Mémoire LLM
La plupart des applications basées sur LLM ont une interface de chat similaire à WeChat. Une fonction importante du processus de dialogue AI est la capacité à faire référence à des informations précédemment mentionnées dans la conversation, tout comme le processus de dialogue humain, sans avoir besoin de répéter le contenu précédent. Les humains rappellent automatiquement les informations historiques.
La capacité à stocker des informations de conversation historiques dans le domaine LLM est généralement appelée "Mémoire", tout comme les humains ont la capacité de se souvenir. LangChain encapsule divers composants de fonction mémoire, qui peuvent être utilisés séparément ou intégrés de manière transparente dans une chaîne.
Les composants mémoire doivent mettre en œuvre deux opérations de base : lecture et écriture.
Pour divers composants de tâches en chaîne de LangChain, si vous activez la fonction Mémoire, il exécutera une logique similaire comme suit :
- Lors de la réception de l'entrée initiale de l'utilisateur, la tâche de chaîne tentera de interroger des informations historiques pertinentes à partir du composant mémoire, puis concaténera les informations historiques et l'entrée de l'utilisateur en prompts à passer à LLM.
- Lors de la réception du contenu renvoyé par LLM, il stockera automatiquement le résultat dans le composant mémoire pour faciliter la consultation la prochaine fois.
Le processus de mise en œuvre de la capacité mémoire dans LangChain est illustré dans le diagramme ci-dessous:
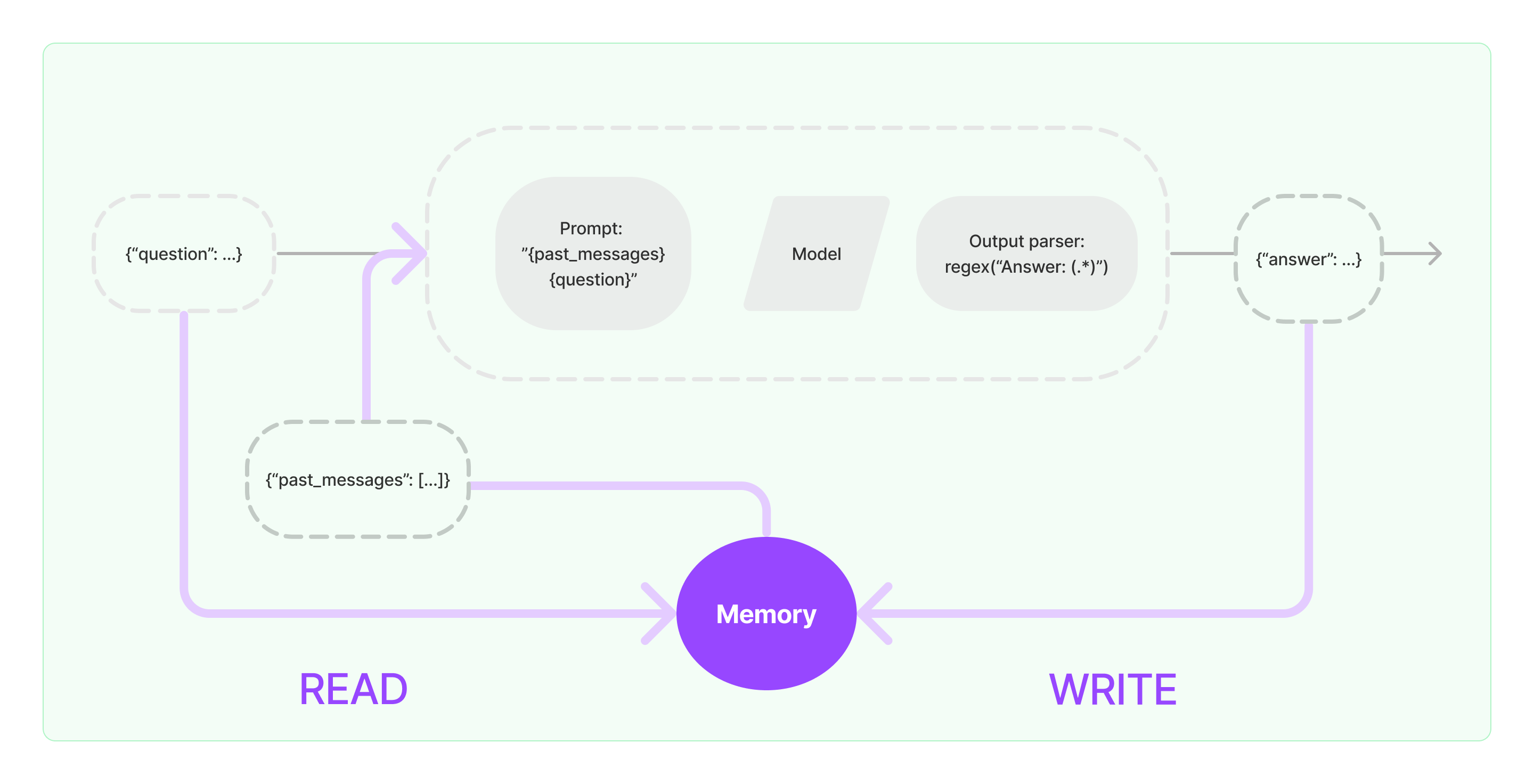
Intégration des composants mémoire dans le système
Avant d'utiliser des composants mémoire, vous devez considérer les deux questions suivantes :
- Comment stocker les données de message historique
- Comment interroger les données de message historique
Stockage : Liste des messages de chat
Si vous utilisez le modèle de chat, les données de conversation sont une liste de messages de chat. LangChain prend en charge divers moteurs de stockage pour stocker les données de message historique, le plus simple étant de les stocker en mémoire. En pratique, la méthode la plus couramment utilisée est de les stocker dans une base de données.
Interrogation : Comment interroger les messages de conversation historiques pertinents
Pour mettre en œuvre la capacité mémoire de LLM, l'essentiel est de concaténer le contenu du message historique en tant qu'informations de fond dans les prompts. De cette façon, LLM peut se référer aux informations de fond lors de la réponse aux questions.
