
Eine Vektordatenbank ist eine relativ neue Methode zur Interaktion mit abstrakten Datenrepräsentationen, die aus undurchsichtigen maschinellen Lernmodellen wie tiefen Lernstrukturen stammen. Diese Repräsentationen werden allgemein als Vektoren oder Einbettungsvektoren bezeichnet und sind komprimierte Versionen der Daten, die zur Schulung von maschinellen Lernmodellen für Aufgaben wie Sentimentanalyse, Spracherkennung und Objekterkennung verwendet werden.
Diese neuen Datenbanken haben in vielen Anwendungen, wie etwa semantische Suche und Empfehlungssysteme, eine herausragende Leistung gezeigt.
Was ist Qdrant?
Qdrant ist eine Open-Source-Vektordatenbank, die für KI-Anwendungen der nächsten Generation konzipiert ist. Sie ist cloudnativ und bietet RESTful- und gRPC-APIs zum Verwalten von Einbettungen. Qdrant bietet leistungsstarke Funktionen und unterstützt die Suche nach Bildern, Stimmen und Videos sowie die Integration mit KI-Engines.
Was ist eine Vektordatenbank?
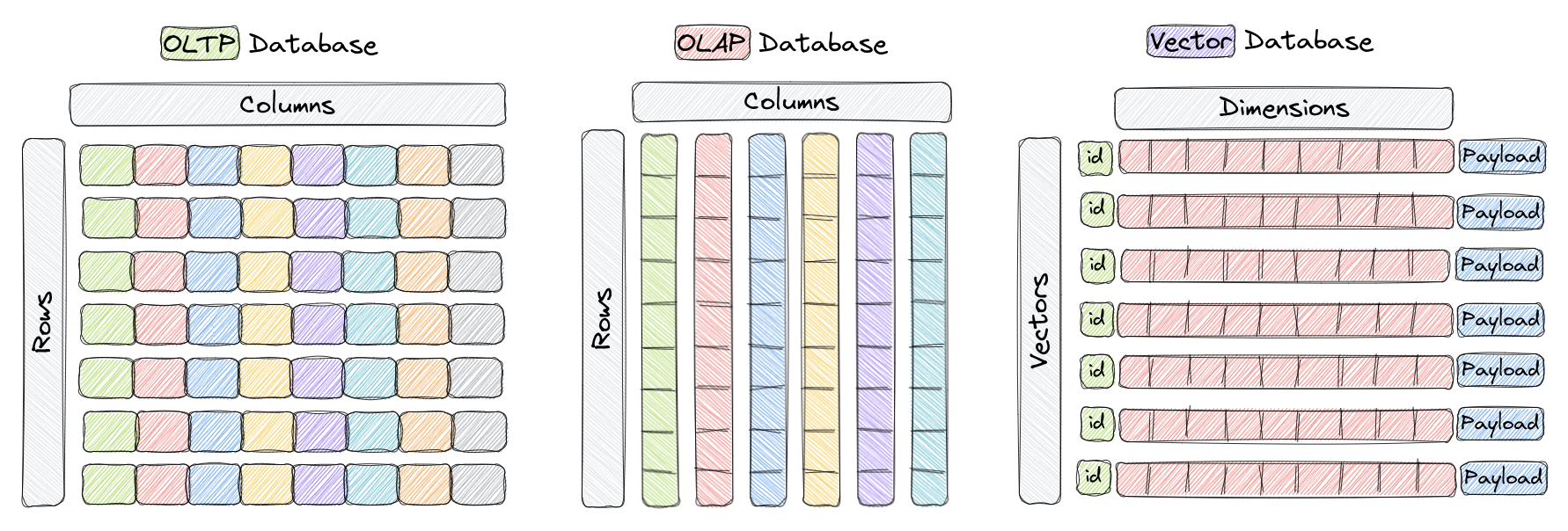
Eine Vektordatenbank ist ein speziell für die effiziente Speicherung und Abfrage hochdimensionaler Vektoren konzipierter Datenbanktyp. In herkömmlichen OLTP- und OLAP-Datenbanken (wie im obigen Bild gezeigt) sind Daten in Zeilen und Spalten (als Tabellen bezeichnet) organisiert, und Abfragen basieren auf den Werten in diesen Spalten. In bestimmten Anwendungen wie der Bilderkennung, der natürlichen Sprachverarbeitung und Empfehlungssystemen werden Daten jedoch häufig in Form von Vektoren in einem hochdimensionalen Raum dargestellt. Diese Vektoren, zusammen mit einer ID und Payload, bilden die Elemente, die in Vektordatenbanken wie Qdrant gespeichert sind.
In diesem Zusammenhang ist ein Vektor die mathematische Darstellung eines Objekts oder Datenpunkts, wobei jedes Element des Vektors einem Merkmal oder Attribut des Objekts entspricht. Zum Beispiel kann in einem Bilderkennungssystem ein Vektor ein Bild repräsentieren, wobei jedes Element des Vektors Pixelwerte oder das Merkmal/Deskriptor des Pixels repräsentiert. In einem Musikempfehlungssystem repräsentiert jeder Vektor ein Lied, wobei jedes Element des Vektors ein Merkmal des Lieds wie Rhythmus, Genre, Text usw. darstellt.
