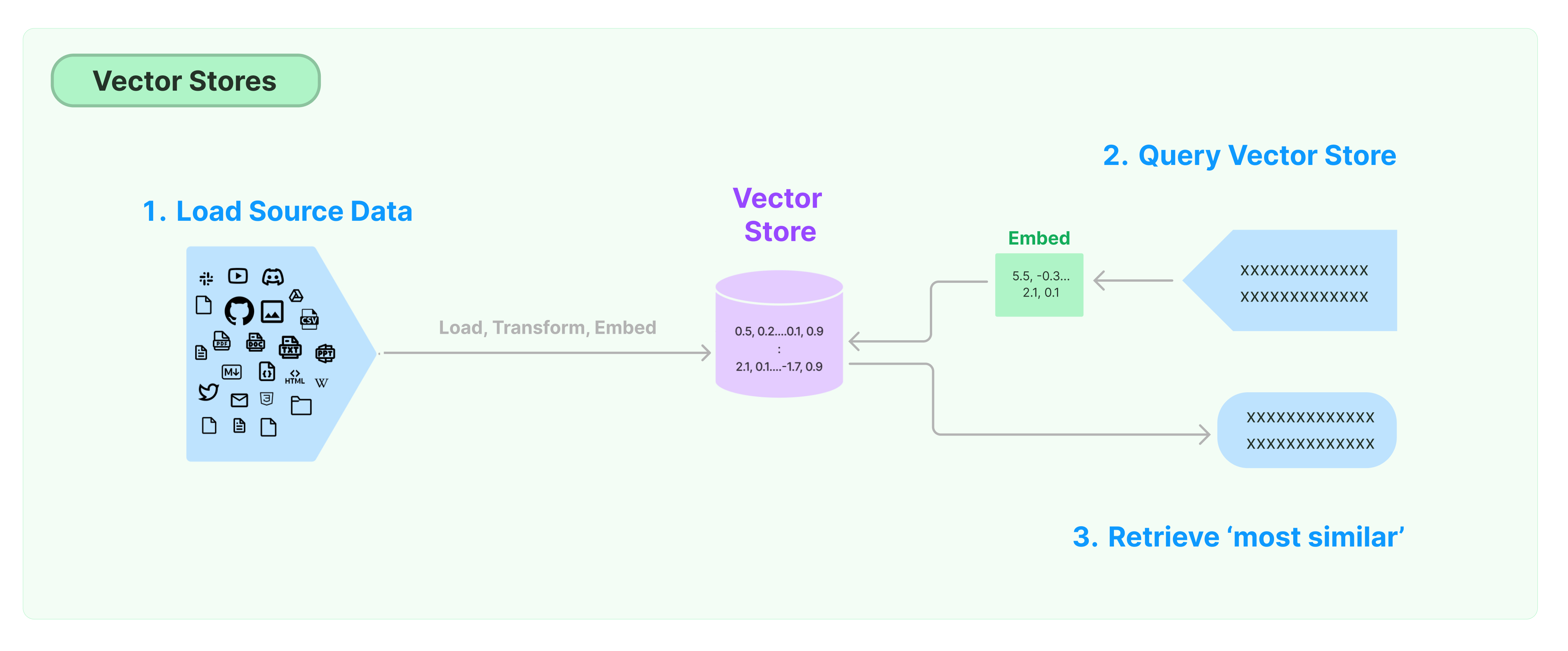
LangChain Vektör Mağazası'na Başlarken
Bu rehber, Vektör Mağazaları ile ilgili temel işlevsellikleri tanıtır. Vektör depolama ile çalışan temel bileşen, özellik vektörlerini hesaplamaktan sorumlu gömmeli modeldir. Bu nedenle, bu bölümü incelemenizden önce metin gömme modeli ile metin vektörlerini nasıl hesaplayacağınızı öğrenmenizi öneririz.
Birçok mükemmel vektör depolama motoru bulunmaktadır. Aşağıda, LangChain çerçevesindeki 3 ücretsiz ve açık kaynaklı vektör depolama motorunun kullanımını tanıtıyoruz.
