Память LLM
Большинство приложений на основе LLM имеют интерфейс чата, аналогичный WeChat. Важной функцией процесса диалога с ИИ является возможность ссылаться на предыдущую информацию в разговоре, как это делает человек в диалоге, не нужно повторять предыдущее содержание. Люди автоматически вспоминают историческую информацию.
Способность хранить историческую информацию о разговоре в поле LLM обычно называется "Память", как у людей есть способность запоминать. LangChain инкапсулирует различные компоненты памяти, которые могут использоваться отдельно или интегрироваться в цепочку без перерыва.
Компоненты памяти должны реализовать две основные операции: чтение и запись.
Для различных компонентов цепочки LangChain, если вы включаете функцию Памяти, то будет выполняться следующая логика:
- При получении начального ввода пользователя компонент цепочки будет пытаться запросить соответствующую историческую информацию из компонента памяти, затем объединять историческую информацию и ввод пользователя в подсказки, которые передаются в LLM.
- При получении возвращенного содержимого из LLM, оно автоматически сохранится в компоненте памяти для удобного запроса в следующий раз.
Процесс реализации возможности памяти в LangChain показан на диаграмме ниже:
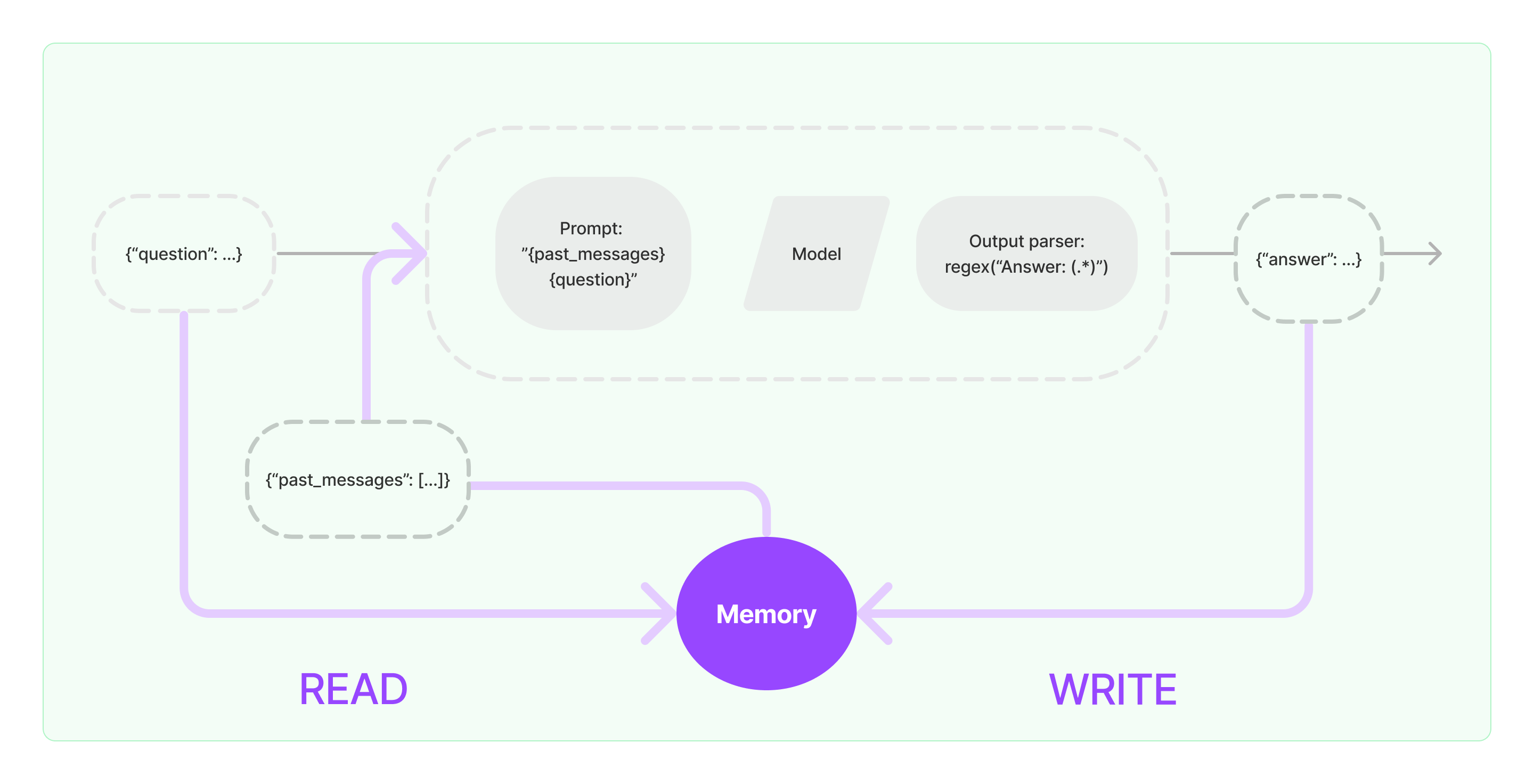
Интеграция компонентов памяти в систему
Перед использованием компонентов памяти необходимо рассмотреть следующие два вопроса:
- Как хранить исторические данные сообщений
- Как запросить исторические данные сообщений
Хранение: Список сообщений чата
Если использовать модель чата, то данные разговора представляют собой список сообщений чата. LangChain поддерживает различные хранилища для хранения исторических данных сообщений, простейшим из которых является хранение в памяти. На практике наиболее часто используемым методом является хранение их в базе данных.
Запрос: Как запрашивать соответствующие исторические сообщения разговора
Для реализации возможности памяти в LLM главное - объединить содержание исторических сообщений в предварительную информацию для подсказок. Таким образом, LLM может ссылаться на предварительную информацию при ответе на вопросы.
