
Un database vettoriale è un modo relativamente nuovo per interagire con rappresentazioni di dati astratti, che provengono da modelli di apprendimento automatico opachi come le strutture di deep learning. Queste rappresentazioni sono comunemente chiamate vettori o vettori di embedding, e sono versioni compressi dei dati utilizzati per addestrare modelli di machine learning per eseguire compiti come l'analisi del sentiment, il riconoscimento vocale e la rilevazione di oggetti.
Questi nuovi database hanno dimostrato prestazioni eccezionali in molte applicazioni, come la ricerca semantica e i sistemi di raccomandazione.
Cos'è Qdrant?
Qdrant è un database vettoriale open source progettato per le applicazioni di intelligenza artificiale di prossima generazione. È nativo del cloud e fornisce API RESTful e gRPC per la gestione degli embedding. Qdrant vanta potenti funzionalità, supportando la ricerca di immagini, voci e video, oltre all'integrazione con motori di intelligenza artificiale.
Cos'è un Database Vettoriale?
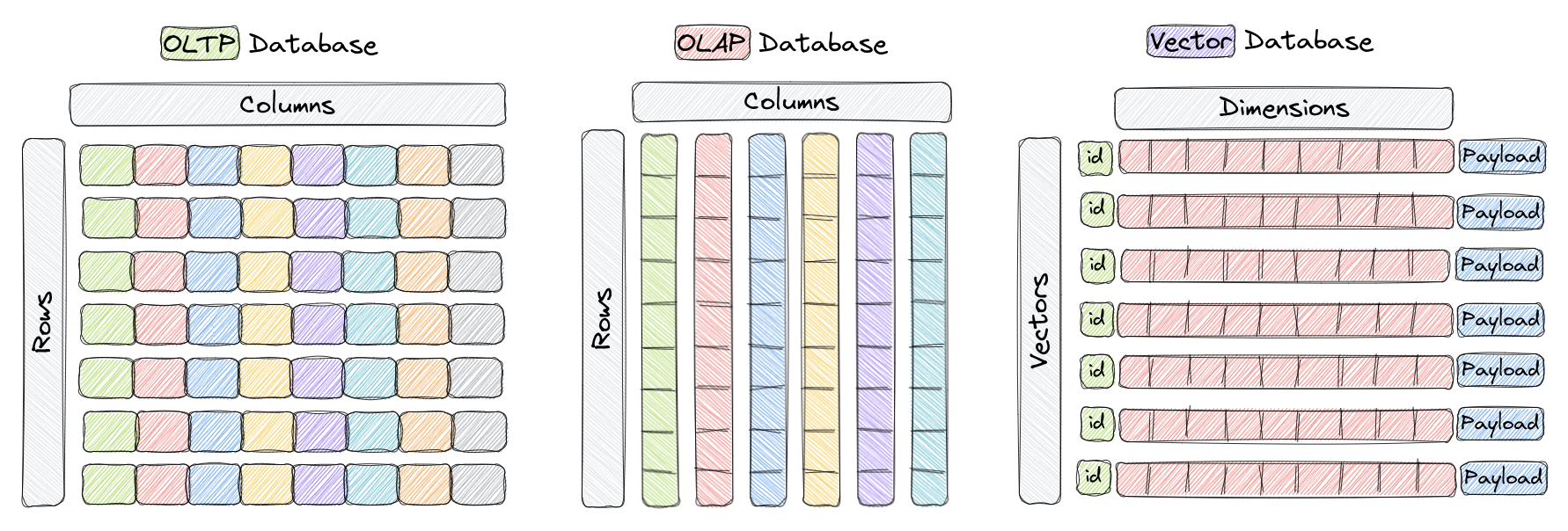
Un database vettoriale è un tipo di database progettato specificamente per l'archiviazione efficiente e il recupero di vettori ad alta dimensione. Nei tradizionali database OLTP e OLAP (come mostrato nella figura sopra), i dati sono organizzati in righe e colonne (chiamati tabelle), e le query si basano sui valori in queste colonne. Tuttavia, in certe applicazioni come il riconoscimento di immagini, l'elaborazione del linguaggio naturale e i sistemi di raccomandazione, i dati sono spesso rappresentati sotto forma di vettori in uno spazio ad alta dimensione. Questi vettori, insieme a un ID e un payload, costituiscono gli elementi archiviati nei database vettoriali come Qdrant.
In questo contesto, un vettore è la rappresentazione matematica di un oggetto o punto dati, dove ciascun elemento del vettore corrisponde a una caratteristica o attributo dell'oggetto. Ad esempio, in un sistema di riconoscimento delle immagini, un vettore può rappresentare un'immagine, con ciascun elemento del vettore che rappresenta i valori dei pixel o la caratteristica/descrittore del pixel. In un sistema di raccomandazione musicale, ogni vettore rappresenta una canzone, con ciascun elemento del vettore che rappresenta una caratteristica della canzone, come il ritmo, il genere, il testo, ecc.
