LLM Speicher
Die meisten auf LLM basierenden Anwendungen verfügen über eine Chat-Schnittstelle ähnlich wie WeChat. Eine wichtige Funktion des KI-Dialogprozesses ist die Fähigkeit, Informationen, die zuvor im Gespräch erwähnt wurden, zu referenzieren, ganz ähnlich wie im menschlichen Dialogprozess, ohne den vorherigen Inhalt wiederholen zu müssen. Menschen rufen automatisch historische Informationen ab.
Die Fähigkeit, historische Konversationsinformationen im LLM-Feld zu speichern, wird in der Regel als "Speicher" bezeichnet, ganz wie Menschen die Fähigkeit haben, sich zu erinnern. LangChain kapselt verschiedene Speicherfunktionskomponenten, die separat verwendet oder nahtlos in eine Kette integriert werden können.
Speicher-Komponenten müssen zwei grundlegende Operationen implementieren: Lesen und Schreiben.
Für verschiedene Kettenaufgabenkomponenten von LangChain wird, wenn Sie die Speicherfunktion aktivieren, eine ähnliche Logik ausgeführt:
- Beim Empfang der anfänglichen Benutzereingabe wird die Kettenaufgabe versuchen, relevante historische Informationen aus der Speicher-Komponente abzurufen und dann die historischen Informationen und die Benutzereingabe zu Veranlassungen zusammenzufügen, die an LLM übergeben werden.
- Beim Empfang des von LLM zurückgegebenen Inhalts wird das Ergebnis automatisch in der Speicher-Komponente gespeichert, um es beim nächsten Mal leicht abrufen zu können.
Der Prozess zur Implementierung der Speicherfähigkeit in LangChain ist im folgenden Diagramm dargestellt:
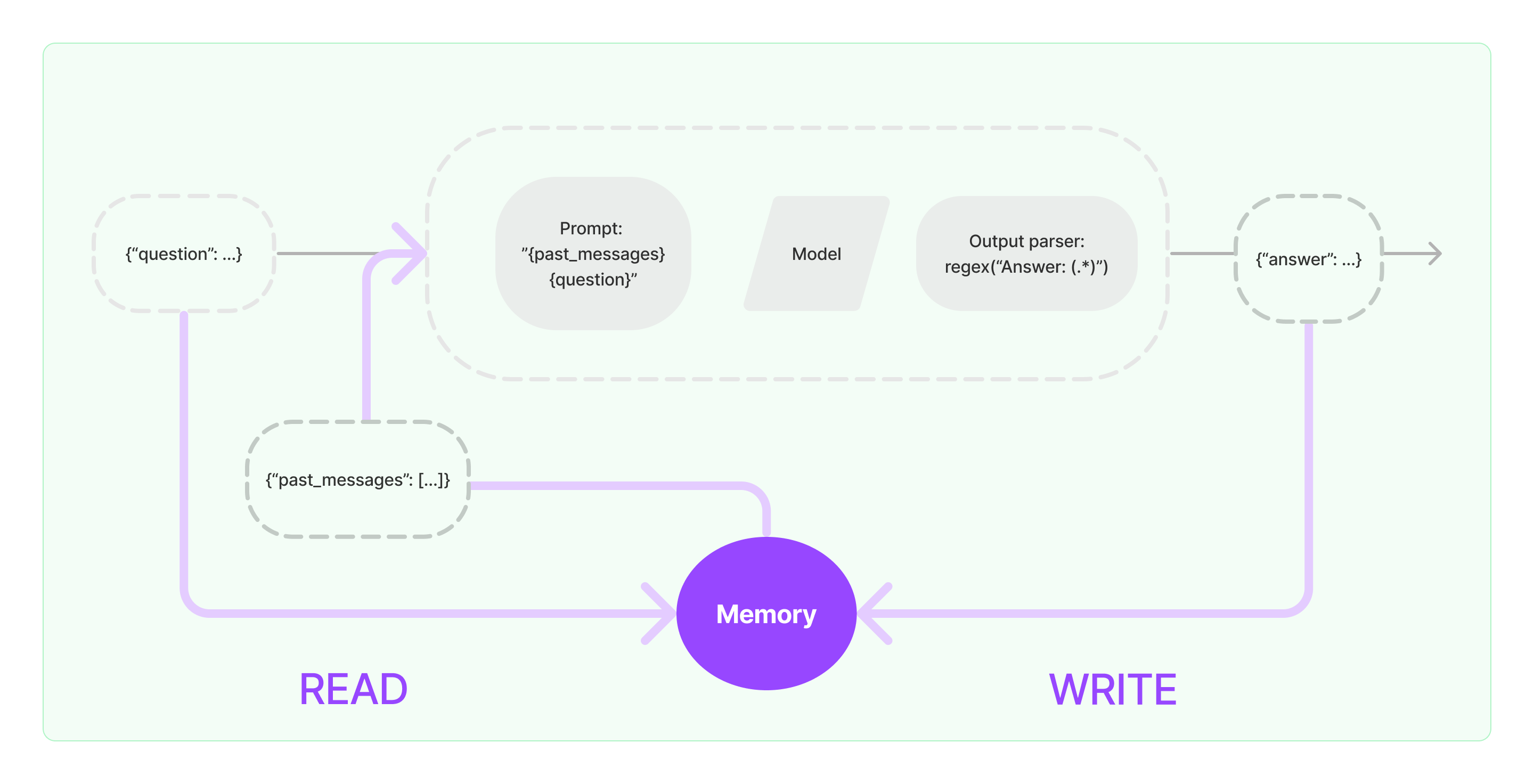
Integration von Speicher-Komponenten in das System
Bevor Sie Speicher-Komponenten verwenden, müssen Sie die folgenden beiden Fragen berücksichtigen:
- Wie historische Nachrichtendaten gespeichert werden
- Wie historische Nachrichtendaten abgerufen werden
Speicherung: Chat-Nachrichtenliste
Wenn das Chat-Modell verwendet wird, handelt es sich bei den Konversationsdaten um eine Liste von Chat-Nachrichten. LangChain unterstützt verschiedene Speichermotoren für die Speicherung historischer Nachrichtendaten, wobei die einfachste Methode darin besteht, sie im Arbeitsspeicher zu speichern. In der Praxis wird jedoch am häufigsten eine Speicherung in einer Datenbank verwendet.
