فروشگاه برداری
- به انتگرال ها مراجعه کنید تا در مورد تمام موتورهای فروشگاه بردار های شخص ثالثی که به طور رسمی توسط LangChain پشتیبانی می شوند، آموخته شود.
راه حل رایج برای ذخیره و جستجوی داده های بدون ساختار، محاسبه بردارهای ویژگی داده است و سپس در زمان پرس و جو، بر اساس تشابه بردار، بردارهای مشابه را جستجو می کند. پایگاه داده بردار مسئول فراهم کردن موتورهای ذخیره و جستجوی بردارها است.
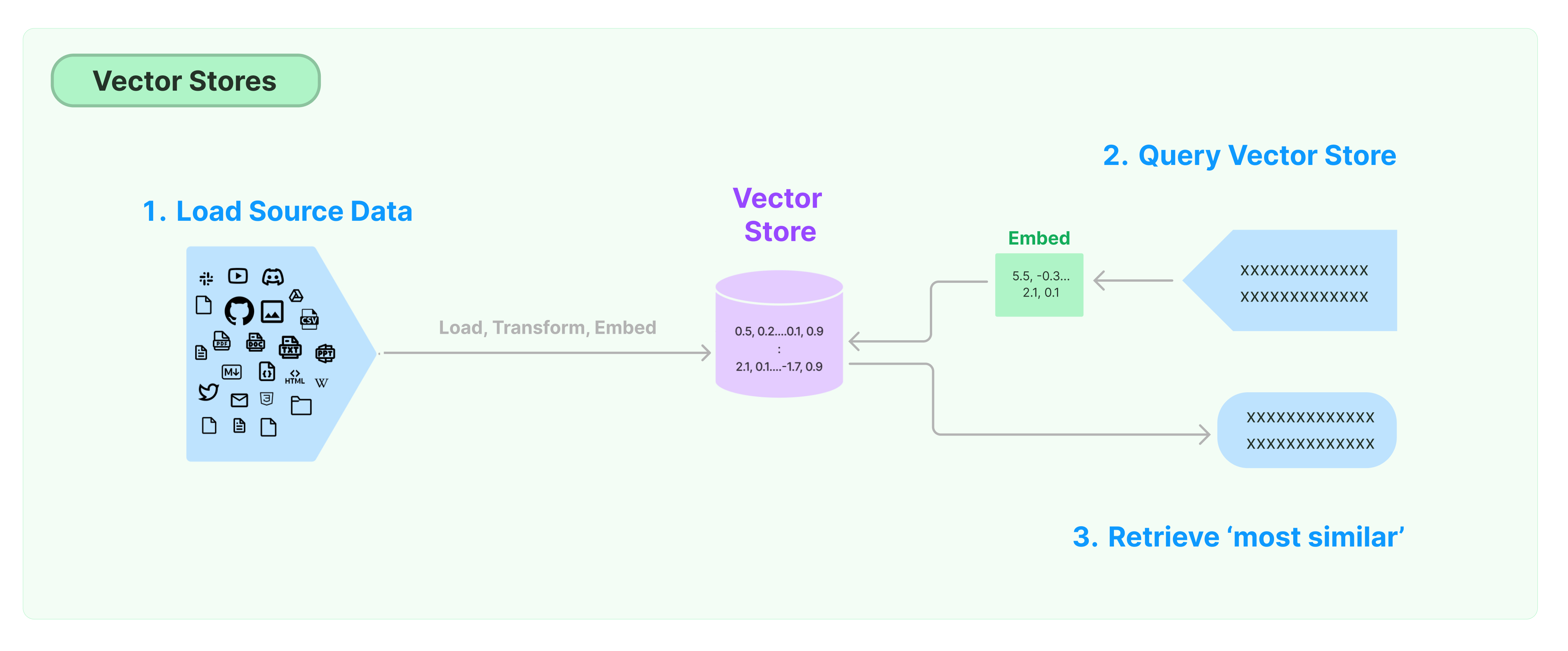
شروع با فروشگاه بردار LangChain
این راهنما ویژگی های پایه مربوط به فروشگاه های بردار را معرفی می کند. اصلی ترین قسمتی که با فروشگاه بردار کار می کند، مدل توکن گذاری است (مسئول محاسبه بردارهای ویژگی). بنابراین، توصیه می شود که قبل از مطالعه این فصل، یاد بگیرید چگونه با مدل توکن گذاری متن بردارهای متن را محاسبه کنید.