I database vettoriali sono ottimizzati per l'archiviazione efficiente e il recupero di vettori ad alta dimensione, spesso utilizzando strutture dati e tecniche di indicizzazione specializzate come Hierarchical Navigable Small World (HNSW) per la ricerca di vicini approssimativi e la Product Quantization. Questi database possono consentire agli utenti di trovare i vettori più vicini a un dato vettore di query secondo una certa metrica di distanza, consentendo una rapida ricerca di similarità e semantica. Le metriche di distanza più comunemente utilizzate includono la distanza euclidea, la similarità coseno e il prodotto scalare, tutte pienamente supportate in Qdrant.
Ecco una breve introduzione a questi tre algoritmi di similarità vettoriale:
- Similarità Coseno - La similarità coseno è una misura di similarità tra due elementi. Può essere vista come una regola usata per misurare la distanza tra due punti; tuttavia, anziché misurare la distanza, misura la similarità tra due elementi. È comunemente utilizzata per confrontare la similarità tra due documenti o frasi nel testo. La gamma di output della similarità coseno va da 0 a 1, dove 0 indica completa dissimilarità e 1 indica completa similarità. È un modo semplice ed efficace per confrontare due elementi!
- Prodotto Scalare - La similarità per prodotto scalare è un'altra misura di similarità tra due elementi, simile alla similarità coseno. Nel trattare con i numeri, è spesso utilizzata nell'apprendimento automatico e nella scienza dei dati. La similarità per prodotto scalare viene calcolata moltiplicando i valori in due insiemi di numeri e poi sommando questi prodotti. Una somma più alta indica una maggiore similarità tra i due insiemi di numeri. È come una scala che misura il grado di corrispondenza tra due insiemi di numeri.
- Distanza Euclidea - La distanza euclidea è un modo per misurare la distanza tra due punti nello spazio, simile a come misuriamo la distanza tra due luoghi su una mappa. Viene calcolata trovando la radice quadrata della somma dei quadrati delle differenze tra le coordinate dei due punti. Questo metodo di misurazione della distanza è comunemente utilizzato nell'apprendimento automatico per valutare la similarità o dissimilarità di due punti dati, in altre parole, per capire quanto siano lontani.
Ora che sappiamo cos'è un database vettoriale e come si differenzia strutturalmente dagli altri database, comprendiamo perché sia importante.
Perché abbiamo bisogno di un database vettoriale?
I database vettoriali svolgono un ruolo cruciale in varie applicazioni che richiedono ricerche di similarità, come i sistemi di raccomandazione, il recupero di immagini basato sul contenuto e le ricerche personalizzate. Sfruttando efficaci tecniche di indicizzazione e ricerca, i database vettoriali possono recuperare dati non strutturati rappresentati come vettori in modo più rapido e accurato, presentando i risultati più rilevanti alla query dell'utente.
Inoltre, altri vantaggi nell'utilizzo di un database vettoriale includono:
- Archiviazione efficiente e indicizzazione di dati ad alta dimensione.
- Capacità di gestire set di dati su larga scala con miliardi di punti di dati.
- Supporto per analisi e query in tempo reale.
- Capacità di gestire vettori derivati da tipi di dati complessi come immagini, video e testi in linguaggio naturale.
- Miglioramento delle prestazioni delle applicazioni di apprendimento automatico e intelligenza artificiale riducendo la latenza.
- Riduzione dei tempi e dei costi di sviluppo e implementazione rispetto alla costruzione di soluzioni personalizzate.
Si noti che i benefici specifici dell'utilizzo di un database vettoriale possono variare a seconda delle casistiche organizzative e dalle funzionalità del database scelto.
Ora, effettuiamo una valutazione ad alto livello dell'architettura di Qdrant.
