
Векторная база данных - относительно новый способ взаимодействия с абстрактными представлениями данных, которые поступают из непрозрачных моделей машинного обучения, таких как глубинные структуры обучения. Эти представления, обычно называемые векторами или векторами вложения, представляют собой сжатые версии данных, используемых для обучения моделей машинного обучения для выполнения задач, таких как анализ настроений, распознавание речи и обнаружение объектов.
Эти новые базы данных показали выдающиеся результаты во многих приложениях, таких как семантический поиск и системы рекомендаций.
Что такое Qdrant?
Qdrant - это открытая векторная база данных, разработанная для приложений искусственного интеллекта следующего поколения. Она облачно-ориентированная и предоставляет RESTful и gRPC API для управления вложениями. Qdrant гордится мощными функциями, поддерживая поиск изображений, голоса и видео, а также интеграцию с искусственными интеллектными двигателями.
Что такое векторная база данных?
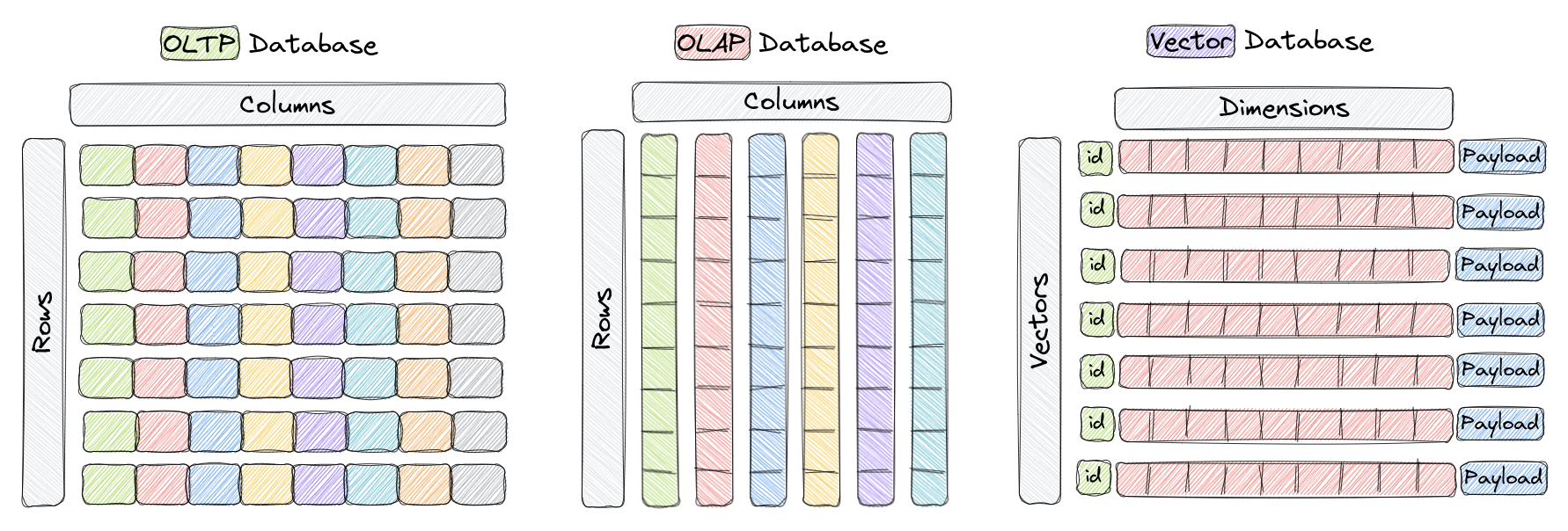
Векторная база данных - это тип базы данных, специально предназначенный для эффективного хранения и запросов высокоразмерных векторов. В традиционных OLTP и OLAP базах данных (как показано на рисунке выше), данные организованы в строках и столбцах (называемых таблицами), и запросы основаны на значениях в этих столбцах. Однако в определенных приложениях, таких как распознавание изображений, обработка естественного языка и системы рекомендаций, данные часто представлены в виде векторов в высокоразмерном пространстве. Эти векторы вместе с идентификатором и полезной нагрузкой составляют элементы, хранящиеся в векторных базах данных, таких как Qdrant.
В этом контексте вектор - это математическое представление объекта или точки данных, где каждый элемент вектора соответствует характеристике или атрибуту объекта. Например, в системе распознавания изображений вектор может представлять изображение, причем каждый элемент вектора представляет значения пикселей или характеристику/дескриптор пикселя. В системе рекомендаций музыки каждый вектор представляет песню, причем каждый элемент вектора представляет характеристику песни, такую как ритм, жанр, текст и т. д.
