Toko Vektor
- Pergi ke Integrasi untuk mempelajari semua mesin penyimpanan vektor pihak ketiga yang didukung secara resmi oleh LangChain.
Solusi paling umum untuk menyimpan dan mencari data tanpa struktur adalah dengan menghitung vektor fitur data, dan kemudian mencari vektor serupa berdasarkan kesamaan vektor saat melakukan kueri. Basis data vektor bertanggung jawab untuk menyediakan mesin penyimpanan data untuk menyimpan dan menanyakan vektor.
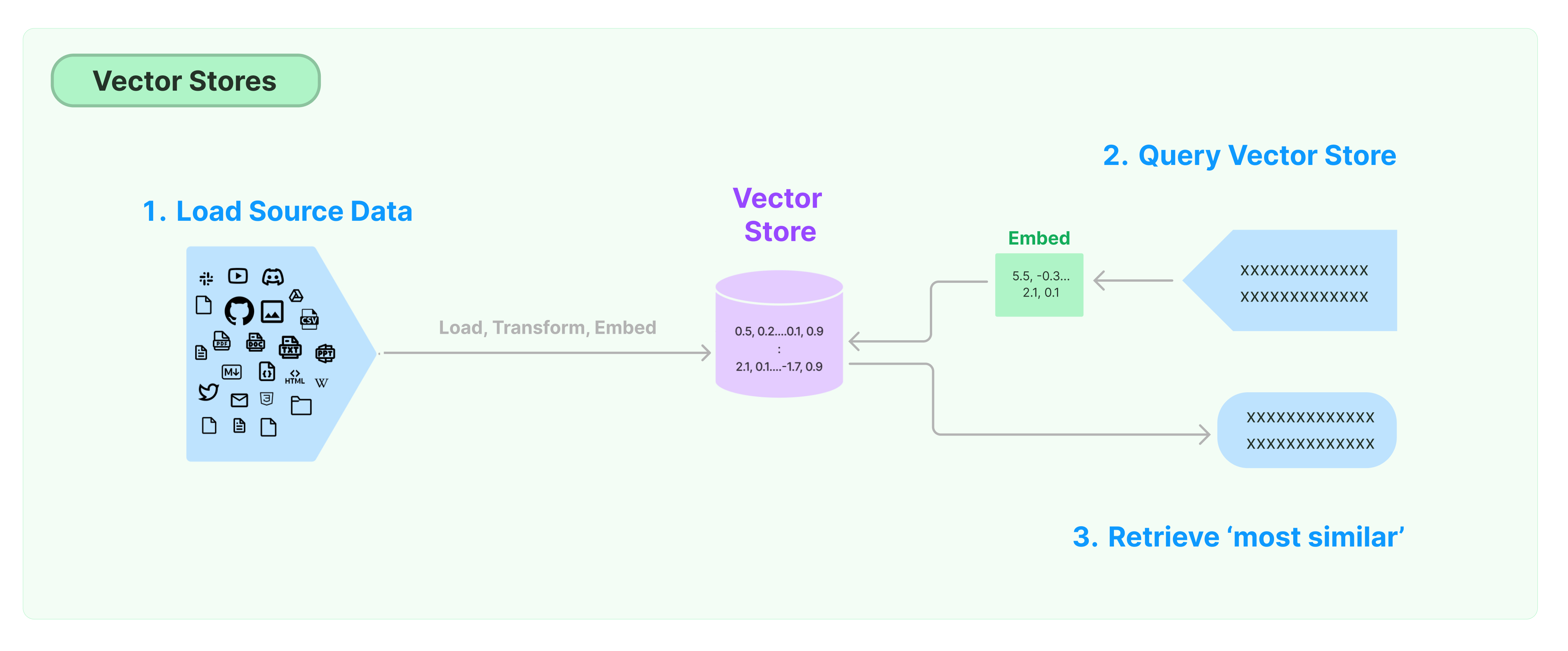
Memulai dengan Toko Vektor LangChain
Panduan ini memperkenalkan fungsionalitas dasar terkait Toko Vektor. Komponen kunci dalam bekerja dengan penyimpanan vektor adalah model embedding (bertanggung jawab untuk menghitung vektor fitur). Oleh karena itu, disarankan untuk mempelajari cara menghitung vektor teks dengan model embedding teks sebelum mempelajari bab ini.