Vektordatenbanken sind auf die effiziente Speicherung und Abfrage hochdimensionaler Vektoren optimiert und nutzen häufig spezialisierte Datenstrukturen und Indexierungstechniken wie Hierarchical Navigable Small World (HNSW) für eine approximative nächste Nachbarsuche und Produktquantisierung. Diese Datenbanken ermöglichen es den Benutzern, die nächsten Vektoren zu einem bestimmten Abfragevektor gemäß einer bestimmten Distanzmetrik zu finden, was eine schnelle Ähnlichkeits- und semantische Suche ermöglicht. Zu den am häufigsten verwendeten Distanzmetriken gehören die euklidische Distanz, die Kosinusähnlichkeit und das Skalarprodukt, die alle von Qdrant voll unterstützt werden.
Hier ist eine kurze Einführung in diese drei Vektorsimilaritätsalgorithmen:
- Kosinusähnlichkeit - Die Kosinusähnlichkeit ist ein Maß für die Ähnlichkeit zwischen zwei Elementen. Man kann sie als ein Lineal betrachten, das zur Messung des Abstands zwischen zwei Punkten verwendet wird. Anstatt jedoch den Abstand zu messen, misst sie die Ähnlichkeit zwischen zwei Elementen. Sie wird häufig zum Vergleich der Ähnlichkeit zwischen zwei Dokumenten oder Sätzen in Texten verwendet. Der Ausgabeber
Warum brauchen wir eine Vektordatenbank?
Vektordatenbanken spielen eine entscheidende Rolle in verschiedenen Anwendungen, die eine Ähnlichkeitssuche erfordern, wie z.B. Empfehlungssysteme, inhaltsbasierte Bildsuche und personalisierte Suche. Durch effiziente Indexierung und Suchtechniken können Vektordatenbanken unstrukturierte Daten, die als Vektoren dargestellt sind, schneller und genauer abrufen und dem Benutzer die relevantesten Ergebnisse seiner Anfrage präsentieren.
Zu den weiteren Vorteilen der Verwendung einer Vektordatenbank gehören folgende:
- Effiziente Speicherung und Indexierung von hochdimensionalen Daten.
- Möglichkeit zur Handhabung von Datenmengen im großen Maßstab mit Milliarden von Datenpunkten.
- Unterstützung für Echtzeitanalyse und -abfragen.
- Fähigkeit zur Handhabung von Vektoren, die aus komplexen Datentypen wie Bildern, Videos und natürlichsprachlichen Texten abgeleitet sind.
- Verbesserung der Leistung von Anwendungen im Bereich maschinelles Lernen und künstliche Intelligenz bei gleichzeitiger Verringerung der Latenz.
- Reduzierung von Entwicklung und Bereitstellungszeit sowie Kosten im Vergleich zum Aufbau benutzerdefinierter Lösungen.
