ویکٹر اسٹور
- انٹیگریشنز پر جائیں اور LangChain کی طرف سے آفیشل طورپر سپورٹ کیے جانے والے تمام تھرڈ پارٹی ویکٹر اسٹور انجنز کے بارے میں جاننے کے لئے.
غیر ساختہ ڈیٹا کو ذخیرہ اور تلاش کرنے کا سب سے عام حل ڈیٹا کے فیچر ویکٹرز کا حساب کرنا ہے، اور پھر جواب دیتے وقت ویکٹر مماثلت پر مبنی مماثل ویکٹرز کو تلاش کرنا ہے۔ ایک ویکٹر ڈیٹا بیس ویکٹرز کو ذخیرہ اور تلاش کرنے کے لئے ڈیٹا انجنز فراہم کرنے کے لئے ذمہ دار ہوتا ہے۔
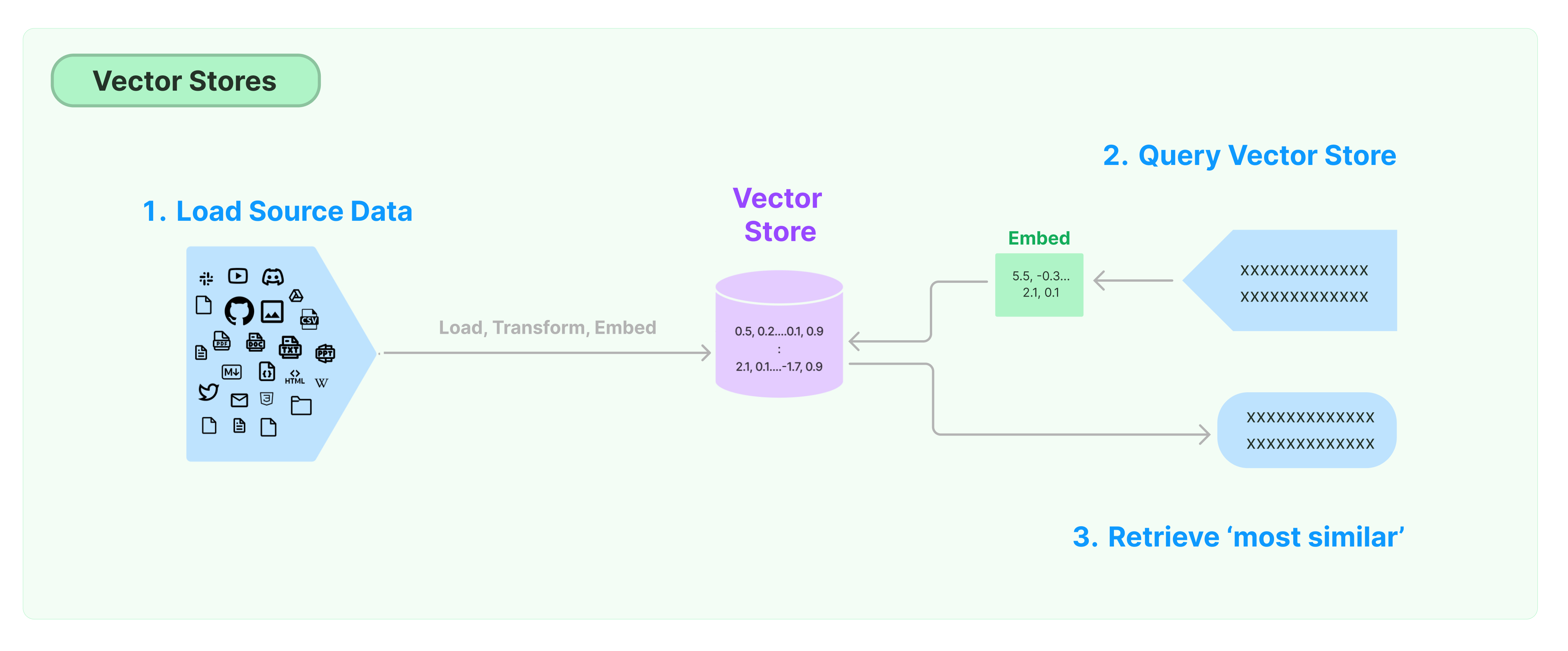
لینگ چین ویکٹر اسٹور کے ساتھ شروع ہونا
یہ گائیڈ ویکٹر اسٹور کے متعلق بنیادی فعالیتوں کا تعارف کراتا ہے۔ ویکٹر اسٹور کے ساتھ کام کرنے والا اہم جزو امبیڈنگ ماڈل ہے (جو فیچر ویکٹرز کا حساب کرنے کے لئے ذمہ دار ہے)۔ لہذا، اس سے پہلے کے چاپٹر کو مطالعہ کرنے سے پہلے ٹیکسٹ امبیڈنگ ماڈل سے ٹیکسٹ ویکٹرز کا حساب کرنے کا طریقہ سیکھنے کا مشورہ دیا گیا ہے۔
بہت سارے عمدہ ویکٹر اسٹور انجنز ہیں۔ نیچے، ہم LangChain فریم ورک میں شامل تین مفت اور آپریشن کوڈ ویکٹر اسٹور انجنز کے استعمال کا تعارف کراتے ہیں۔
کروما
اس باب میں chroma ویکٹر ڈیٹا بیس کا استعمال کیا گیا ہے، جو کہ مقامی طور پر ایک پائتھن لائبریری کے طور پر چلتا ہے۔
pip install chromadb
یہاں، ہم اوپن اےآئی امبیڈنگ ماڈل کا استعمال کر کے ویکٹرز حاصل کرنے ہیں، لہذا ہمیں اوپن اےآئی اےپیآئی کی کلید حاصل کرنی ہوگی۔
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
فیس
اس باب میں FAISS ویکٹر ڈیٹا بیس کا استعمال کیا گیا ہے، جو کہ فیس بک اےآئی مشابہت تلاش (FAISS) کتابخانے کا استعمال کرتا ہے۔
pip install faiss-cpu
یہاں، ہم اوپن اےآئی امبیڈنگ ماڈل کا استعمال کر کے ویکٹرز حاصل کرنے ہیں، لہذا ہمیں اوپن اےآئی اےپیآئی کی کلید حاصل کرنی ہوگی۔
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = FAISS.from_documents(documents, OpenAIEmbeddings())
لانس
اس باب میں، ہم بتائیں گے کہ لینگ چین فریم ورک کس طرح لانس ڈی بی ویکٹر ڈیٹا بیس کا استعمال کرتا ہے۔
pip install lancedb
یہاں، ہم اوپن اےآئی کے ایمبیڈنگ ماڈل کا استعمال کر کے ویکٹرز حاصل کر رہے ہیں، لہذا ہمیں اوپن اےآئی کی اےپیآئی کی کلید حاصل کرنی ہوگی۔
import os
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import LanceDB
import lancedb
db = lancedb.connect("/tmp/lancedb")