تعداد زیادی موتورهای فروشگاه بردار عالی وجود دارد. در زیر، ما به معرفی استفاده از ۳ موتور فروشگاه بردار آزاد و متن باز در چارچوب LangChain می پردازیم.
کروما
این فصل از پایگاه داده بردار کروما استفاده می کند که به صورت محلی به عنوان یک کتابخانه پایتون اجرا می شود.
pip install chromadb
در اینجا، ما از مدل توکن گذاری OpenAI برای محاسبه بردارها استفاده می کنیم، بنابراین نیاز داریم تا کلید API OpenAI را دریافت کنیم.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('کلید API OpenAI:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
فایس
در این فصل، از پایگاه داده بردار فایس استفاده می کنیم که از کتابخانه Facebook AI Similarity Search (FAISS) استفاده می کند.
pip install faiss-cpu
در اینجا، ما از مدل توکن گذاری OpenAI برای محاسبه بردارها استفاده می کنیم، بنابراین نیاز داریم تا کلید API OpenAI را دریافت کنیم.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('کلید API OpenAI:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = FAISS.from_documents(documents, OpenAIEmbeddings())
لنس
در این فصل، ما به شما چگونگی استفاده از پایگاه داده بردار LanceDB در چارچوب LangChain را معرفی می کنیم.
pip install lancedb
در اینجا، ما از مدل توکن گذاری OpenAI برای محاسبه بردارها استفاده می کنیم، بنابراین نیاز داریم تا کلید API OpenAI را دریافت کنیم.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('کلید API OpenAI:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import LanceDB
import lancedb
db = lancedb.connect("/tmp/lancedb")
table = db.create_table(
"my_table",
data=[
{
"vector": embeddings.embed_query("Hello World"),
"text": "Hello World",
"id": "1",
}
],
mode="overwrite",
)
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = LanceDB.from_documents(documents, OpenAIEmbeddings(), connection=table)
جستجوی تشابه
query = "چه چیزی رئیس جمهور به کتانجی براون جکسون گفت؟"
docs = db.similarity_search(query)
print(docs[0].page_content)
جستجوی مشابهت بردار
استفاده از similarity_search_by_vector برای انجام جستجوی مشابهت بر اساس بردار داده شده. این تابع یک بردار تعبیه را به عنوان پارامتر میپذیرد به جای یک رشته.
embedding_vector = OpenAIEmbeddings().embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
print(docs[0].page_content)
عملیات ناهمگام
ذخیرهسازی بردار معمولاً به عنوان یک سرویس مستقل اجرا میشود و نیازمند برخی عملیات IO میباشد. بنابراین، از فراخوانیهای ناهمگام برای رابط پایگاه داده بردار استفاده کنید. این کار میتواند کارایی را بهبود بخشد زیرا نیازی به انتظار پاسخ از خدمات خارجی ندارید.
Langchain از عملیات ناهمگام برای ذخیرهسازی بردار پشتیبانی میکند. تمام متدها میتوانند با استفاده از توابع ناهمگام خود با پیشوند a که async را مشخص میکند فراخوانی شوند.
Qdrant یک ذخیرهسازی بردار است که تمام عملیات ناهمگام را پشتیبانی میکند. در زیر نمونهای از استفاده از Qdrant آمده است.
pip install qdrant-client
from langchain_community.vectorstores import Qdrant
ایجاد ذخیرهسازی بردار ناهمگام
db = await Qdrant.afrom_documents(documents, embeddings, "http://localhost:6333")
جستجوی مشابهت
query = "رئیس جمهور به کتانجی براون جکسون چه گفت؟"
docs = await db.asimilarity_search(query)
print(docs[0].page_content)
جستجوی بر اساس بردار
embedding_vector = embeddings.embed_query(query)
docs = await db.asimilarity_search_by_vector(embedding_vector)
جستجوی حداکثر حاشیه مارجینال (MMR)
جستجوی حداکثر حاشیه مارجینال برتری مشابهت به پرس و جو و تنوع بین اسناد انتخابی را بهینه میکند. این همچنین از یک API ناهمگام پشتیبانی میکند.
query = "رئیس جمهور به کتانجی براون جکسون چه گفت؟"
found_docs = await qdrant.amax_marginal_relevance_search(query, k=2, fetch_k=10)
for i, doc in enumerate(found_docs):
print(f"{i + 1}.", doc.page_content, "\n")