Vektor-Speicher
- Gehe zu Integrationen, um alle offiziell von LangChain unterstützten vektorbasierten Speicherengines von Drittanbietern kennenzulernen.
Die häufigste Lösung zur Speicherung und Suche unstrukturierter Daten besteht darin, Merkmalsvektoren der Daten zu berechnen und anschließend bei Abfragen nach ähnlichen Vektoren basierend auf Vektorsimilarität zu suchen. Eine Vektordatenbank ist dafür verantwortlich, Speicherengines für die Speicherung und Abfrage von Vektoren bereitzustellen.
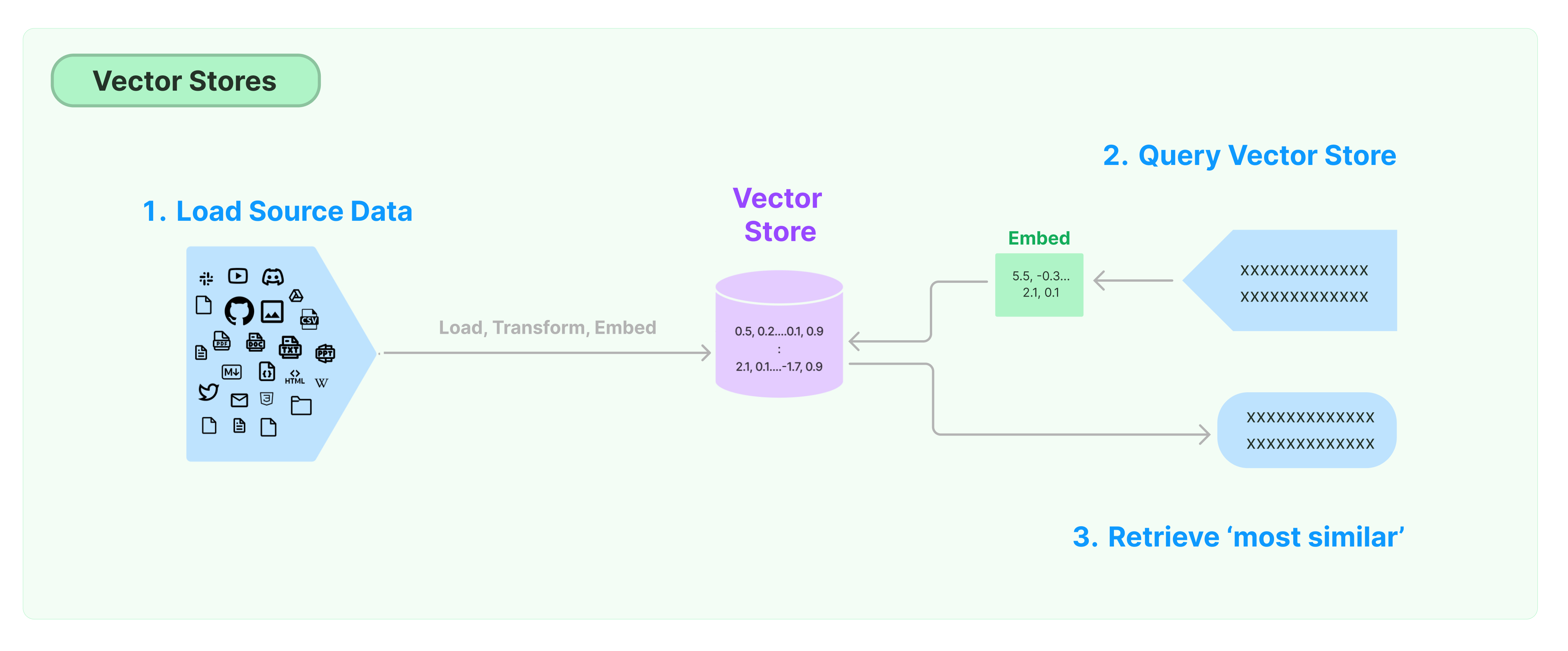
Einführung in den LangChain Vektor-Speicher
Dieser Leitfaden stellt die grundlegenden Funktionalitäten im Zusammenhang mit Vektor-Speichern vor. Die Schlüsselkomponente bei der Arbeit mit vektorbasiertem Speicher ist das Einbettungsmodell (zuständig für die Berechnung von Merkmalsvektoren). Daher wird empfohlen, sich vor dem Studium dieses Kapitels damit vertraut zu machen, wie man Textvektoren mit dem Text-Einbettungsmodell berechnet.