table = db.create_table(
"my_table",
data=[
{
"vector": embeddings.embed_query("Hello World"),
"text": "Hello World",
"id": "1",
}
],
mode="overwrite",
)
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = LanceDB.from_documents(documents, OpenAIEmbeddings(), connection=table)
مشابہت تلاش
query = "What did the President say to Ketanji Brown Jackson?"
docs = db.similarity_search(query)
print(docs[0].page_content)
ویکٹر مماثلت تلاش
similarity_search_by_vector استعمال کریں تا دئے گئے ویکٹر کی بنیاد پر مماثلت تلاش کی جائے۔ اس فنکشن میں سٹرنگ کی بجائے ایمبیڈنگ ویکٹر کو پیرامیٹر کے طور پر استعمال کیا جاتا ہے۔
embedding_vector = OpenAIEmbeddings().embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
print(docs[0].page_content)
اوسط ج امکانات
ویکٹر اسٹوریج عام طور پر ایک آزاد خدمت کے طور پر چلتا ہے اور کچھ آئی او عملیات کی ضرورت ہوتی ہے۔ اسلئے، ویکٹر ڈیٹا بیس انٹرفیس کے لئے اوسط ج پکار کا استعمال کریں۔ یہ عمل عمل کی کارکردگی کو بہتر بنا سکتا ہے کیونکہ آپ کو بیرونی خدمات سے جوابات کےلئے انتظار کرنے کا وقت ضائع نہیں ہوگا۔
لینگچین ویکٹر اسٹوریج کو اوسط ج امکانات کی حمایت کرتا ہے۔ تمام تراکیب کے لئے ان کو ان کے اوسط ج کردار کے ساتھ کسی بھی عمل کو بغیر کسی رکاوٹ کے پکارا جا سکتا ہے۔ پایے گئے نمونے میں کوڈ کا ذکر ہے۔
pip install qdrant-client
from langchain_community.vectorstores import Qdrant
اوسط ج ویکٹر اسٹوریج کی تشکیل
db = await Qdrant.afrom_documents(documents, embeddings, "http://localhost:6333")
مماثلت تلاش
query = "صدر نے کیا کہا کہ Ketanji Brown Jackson کو؟"
docs = await db.asimilarity_search(query)
print(docs[0].page_content)
ویکٹر بیس تلاش
embedding_vector = embeddings.embed_query(query)
docs = await db.asimilarity_search_by_vector(embedding_vector)
زیادہ سے زیادہ زاویائی رو
زیادہ سے زیادہ زاویائی رو سیکھنے یا منتخب کردہ دستاویزات کے درمیان مشابہت اور مختلفت کی بهتری کرتا ہے۔ یہ بھی اوسط ج API کی حمایت کرتا ہے۔
query = "صدر نے کیا کہا کہ Ketanji Brown Jackson کو؟"
found_docs = await qdrant.amax_marginal_relevance_search(query, k=2, fetch_k=10)
for i, doc in enumerate(found_docs):
print(f"{i + 1}.", doc.page_content, "\n")