
Une base de données vectorielle est une manière relativement nouvelle d'interagir avec des représentations de données abstraites, qui proviennent de modèles d'apprentissage automatique opaques tels que les structures d'apprentissage profond. Ces représentations sont couramment appelées vecteurs ou vecteurs d'encastrement, et ce sont des versions compressées des données utilisées pour former des modèles d'apprentissage automatique à effectuer des tâches telles que l'analyse de sentiment, la reconnaissance vocale et la détection d'objets.
Ces nouvelles bases de données ont montré des performances exceptionnelles dans de nombreuses applications, telles que la recherche sémantique et les systèmes de recommandation.
Qu'est-ce que Qdrant?
Qdrant est une base de données vectorielle open source conçue pour les applications d'intelligence artificielle de nouvelle génération. Elle est native dans le cloud et propose des API RESTful et gRPC pour gérer les plongements. Qdrant offre des fonctionnalités puissantes, prenant en charge la recherche d'images, de voix et de vidéos, ainsi que l'intégration avec des moteurs d'intelligence artificielle.
Qu'est-ce qu'une base de données vectorielle?
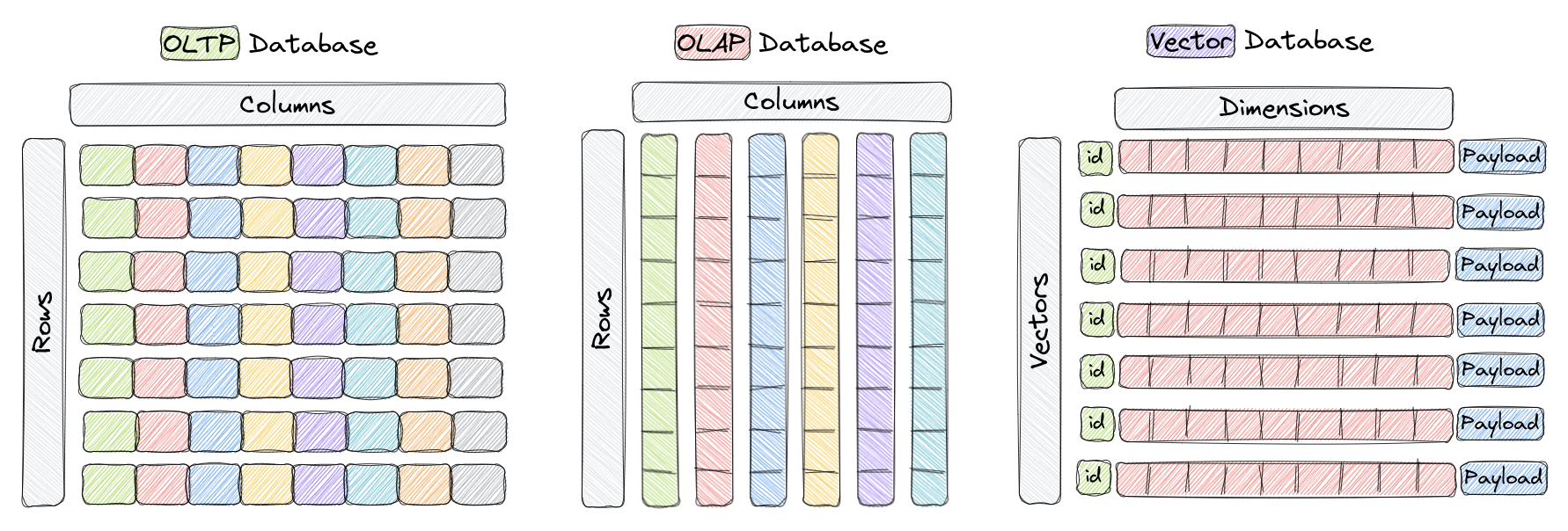
Une base de données vectorielle est un type de base de données spécifiquement conçu pour le stockage efficace et l'interrogation de vecteurs de grande dimension. Dans les bases de données OLTP et OLAP traditionnelles (comme indiqué dans la figure ci-dessus), les données sont organisées en lignes et colonnes (appelées tables), et les requêtes sont basées sur les valeurs de ces colonnes. Cependant, dans certaines applications telles que la reconnaissance d'images, le traitement du langage naturel et les systèmes de recommandation, les données sont souvent représentées sous forme de vecteurs dans un espace de grande dimension. Ces vecteurs, avec un ID et une charge utile, constituent les éléments stockés dans les bases de données vectorielles telles que Qdrant.
Dans ce contexte, un vecteur est la représentation mathématique d'un objet ou d'un point de données, où chaque élément du vecteur correspond à une caractéristique ou un attribut de l'objet. Par exemple, dans un système de reconnaissance d'images, un vecteur peut représenter une image, chaque élément du vecteur représentant les valeurs des pixels ou la caractéristique/descripteur du pixel. Dans un système de recommandation musicale, chaque vecteur représente une chanson, chaque élément du vecteur représentant une caractéristique de la chanson, telle que le rythme, le genre, les paroles, etc.
