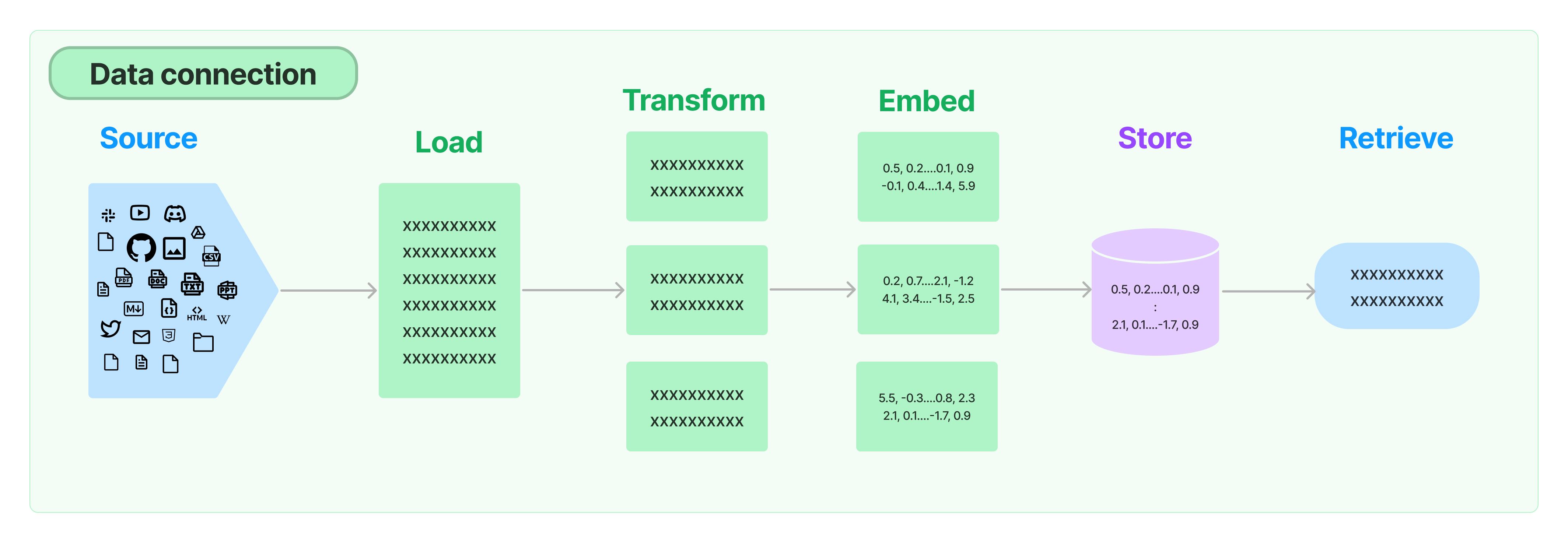
Bien que le modèle linguistique (LM) formé possède beaucoup d'informations, il ne connaît toujours pas les données privées de l'entreprise et les nouvelles données. De nombreuses applications LM nécessitent d'interroger les données privées de l'entreprise, puis de concaténer ces données privées en tant qu'informations de contexte dans la requête, et de les transmettre au grand modèle pour répondre aux questions en se basant sur ces informations de contexte. LangChain fournit des composants de framework pour charger, transformer, stocker et interroger les données.
Les composants de LangChain pour gérer les données privées comprennent :
- Chargeur de document : prend en charge le chargement de données documentaires à partir de différentes sources.
- Convertisseur de document : divise les documents, convertit les documents au format Q&R et supprime les documents redondants.
- Modèle d'encodage de texte : convertit un texte non structuré en vecteurs de caractéristiques pour prendre en charge une recherche sémantique de similarité, telle que la recherche de contenu similaire à la question posée.
- Stockage de vecteurs : stocke et recherche des données vectorielles.
- Récupérateur : classe utilitaire encapsulée de LangChain pour interroger commodément vos données.