Векторные базы данных оптимизированы для эффективного хранения и запросов высокоразмерных векторов, часто используя специализированные структуры данных и техники индексации, такие как иерархическое навигационное малое миро (HNSW) для приближенного поиска ближайших соседей и квантование продукции. Эти базы данных позволяют пользователям находить ближайшие векторы к данному запросу в соответствии с определенной метрикой расстояния, обеспечивая быстрый поиск похожих и семантических значений. Самые часто используемые метрики расстояния включают в себя косинусное сходство, скалярное произведение и евклидово расстояние, все полностью поддерживаемые в Qdrant.
Вот краткое введение в эти три алгоритма сходства векторов:
- Косинусное сходство - Косинусное сходство - это мера сходства между двумя элементами. Это можно рассматривать как линейку, используемую для измерения расстояния между двумя точками; однако вместо измерения расстояния она измеряет сходство между двумя элементами. Обычно оно используется для сравнения сходства между двумя документами или предложениями в тексте. Диапазон вывода косинусного сходства составляет от 0 до 1, где 0 указывает на полное несходство, а 1 указывает на полное сходство. Это простой и эффективный способ сравнения двух элементов!
- Скалярное произведение - Скалярное произведение - это другая мера сходства между двумя элементами, аналогичная косинусному сходству. При работе с числами оно часто используется в машинном обучении и науке о данных. Скалярное произведение сходства вычисляется путем умножения значений в двух наборах чисел и затем сложения этих произведений. Большая сумма указывает на более высокое сходство между двумя наборами чисел. Это похоже на шкалу, измеряющую степень совпадения между двумя наборами чисел.
- Евклидово расстояние - Евклидово расстояние - это способ измерения расстояния между двумя точками в пространстве, аналогичный тому, как мы измеряем расстояние между двумя местами на карте. Оно вычисляется путем нахождения квадратного корня из суммы квадратов разностей координат двух точек. Этот метод измерения расстояния часто используется в машинном обучении для оценки сходства или несходства двух точек данных, другими словами, для понимания, насколько они далеко друг от друга.
Теперь, когда мы знаем, что такое векторные базы данных и в чем их структурные отличия от других баз данных, давайте поймем, почему они важны.
Зачем нам нужна векторная база данных?
Векторные базы данных играют ключевую роль в различных приложениях, требующих поиска похожих элементов, таких как системы рекомендаций, поиск контента на основе изображений и персонализированный поиск. За счет эффективных методов индексации и поиска векторные базы данных могут быстрее и точнее извлекать неструктурированные данные, представленные в виде векторов, предоставляя наиболее релевантные результаты для запросов пользователей.
Кроме того, другие преимущества использования векторной базы данных включают:
- Эффективное хранение и индексирование высокоразмерных данных.
- Возможность работы с масштабными наборами данных, включающими миллиарды точек.
- Поддержка анализа и запросов в реальном времени.
- Способность обрабатывать векторы, полученные из сложных типов данных, таких как изображения, видео и тексты естественных языков.
- Улучшение производительности приложений машинного обучения и искусственного интеллекта при снижении задержек.
- Сокращение времени и затрат на разработку и внедрение по сравнению с созданием пользовательских решений.
Обратите внимание, что конкретные преимущества использования векторной базы данных могут изменяться в зависимости от использования вашей организацией и выбранных функциональностей базы данных.
Теперь давайте сделаем общую оценку архитектуры Qdrant.