Les bases de données vectorielles sont optimisées pour le stockage efficace et l'interrogation de vecteurs de grande dimension, utilisant souvent des structures de données spécialisées et des techniques d'indexation telles que le "Hierarchical Navigable Small World" (HNSW) pour la recherche approximative des plus proches voisins et la quantification de produits. Ces bases de données permettent aux utilisateurs de trouver les vecteurs les plus proches d'un vecteur de requête donné selon une certaine distance métrique, permettant une recherche de similarité rapide et sémantique. Les métriques de distance les plus couramment utilisées incluent la distance euclidienne, la similarité cosinus et le produit scalaire, tous pleinement pris en charge dans Qdrant.
Voici une brève introduction à ces trois algorithmes de similarité vectorielle:
- Similarité Cosinus - La similarité cosinus est une mesure de similarité entre deux éléments. On peut la voir comme une règle utilisée pour mesurer la distance entre deux points ; cependant, au lieu de mesurer la distance, elle mesure la similarité entre deux éléments. Elle est couramment utilisée pour comparer la similarité entre deux documents ou phrases dans un texte. La plage de sortie de la similarité cosinus va de 0 à 1, où 0 indique une dissimilarité complète et 1 indique une similarité complète. C'est un moyen simple et efficace de comparer deux éléments!
- Produit Scalaire - La similarité par produit scalaire est une autre mesure de similarité entre deux éléments, similaire à la similarité cosinus. Dans le domaine des nombres, elle est souvent utilisée en apprentissage automatique et en science des données. La similarité par produit scalaire est calculée en multipliant les valeurs de deux ensembles de nombres, puis en additionnant ces produits. Une somme plus élevée indique une plus grande similarité entre les deux ensembles de nombres. C'est comme une échelle qui mesure le degré de correspondance entre deux ensembles de nombres.
- Distance Euclidienne - La distance euclidienne est une manière de mesurer la distance entre deux points dans l'espace, similaire à la manière dont nous mesurons la distance entre deux endroits sur une carte. Elle est calculée en trouvant la racine carrée de la somme des carrés des différences entre les coordonnées des deux points. Cette méthode de mesure de la distance est couramment utilisée en apprentissage automatique pour évaluer la similarité ou la dissimilarité de deux points de données, en d'autres termes, pour comprendre à quelle distance ils se trouvent l'un de l'autre.
Maintenant que nous savons ce que sont les bases de données vectorielles et en quoi elles diffèrent structurellement des autres bases de données, voyons pourquoi elles sont importantes.
Pourquoi avons-nous besoin d'une base de données vectorielle?
Les bases de données vectorielles jouent un rôle crucial dans diverses applications nécessitant une recherche de similarité, telles que les systèmes de recommandation, la recherche d'images basée sur le contenu et la recherche personnalisée. En exploitant des techniques efficaces d'indexation et de recherche, les bases de données vectorielles peuvent récupérer des données non structurées représentées sous forme de vecteurs plus rapidement et plus précisément, présentant les résultats les plus pertinents à la requête de l'utilisateur.
De plus, les autres avantages de l'utilisation d'une base de données vectorielle comprennent:
- Stockage et indexation efficaces de données de grande dimension.
- Capacité à gérer des ensembles de données à grande échelle avec des milliards de points de données.
- Prise en charge de l'analyse et des requêtes en temps réel.
- Capacité à manipuler des vecteurs dérivés de types de données complexes tels que des images, des vidéos et des textes en langage naturel.
- Amélioration des performances des applications d'apprentissage automatique et d'intelligence artificielle tout en réduisant la latence.
- Réduction du temps et des coûts de développement et de déploiement par rapport à la construction de solutions personnalisées.
Veuillez noter que les avantages spécifiques de l'utilisation d'une base de données vectorielle peuvent varier selon les cas d'utilisation de votre organisation et les fonctionnalités de base de données choisies.
Maintenant, faisons une évaluation globale de l'architecture de Qdrant.