Ada banyak mesin penyimpanan vektor yang sangat baik. Di bawah ini, kami memperkenalkan penggunaan 3 mesin penyimpanan vektor gratis dan open-source dalam kerangka kerja LangChain.
Chroma
Bab ini menggunakan basis data vektor chroma, yang berjalan secara lokal sebagai perpustakaan Python.
pip install chromadb
Di sini, kami menggunakan model embedding OpenAI untuk menghitung vektor, jadi kita perlu mendapatkan kunci API OpenAI.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('Kunci API OpenAI:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
FAISS
Bab ini menggunakan basis data vektor FAISS, yang memanfaatkan pustaka Pencarian Kesamaan Kecerdasan Buatan (FAISS) dari Facebook.
pip install faiss-cpu
Di sini, kami menggunakan model embedding OpenAI untuk menghitung vektor, jadi kita perlu mendapatkan kunci API OpenAI.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('Kunci API OpenAI:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = FAISS.from_documents(documents, OpenAIEmbeddings())
Lance
Dalam bab ini, kami akan memperkenalkan bagaimana kerangka kerja LangChain menggunakan basis data vektor LanceDB.
pip install lancedb
Di sini, kami menggunakan model embedding OpenAI untuk menghitung vektor, jadi kita perlu mendapatkan kunci API OpenAI.
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('Kunci API OpenAI:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import LanceDB
import lancedb
db = lancedb.connect("/tmp/lancedb")
table = db.create_table(
"my_table",
data=[
{
"vector": embeddings.embed_query("Halo Dunia"),
"teks": "Halo Dunia",
"id": "1",
}
],
mode="overwrite",
)
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = LanceDB.from_documents(documents, OpenAIEmbeddings(), connection=table)
Pencarian Kesamaan
query = "Apa yang Presiden katakan kepada Ketanji Brown Jackson?"
dokumen = db.similarity_search(query)
print(dokumen[0].konten_halaman)
Pencarian Kesamaan Vektor
Gunakan similarity_search_by_vector untuk melakukan pencarian kesamaan berdasarkan vektor yang diberikan. Fungsi ini mengambil vektor embedding sebagai parameter daripada string.
embedding_vector = OpenAIEmbeddings().embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
print(docs[0].page_content)
Operasi Asynchronous
Penyimpanan vektor sering berjalan sebagai layanan mandiri dan memerlukan beberapa operasi IO. Oleh karena itu, gunakan panggilan asynchronous ke antarmuka basis data vektor. Hal ini dapat meningkatkan kinerja karena Anda tidak perlu membuang waktu menunggu respon dari layanan eksternal.
Langchain mendukung operasi asynchronous untuk penyimpanan vektor. Semua metode dapat dipanggil menggunakan fungsi asynchronous mereka dengan awalan a, menandakan async.
Qdrant adalah penyimpanan vektor yang mendukung semua operasi asynchronous. Berikut adalah contoh penggunaan Qdrant.
pip install qdrant-client
from langchain_community.vectorstores import Qdrant
Pembuatan Penyimpanan Vektor Asynchronous
db = await Qdrant.afrom_documents(documents, embeddings, "http://localhost:6333")
Pencarian Kesamaan
query = "Apa yang dikatakan Presiden kepada Ketanji Brown Jackson?"
docs = await db.asimilarity_search(query)
print(docs[0].page_content)
Pencarian Berbasis Vektor
embedding_vector = embeddings.embed_query(query)
docs = await db.asimilarity_search_by_vector(embedding_vector)
Pencarian Maksimal Marginal Relevance (MMR)
Maximal Marginal Relevance mengoptimalkan kesamaan dengan kueri dan keragaman antara dokumen yang dipilih. Ini juga mendukung API asynchronous.
query = "Apa yang dikatakan Presiden kepada Ketanji Brown Jackson?"
found_docs = await qdrant.amax_marginal_relevance_search(query, k=2, fetch_k=10)
for i, doc in enumerate(found_docs):
print(f"{i + 1}.", doc.page_content, "\n")