Abruf: Abrufen relevanter historischer Konversationsnachrichten
Um die Speicherfähigkeit von LLM zu implementieren, wird der Kern darin bestehen, den Inhalt der historischen Nachrichten als Hintergrundinformationen in Veranlassungen zusammenzufügen. Auf diese Weise kann LLM auf die Hintergrundinformationen bei der Beantwortung von Fragen zurückgreifen.
Die Speicherung historischer Nachrichtendaten ist relativ einfach, und ein anspruchsvollerer Aspekt besteht darin, wie relevante historische Nachrichten zur aktuellen Konversationsinhalten abgerufen werden können. Der Hauptgrund für die Notwendigkeit des Abrufs relevanter historischer Nachrichten in Bezug auf den aktuellen Dialog ergibt sich aus dem maximalen Tokenlimit von LLM; wir können nicht alle historischen Konversationsinhalte in Veranlassungen füllen, die dem KI zugeführt werden.
Gängige Strategien zum Abfragen historischer Nachrichten umfassen:
- Nur die letzten N Nachrichten als Hintergrundinformationen für Veranlassungen abfragen
- Die Verwendung von KI zur Zusammenfassung historischer Nachrichten, wobei die Zusammenfassung als Hintergrundinformation für Veranlassungen dient
- Die Nutzung einer Vektordatenbank, um historische Nachrichten abzufragen, die ähnlich der aktuellen Konversation als Hintergrundinformationen für Veranlassungen dienen
Beispiel für die Verwendung der LangChain-Komponente
Werfen wir einen Blick darauf, wie die Speicher-Komponente in LangChain aussieht. Hier werden wir das grundlegende Wissen zur Interaktion mit der Speicher-Komponente vorstellen.
Zunächst sehen wir, wie man den ConversationBufferMemory im Aufgabenmuster verwendet. Der ConversationBufferMemory ist eine sehr einfache Speicher-Komponente, die nur eine Liste von Chat-Nachrichten im Speicher speichern und an eine neue Konversationsveranlassungsvorlage übergeben kann.
from langchain.memory import ConversationBufferMemory
speicher = ConversationBufferMemory()
speicher.chat_memory.add_user_message("Hallo!")
speicher.chat_memory.add_ai_message("Was geht ab?")
- Hinweis: LangChain bietet verschiedene Speicher-Komponenten mit ähnlicher Verwendung.
Als nächstes sehen wir, wie die Speicher-Komponente in der Kette verwendet wird. Im Folgenden zeigen wir, wie die LLM und das ChatModel, zwei gekapselte Modelle in LangChain, die Speicher-Komponente verwenden.
Beispiel für die Verwendung von LLM mit der Speicher-Komponente
from langchain_openai import OpenAI
from langchain_core.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = OpenAI(temperature=0)
vorlage = """Du bist ein großartiger Chatbot, der mit einem Menschen konversiert.
Vorheriges Gespräch:
{chat_history}
Neue Frage: {question}
Antwort des KI:"""
veranlassung = PromptTemplate.from_template(vorlage)
speicher = ConversationBufferMemory(memory_key="chat_history")
konversation = LLMChain(
llm=llm,
veranlassung=veranlassung,
ausführlich=True,
speicher=speicher
)
konversation({"question": "Hallo"})
from langchain_openai import ChatOpenAI
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = ChatOpenAI()
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"Du bist ein netter Chatbot und führst ein Gespräch mit einem Menschen."
),
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
conversation({"question": "hallo"})