Aperçu général de l'architecture de Qdrant
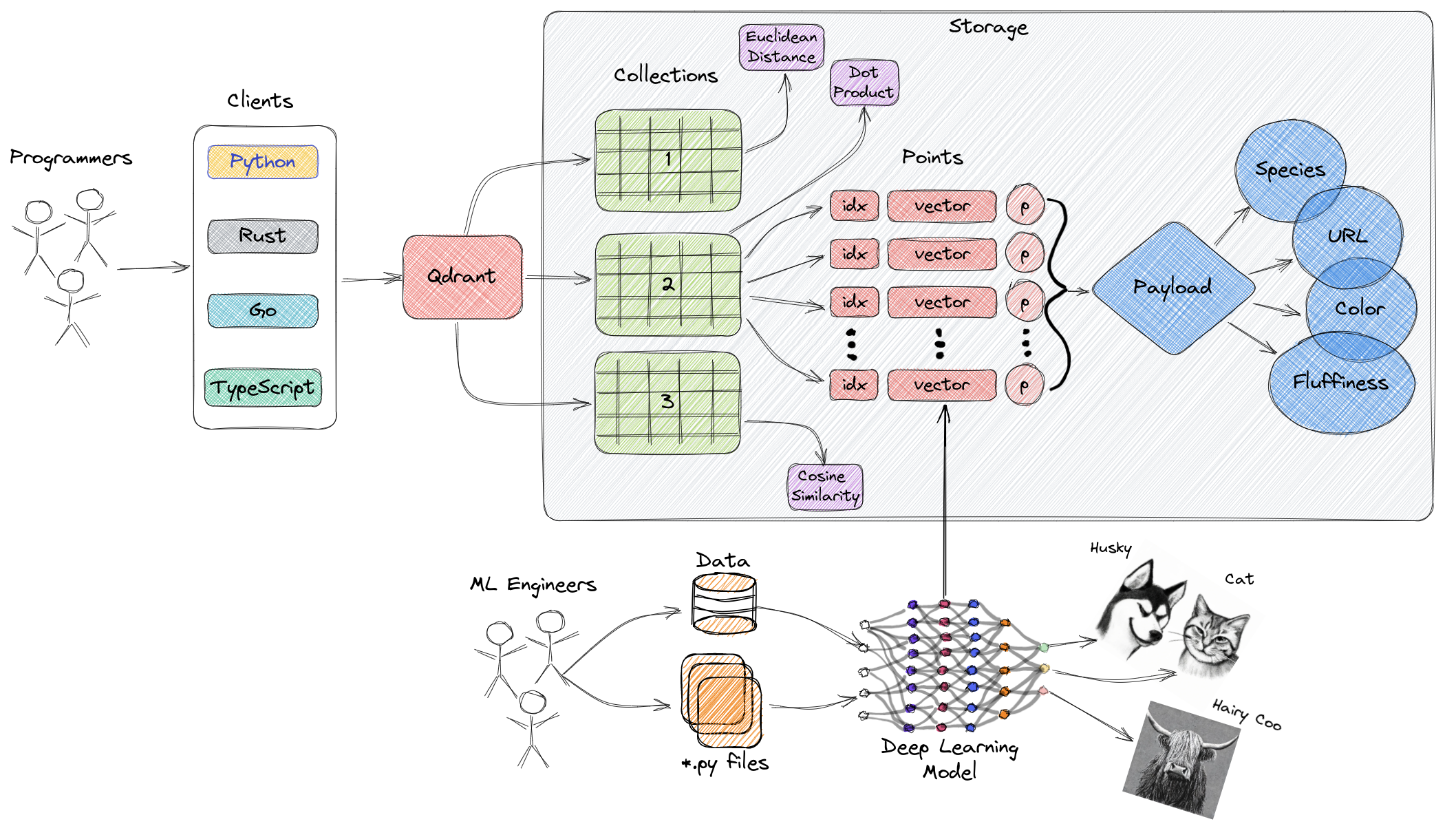
Le diagramme ci-dessus offre un aperçu global des principaux composants de Qdrant. Les termes clés liés à Qdrant sont les suivants:
- Collections: Les collections sont un groupe de points nommés (vecteurs avec des charges utiles, essentiellement des données vectorielles). En termes plus simples, les collections sont similaires aux tables dans MySQL, et les points sont similaires aux lignes de données au sein de ces tables. La recherche peut être effectuée parmi ces points. Chaque vecteur au sein de la même collection doit avoir la même dimension et être comparé en utilisant une seule métrique. Les vecteurs nommés peuvent être utilisés pour avoir plusieurs vecteurs dans un seul point, chacun avec ses propres exigences de dimension et de métrique.
- Métrique: Une mesure utilisée pour quantifier la similarité entre les vecteurs, qui doit être sélectionnée lors de la création d'une collection. Le choix de la métrique dépend de la méthode d'acquisition de vecteurs, en particulier pour les réseaux neuronaux utilisés pour encoder de nouvelles requêtes (la métrique est l'algorithme de similarité que nous choisissons).
- Points: Les points sont les entités principales sur lesquelles opère Qdrant, composés de vecteurs, d'identifiants facultatifs et de charges utiles (semblables aux lignes de données dans une table MySQL).
- Identifiant: Identifiant unique du vecteur.
- Vecteur: Représentation en haute dimension des données, telles que des images, audio, documents, vidéos, etc.
- Charge utile: Un objet JSON pouvant être ajouté au vecteur en tant que données supplémentaires (principalement utilisé pour stocker les propriétés commerciales associées au vecteur).
- Stockage: Qdrant peut utiliser deux options de stockage - le stockage en mémoire (tous les vecteurs sont stockés en mémoire, offrant la vitesse la plus élevée, car l'accès au disque n'est utilisé que pour la persistance) et le stockage Memmap (création d'un espace d'adressage virtuel associé à des fichiers sur le disque).
- Clients: Vous pouvez vous connecter à Qdrant en utilisant des kits de développement logiciel de langage de programmation ou interagir directement avec Qdrant en utilisant son API REST.