Общий обзор архитектуры Qdrant
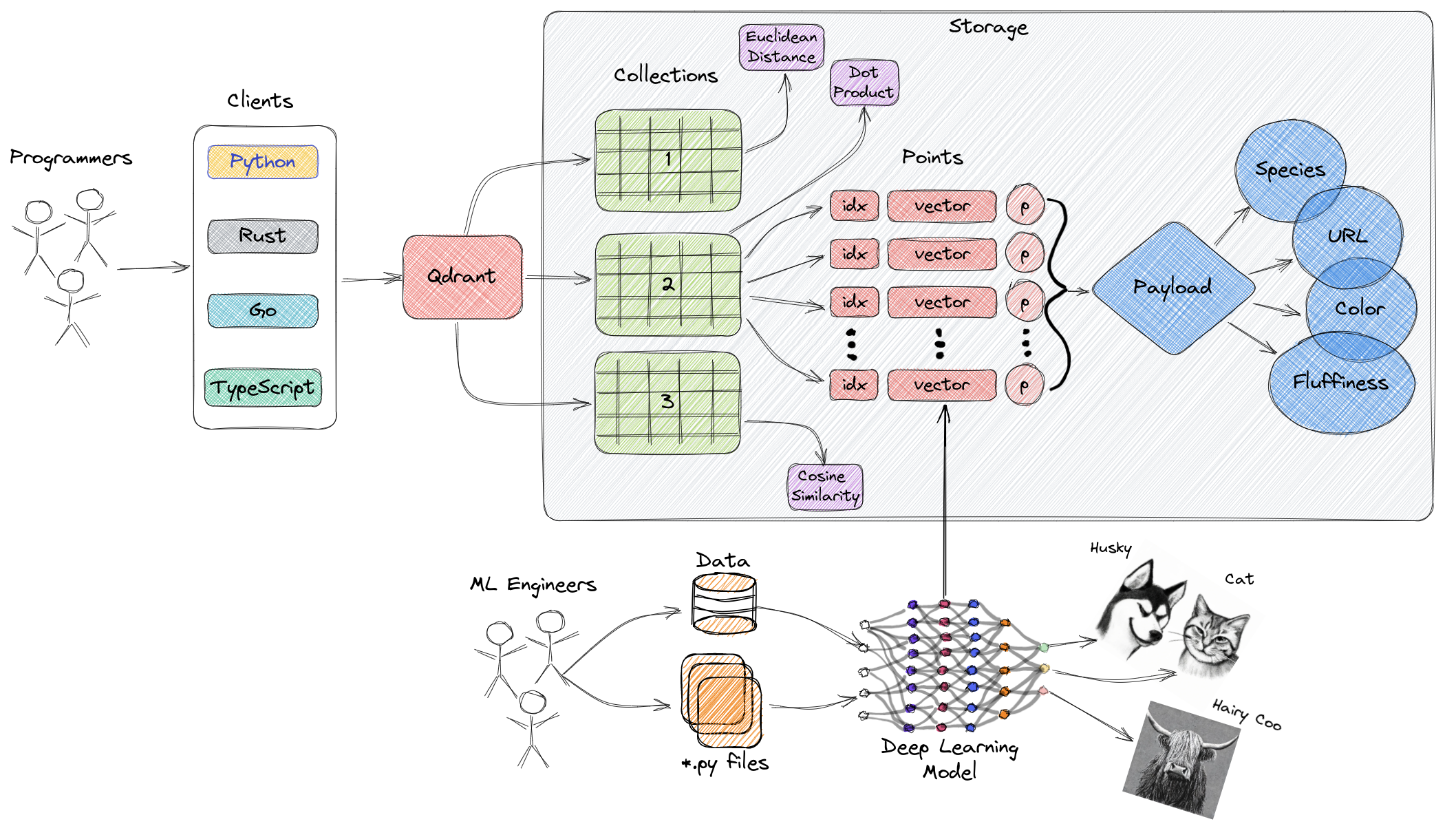
Выше приведена общая диаграмма основных компонентов Qdrant. Следующие ключевые термины относятся к Qdrant:
- Коллекции: Коллекции представляют собой группы именованных точек (векторов с полезной нагрузкой - фактически векторных данных). Проще говоря, коллекции аналогичны таблицам в MySQL, а точки подобны строкам данных в этих таблицах. Поиск может быть выполнен среди этих точек. Каждый вектор в одной и той же коллекции должен иметь одинаковое измерение и сравниваться с использованием одной и той же метрики. Именованные векторы могут использоваться для наличия нескольких векторов в одной точке, каждый из которых имеет свое собственное измерение и требования к метрике.
- Метрика: Мера, используемая для количественной оценки сходства между векторами, которую необходимо выбрать при создании коллекции. Выбор метрики зависит от способа получения вектора, особенно для нейронных сетей, используемых для кодирования новых запросов (метрика - это выбранный нами алгоритм сходства).
- Точки: Точки - это основные сущности, с которыми работает Qdrant, состоящие из векторов, опциональных идентификаторов и полезной нагрузки (подобно строкам данных в таблице MySQL).
- ID: Уникальный идентификатор вектора.
- Вектор: Высокоразмерное представление данных, таких как изображения, звуки, документы, видео и т. д.
- Полезная нагрузка: JSON-объект, который можно добавить к вектору в качестве дополнительных данных (преимущественно используется для хранения бизнес-свойств, связанных с вектором).
- Хранилище: Qdrant может использовать два варианта хранения: в памяти (все векторы хранятся в памяти, обеспечивая максимальную скорость, поскольку доступ к диску используется только для сохранения) и Memmap (создание виртуального адресного пространства, связанного с файлами на диске).
- Клиенты: Вы можете подключаться к Qdrant с помощью SDK на различных языках программирования или взаимодействовать с Qdrant непосредственно, используя его REST API.