Archivio Vettoriale
- Vai a Integrazioni per conoscere tutti i motori di archiviazione vettoriale di terze parti supportati ufficialmente da LangChain.
La soluzione più comune per archiviare e cercare dati non strutturati è calcolare vettori di caratteristiche dei dati e quindi cercare vettori simili in base alla similarità vettoriale durante le interrogazioni. Un database vettoriale è responsabile per fornire motori di archiviazione dati per archiviare e interrogare vettori.
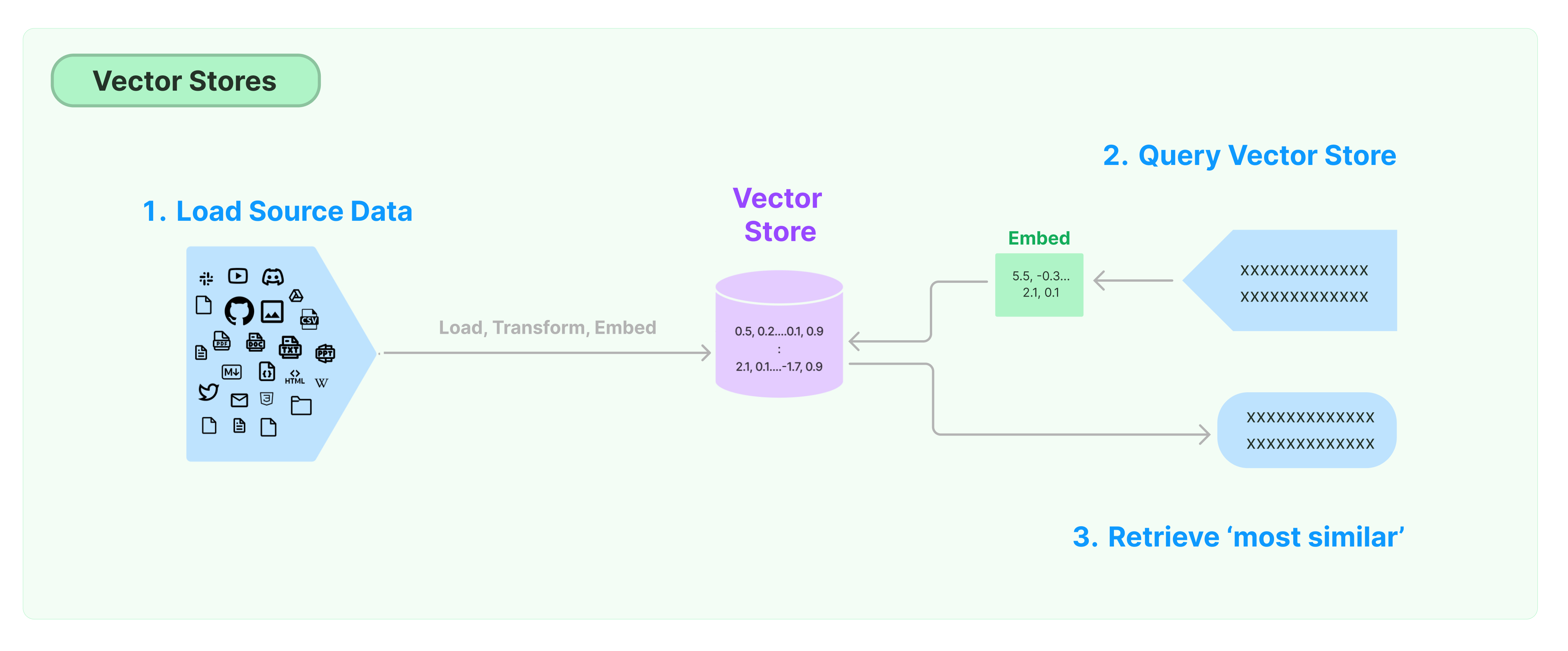
Iniziare con LangChain Vector Store
Questa guida introduce le funzionalità di base relative ai Vector Store. Il componente chiave che lavora con l'archiviazione vettoriale è il modello di embedding (responsabile del calcolo dei vettori di caratteristiche). Pertanto, è consigliabile imparare come calcolare vettori di testo con il modello di embedding di testo prima di studiare questo capitolo.