Le stockage des données de message historique est relativement simple, et un aspect plus difficile est de savoir comment interroger les messages historiques pertinents par rapport au contenu de la conversation actuelle. La principale raison de la nécessité d'interroger les messages historiques liés au contenu de la conversation actuelle est due à la limite maximale de jetons de LLM; nous ne pouvons pas inclure tout le contenu de la conversation historique dans les prompts pour alimenter l'IA.
Les stratégies courantes d'interrogation des messages historiques comprennent :
- Interroger uniquement les N messages les plus récents comme informations de fond pour les prompts
- Utiliser l'IA pour résumer les messages historiques, le résumé servant d'informations de fond pour les prompts
- Exploiter une base de données vectorielle pour interroger les messages historiques similaires à la conversation actuelle comme informations de fond pour les prompts
Exemple d'utilisation du composant LangChain
Jetons un coup d'œil à quoi ressemble le composant Mémoire dans LangChain. Ici, nous allons présenter les connaissances de base pour interagir avec le composant Mémoire.
Tout d'abord, voyons comment utiliser le ConversationBufferMemory dans la chaîne de tâches. ConversationBufferMemory est un composant mémoire très simple qui ne peut stocker qu'une liste de messages de chat en mémoire et les transmettre à un nouveau modèle de prompt de conversation.
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
memory.chat_memory.add_user_message("salut!")
memory.chat_memory.add_ai_message("quoi de neuf?")
- Remarque : LangChain fournit divers composants de mémoire avec une utilisation similaire.
Ensuite, voyons comment utiliser le composant Mémoire dans la chaîne. Ci-dessous, nous présenterons comment les modèles LLM et ChatModel, deux modèles encapsulés dans LangChain, utilisent le composant Mémoire.
Exemple de l'utilisation du composant Mémoire par LLM
from langchain_openai import OpenAI
from langchain_core.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = OpenAI(temperature=0)
template = """Tu es un excellent chatbot en train de converser avec un humain.
Conversation précédente :
{chat_history}
Nouvelle question : {question}
Réponse de l'IA :"""
prompt = PromptTemplate.from_template(template)
memory = ConversationBufferMemory(memory_key="chat_history")
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
conversation({"question": "salut"})
de langchain_openai import ChatOpenAI
de langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
de langchain.chains import LLMChain
de langchain.memory import ConversationBufferMemory
llm = ChatOpenAI()
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"Tu es un gentil chatbot en train de converser avec un humain."
),
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)