Bitte beachten Sie, dass die spezifischen Vorteile der Verwendung einer Vektordatenbank je nach den Anwendungsfällen Ihrer Organisation und den gewählten Datenbankfunktionalitäten variieren können.
Lassen Sie uns nun eine eingehende Bewertung der Qdrant-Architektur vornehmen.
Grundlegende Übersicht der Qdrant-Architektur
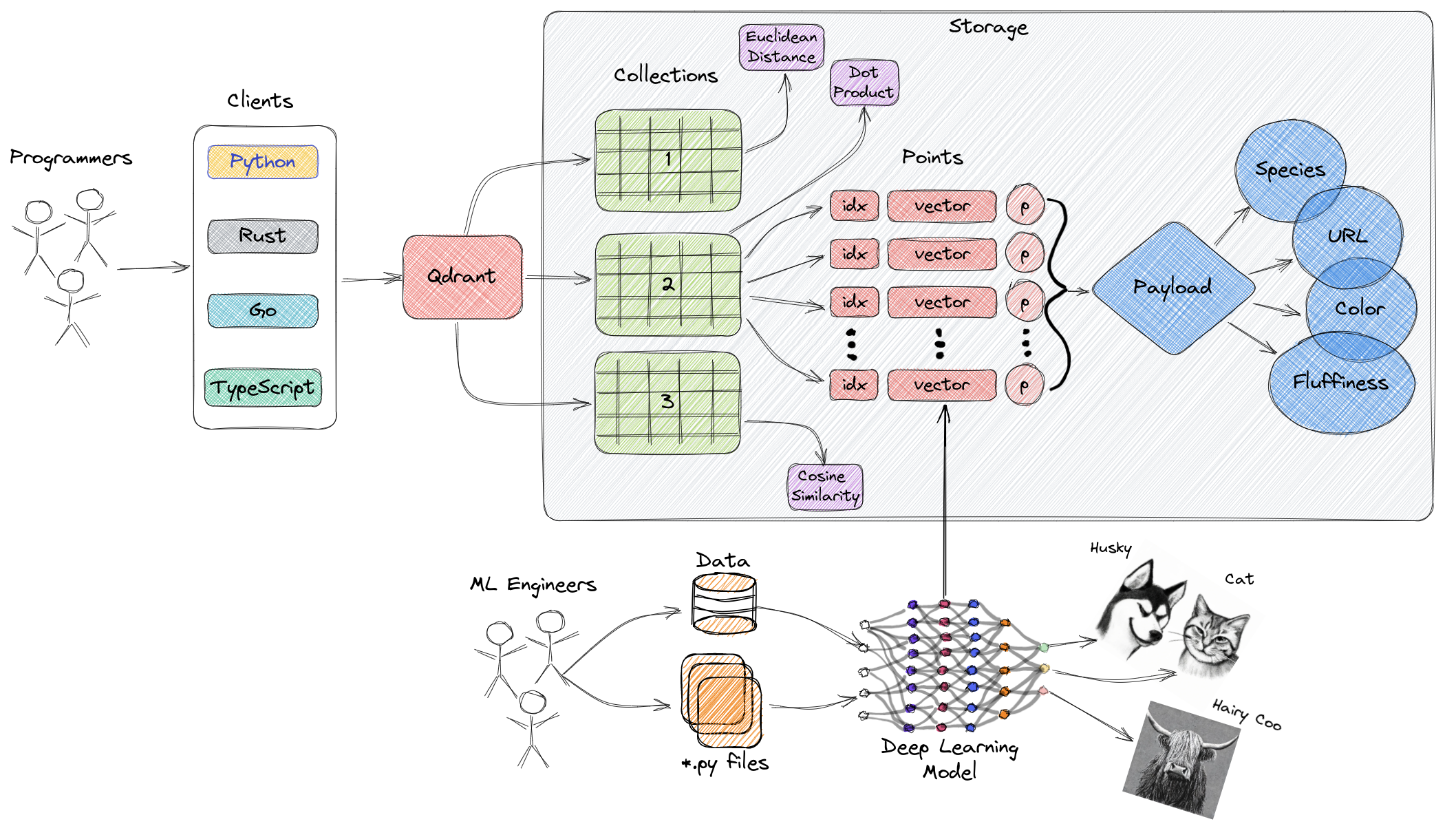
Das obige Diagramm bietet eine grundlegende Übersicht über die Hauptkomponenten von Qdrant. Die folgenden Begriffe sind mit Qdrant verbunden:
- Sammlungen: Sammlungen sind eine Gruppe benannter Punkte (Vektoren mit Payloads - im Wesentlichen Vektordaten). In einfacheren Worten sind Sammlungen ähnlich wie Tabellen in MySQL, und Punkte ähneln den in diesen Tabellen enthaltenen Datenzeilen. Die Suche kann unter diesen Punkten durchgeführt werden. Jeder Vektor innerhalb derselben Sammlung muss dieselbe Dimension haben und mit einer einzigen Metrik verglichen werden. Benannte Vektoren können verwendet werden, um mehrere Vektoren in einem einzigen Punkt zu haben, von denen jeder seine eigene Dimension und metrische Anforderungen hat.
- Metrik: Ein Maß, das zur Quantifizierung der Ähnlichkeit zwischen Vektoren verwendet wird und bei der Erstellung einer Sammlung ausgewählt werden muss. Die Wahl der Metrik hängt von der Methode der Vektorgewinnung ab, insbesondere für neuronale Netzwerke, die zur Codierung neuer Abfragen verwendet werden (die Metrik ist der Ähnlichkeitsalgorithmus, den wir wählen).
- Punkte: Punkte sind die Kernentitäten, mit denen Qdrant arbeitet, bestehend aus Vektoren, optionalen IDs und Payloads (ähnlich den Datenzeilen in einer MySQL-Tabelle).
- ID: Eindeutiger Identifikator des Vektors.
- Vektor: Hochdimensionale Darstellung von Daten, wie z.B. Bilder, Audio, Dokumente, Videos usw.
- Payload: Ein JSON-Objekt, das dem Vektor als zusätzliche Daten hinzugefügt werden kann (hauptsächlich zur Speicherung von Geschäftseigenschaften, die mit dem Vektor verbunden sind).
- Speicher: Qdrant kann zwei Speicheroptionen nutzen - In-Memory-Speicher (alle Vektoren werden im Speicher gespeichert, was die höchste Geschwindigkeit bietet, da der Zugriff auf die Festplatte nur zur Persistenz verwendet wird) und Memmap-Speicher (Erstellung eines virtuellen Adressraums, der mit Dateien auf der Festplatte verknüpft ist).
- Clients: Sie können sich über Programmiersprachen-SDKs mit Qdrant verbinden oder direkt über die REST-API von Qdrant interagieren.