Ci sono molti eccellenti motori di archiviazione vettoriale. Di seguito, introduciamo l'uso di 3 motori di archiviazione vettoriale gratuiti e open source nel framework LangChain.
Chroma
Questo capitolo utilizza il database vettoriale chroma, che viene eseguito in locale come libreria Python.
pip install chromadb
Qui, utilizziamo il modello di embedding OpenAI per calcolare i vettori, quindi dobbiamo ottenere la chiave API di OpenAI.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('Chiave API OpenAI:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
FAISS
Questo capitolo utilizza il database vettoriale FAISS, che utilizza la libreria Facebook AI Similarity Search (FAISS).
pip install faiss-cpu
Qui, utilizziamo il modello di embedding OpenAI per calcolare i vettori, quindi dobbiamo ottenere la chiave API di OpenAI.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('Chiave API OpenAI:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = FAISS.from_documents(documents, OpenAIEmbeddings())
Lance
In questo capitolo, introdurremo come il framework LangChain utilizza il database vettoriale LanceDB.
pip install lancedb
Qui, utilizziamo il modello di embedding di OpenAI per calcolare i vettori, quindi dobbiamo ottenere la chiave API di OpenAI.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('Chiave API OpenAI:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import LanceDB
import lancedb
db = lancedb.connect("/tmp/lancedb")
table = db.create_table(
"my_table",
data=[
{
"vector": embeddings.embed_query("Ciao Mondo"),
"text": "Ciao Mondo",
"id": "1",
}
],
mode="sovrascriere",
)
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = LanceDB.from_documents(documents, OpenAIEmbeddings(), connection=table)
Ricerca di Similarità
query = "Cosa ha detto il Presidente a Ketanji Brown Jackson?"
docs = db.similarity_search(query)
print(docs[0].page_content)
Ricerca di similarità vettoriale
Utilizza similarity_search_by_vector per eseguire una ricerca di similarità basata sul vettore fornito. Questa funzione prende come parametro un vettore di embedding anziché una stringa.
embedding_vector = OpenAIEmbeddings().embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
print(docs[0].page_content)
Operazioni asincrone
Lo storage vettoriale spesso funziona come un servizio indipendente e richiede alcune operazioni di I/O. È pertanto consigliato utilizzare chiamate asincrone all'interfaccia del database vettoriale, in modo da migliorare le prestazioni senza dover attendere le risposte da servizi esterni.
Langchain supporta operazioni asincrone per lo storage vettoriale. Tutti i metodi possono essere chiamati utilizzando le loro funzioni asincrone con il prefisso a, ad esempio async.
Qdrant è uno storage vettoriale che supporta tutte le operazioni asincrone. Di seguito è riportato un esempio di utilizzo di Qdrant.
pip install qdrant-client
from langchain_community.vectorstores import Qdrant
Creazione di uno Storage Vettoriale Asincrono
db = await Qdrant.afrom_documents(documents, embeddings, "http://localhost:6333")
Ricerca di Similarità
query = "Cosa ha detto il Presidente a Ketanji Brown Jackson?"
docs = await db.asimilarity_search(query)
print(docs[0].page_content)
Ricerca basata su Vettori
embedding_vector = embeddings.embed_query(query)
docs = await db.asimilarity_search_by_vector(embedding_vector)
Ricerca di Massima Rilevanza Marginale (MMR)
La Ricerca di Massima Rilevanza Marginale ottimizza la similarità con la query e la diversità tra i documenti selezionati. Supporta anche un'API asincrona.
query = "Cosa ha detto il Presidente a Ketanji Brown Jackson?"
found_docs = await qdrant.amax_marginal_relevance_search(query, k=2, fetch_k=10)
for i, doc in enumerate(found_docs):
print(f"{i + 1}.", doc.page_content, "\n")