Es gibt viele hervorragende vektorbasierte Speicherengines. Im Folgenden stellen wir die Verwendung von 3 kostenlosen und Open-Source Vektor-Speicherengines im LangChain-Framework vor.
Chroma
In diesem Kapitel wird die Chroma Vektordatenbank verwendet, die lokal als Python-Bibliothek ausgeführt wird.
pip install chromadb
Hier verwenden wir das OpenAI-Einbettungsmodell, um die Vektoren zu berechnen, daher benötigen wir den OpenAI API-Schlüssel.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
FAISS
In diesem Kapitel wird die FAISS Vektordatenbank verwendet, die die Facebook AI Similarity Search (FAISS) Bibliothek nutzt.
pip install faiss-cpu
Hier verwenden wir das OpenAI-Einbettungsmodell, um die Vektoren zu berechnen, daher benötigen wir den OpenAI API-Schlüssel.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = FAISS.from_documents(documents, OpenAIEmbeddings())
Lance
In diesem Kapitel wird veranschaulicht, wie das LangChain-Framework die LanceDB Vektordatenbank verwendet.
pip install lancedb
Hier verwenden wir das Einbettungsmodell von OpenAI zur Berechnung von Vektoren, daher benötigen wir den OpenAI API-Schlüssel.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import LanceDB
import lancedb
db = lancedb.connect("/tmp/lancedb")
table = db.create_table(
"my_table",
data=[
{
"vector": embeddings.embed_query("Hallo Welt"),
"text": "Hallo Welt",
"id": "1",
}
],
mode="overwrite",
)
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = LanceDB.from_documents(documents, OpenAIEmbeddings(), connection=table)
Ähnlichkeitssuche
query = "Was hat der Präsident zu Ketanji Brown Jackson gesagt?"
docs = db.similarity_search(query)
print(docs[0].page_content)
Vektors Similaritätssuche
Verwenden Sie similarity_search_by_vector, um eine Ähnlichkeitssuche basierend auf dem gegebenen Vektor durchzuführen. Diese Funktion nimmt einen Einbettungsvektor als Parameter anstelle eines Strings.
embedding_vector = OpenAIEmbeddings().embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
print(docs[0].page_content)
Asynchrone Operationen
Die Vektorspeicherung läuft oft als unabhängiger Dienst und erfordert einige I/O-Operationen. Verwenden Sie daher asynchrone Aufrufe an die Vektordatenbank-Schnittstelle. Dadurch kann die Leistung verbessert werden, da Sie nicht auf Antworten von externen Diensten warten müssen.
Langchain unterstützt asynchrone Operationen für die Vektorspeicherung. Alle Methoden können über ihre asynchronen Funktionen mit dem Präfix a aufgerufen werden, was auf async hinweist.
Qdrant ist eine Vektorspeicherung, die alle asynchronen Operationen unterstützt. Nachfolgend finden Sie ein Beispiel für die Verwendung von Qdrant.
pip install qdrant-client
from langchain_community.vectorstores import Qdrant
Asynchrone Vektorspeicherungserstellung
db = await Qdrant.afrom_documents(documents, embeddings, "http://localhost:6333")
Ähnlichkeitssuche
query = "Was hat der Präsident zu Ketanji Brown Jackson gesagt?"
docs = await db.asimilarity_search(query)
print(docs[0].page_content)
Vektorbasierte Suche
embedding_vector = embeddings.embed_query(query)
docs = await db.asimilarity_search_by_vector(embedding_vector)
Maximal Marginal Relevance (MMR) Suche
Maximal Marginal Relevance optimiert die Ähnlichkeit zur Abfrage und die Vielfalt zwischen ausgewählten Dokumenten. Es unterstützt auch eine asynchrone API.
query = "Was hat der Präsident zu Ketanji Brown Jackson gesagt?"
found_docs = await qdrant.amax_marginal_relevance_search(query, k=2, fetch_k=10)
for i, doc in enumerate(found_docs):
print(f"{i + 1}.", doc.page_content, "\n")