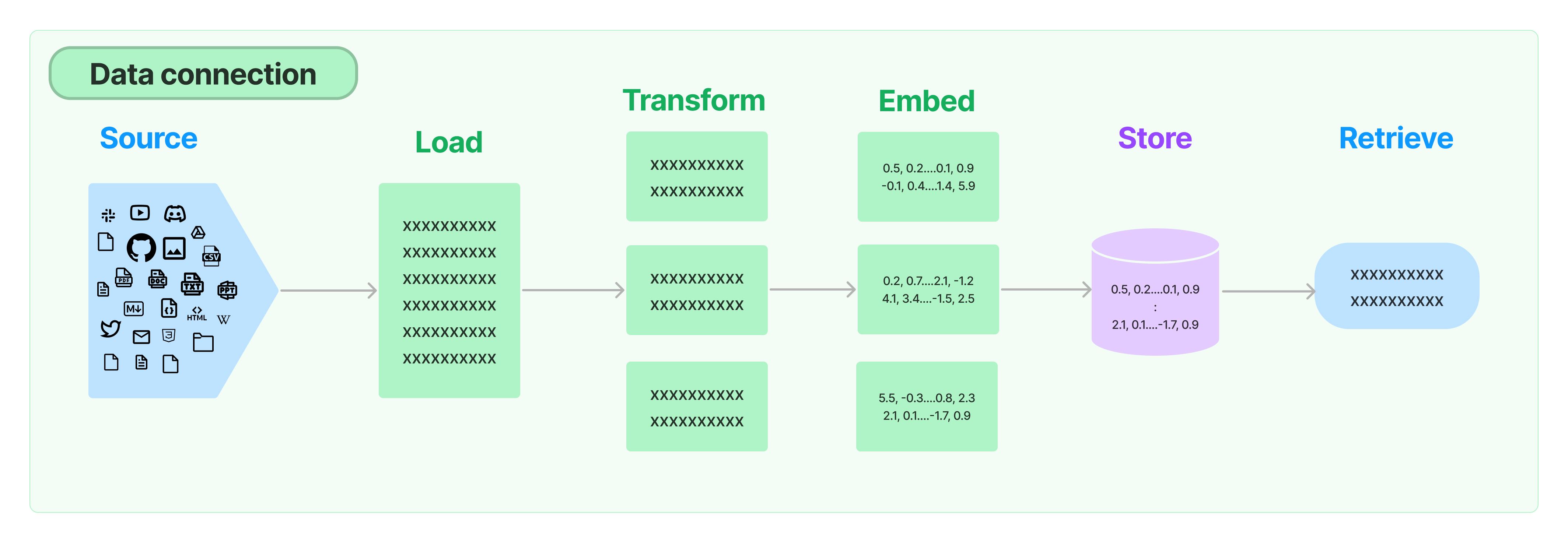
Obwohl das Language Model (LM) viel Wissen besitzt, kennt es dennoch keine Unternehmens-Interna und neue Daten. Viele LM-Anwendungen müssen auf Unternehmens-Interna zugreifen, dann diese privaten Daten als Hintergrundinformationen an die Anfrage anhängen und sie dem großen Modell zur Beantwortung von Fragen auf Basis dieser Hintergrundinformationen bereitstellen. LangChain bietet Framework-Komponenten zum Laden, Transformieren, Speichern und Abfragen von Daten an.
Die Komponenten von LangChain zur Bearbeitung von privaten Daten umfassen:
- Dokumenten-Lader: Unterstützt das Laden von Dokumentendaten aus verschiedenen Quellen.
- Dokumenten-Konverter: Teilt Dokumente auf, wandelt sie in das Frage-Antwort-Format um und entfernt überflüssige Dokumente.
- Text-Einbettungsmodell: Wandelt unstrukturierten Text in Merkmalsvektoren um, um semantische Ähnlichkeitssuche zu unterstützen, wie beim Abfragen von Inhalten, die ähnlich der gestellten Frage sind.
- Vektor-Speicher: Speichert und durchsucht Vektordaten.
- Retriever: LangChain's encapsulated utility class for conveniently querying your data.