Хранение исторических сообщений относительно просто, более сложная задача заключается в том, как запросить исторические сообщения, относящиеся к текущему содержанию разговора. Основная причина необходимости запроса исторических сообщений, относящихся к текущему разговору, заключается в максимальном лимите токенов LLM; мы не можем загрузить все исторические сообщения в подсказки для передачи в ИИ.
Распространенные стратегии запроса исторических сообщений включают:
- Запрос только самых недавних N сообщений в качестве предварительной информации для подсказок
- Использование ИИ для резюмирования исторических сообщений, где резюме служит в качестве предварительной информации для подсказок
- Использование векторной базы данных для запроса исторических сообщений, схожих с текущим разговором, в качестве предварительной информации для подсказок
Пример использования компонента LangChain
Давайте посмотрим, как выглядит компонент Памяти в LangChain. Здесь мы расскажем основные аспекты взаимодействия с компонентом Памяти.
Сначала посмотрим, как использовать ConversationBufferMemory в цепочке задач. ConversationBufferMemory - это очень простой компонент памяти, который может только хранить список чат-сообщений в памяти и передавать их в новый шаблон разговорной подсказки.
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
memory.chat_memory.add_user_message("привет!")
memory.chat_memory.add_ai_message("как дела?")
- Примечание: LangChain предоставляет различные компоненты памяти с аналогичным использованием.
Далее посмотрим, как использовать компонент Памяти в цепочке. Ниже мы расскажем, как LLM и ChatModel, две инкапсулированные модели в LangChain, используют компонент Памяти.
Пример использования LLM с компонентом Памяти
from langchain_openai import OpenAI
from langchain_core.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = OpenAI(temperature=0)
template = """Вы отличный чатбот, общающийся с человеком.
Предыдущий разговор:
{chat_history}
Новый вопрос: {question}
Ответ ИИ:"""
prompt = PromptTemplate.from_template(template)
memory = ConversationBufferMemory(memory_key="chat_history")
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
conversation({"question": "привет"})
from langchain_openai import ChatOpenAI
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = ChatOpenAI()
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"Ты классный чатбот, ведущий разговор с человеком."
),
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
conversation({"question": "привет"})