Chroma
Bu bölüm, yerel olarak Python kütüphanesi olarak çalışan chroma vektör veritabanını kullanır.
pip install chromadb
Burada, vektörleri hesaplamak için OpenAI gömmeli modelini kullanıyoruz, bu nedenle OpenAI API anahtarını almalıyız.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Anahtarı:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
FAISS
Bu bölüm, Facebook AI Benzerlik Arama (FAISS) kütüphanesini kullanan FAISS vektör veritabanını kullanır.
pip install faiss-cpu
Burada, vektörleri hesaplamak için OpenAI gömmeli modelini kullanıyoruz, bu nedenle OpenAI API anahtarını almalıyız.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Anahtarı:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = FAISS.from_documents(documents, OpenAIEmbeddings())
Lance
Bu bölümde, LangChain çerçevesinin LanceDB vektör veritabanını nasıl kullandığını tanıtacağız.
pip install lancedb
Burada, vektörleri hesaplamak için OpenAI'nın gömmeli modelini kullanıyoruz, bu nedenle OpenAI API anahtarını almalıyız.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Anahtarı:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import LanceDB
import lancedb
db = lancedb.connect("/tmp/lancedb")
table = db.create_table(
"my_table",
data=[
{
"vector": embeddings.embed_query("Merhaba Dünya"),
"metin": "Merhaba Dünya",
"id": "1",
}
],
mode="üzerine yaz",
)
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = LanceDB.from_documents(documents, OpenAIEmbeddings(), connection=table)
Benzerlik Arama
sorgu = "Başkan Ketanji Brown Jackson'a ne dedi?"
dokumanlar = db.benzerlik_arama(sorgu)
print(dokumanlar[0].sayfa_içeriği)
Vektör Benzerlik Araması
Verilen vektöre dayalı benzerlik aramasını yapmak için similarity_search_by_vector kullanın. Bu işlev, bir dize yerine gömme vektörünü parametre olarak alır.
embedding_vector = OpenAIEmbeddings().embed_query(sorgu)
belgeler = db.similarity_search_by_vector(embedding_vector)
print(belgeler[0].page_content)
Asenkron İşlemler
Vektör depolama genellikle bağımsız bir hizmet olarak çalışır ve bazı G/Ç işlemlerine ihtiyaç duyar. Bu nedenle, dış hizmetlerden gelen yanıtları beklemek için zaman harcamamak için vektör veritabanı arayüzüne asenkron çağrılar yapın.
Langchain, vektör depolama için asenkron işlemleri destekler. Tüm yöntemler, asenkron işlevleriyle çağrılabilir ve a önekiyle işaretlenmiş olarak asenkron olarak kullanılabilir.
Qdrant, tüm asenkron işlemleri destekleyen bir vektör deposudur. Aşağıda Qdrant'ı kullanan bir örnek bulunmaktadır.
pip install qdrant-client
from langchain_community.vectorstores import Qdrant
Asenkron Vektör Deposu Oluşturma
db = await Qdrant.afrom_documents(dokümanlar, gömme, "http://localhost:6333")
Benzerlik Araması
sorgu = "Başkan Ketanji Brown Jackson'a ne dedi?"
belgeler = await db.asimilarity_search(sorgu)
print(belgeler[0].page_content)
Vektör Tabanlı Arama
embedding_vector = gömme.embed_query(sorgu)
belgeler = await db.asimilarity_search_by_vector(embedding_vector)
Maksimal Marjinal İlgili (MMR) Araması
Maksimal Marjinal İlgili, sorguyla benzerliği ve seçilen belgeler arasındaki çeşitliliği optimize eder. Ayrıca asenkron bir API'yi destekler.
sorgu = "Başkan Ketanji Brown Jackson'a ne dedi?"
bulunan_belgeler = await qdrant.amax_marginal_relevance_search(sorgu, k=2, fetch_k=10)
for i, belge in enumerate(bulunan_belgeler):
print(f"{i + 1}.", belge.page_content, "\n")