Panoramica ad Alto Livello dell'Architettura di Qdrant
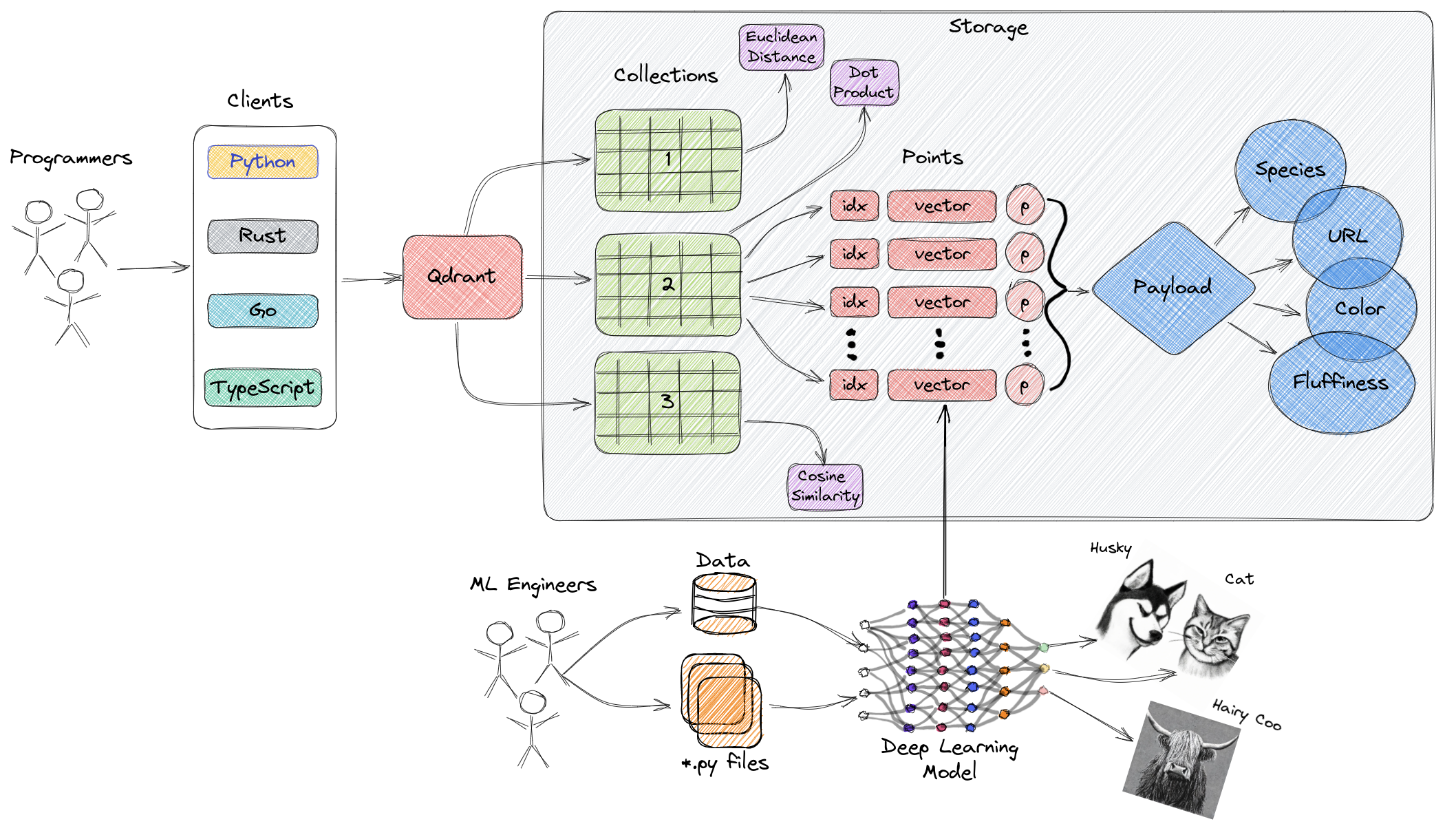
Il diagramma sopra fornisce una panoramica ad alto livello dei principali componenti di Qdrant. Di seguito sono riportati i termini chiave correlati a Qdrant:
- Collezioni: Le collezioni sono un gruppo di punti nominati (vettori con payload, essenzialmente dati vettoriali). In termini più semplici, le collezioni sono simili alle tabelle in MySQL e i punti sono simili alle righe di dati all'interno di quelle tabelle. La ricerca può essere effettuata tra questi punti. Ogni vettore all'interno della stessa collezione deve avere la stessa dimensione e deve essere confrontato utilizzando una singola metrica. I vettori nominati possono essere utilizzati per avere più vettori in un singolo punto, ognuno con le proprie esigenze di dimensione e metrica.
- Metrica: Una misura utilizzata per quantificare la similarità tra vettori, da selezionare durante la creazione di una collezione. La scelta della metrica dipende dal metodo di acquisizione dei vettori, in particolare per le reti neurali utilizzate per codificare nuove query (la metrica è l'algoritmo di similarità che scegliamo).
- Punti: I punti sono le entità core su cui agisce Qdrant, composti da vettori, ID opzionali e payload (simili alle righe di dati in una tabella MySQL).
- ID: Identificatore univoco del vettore.
- Vettore: Rappresentazione ad alta dimensione di dati, come immagini, audio, documenti, video, ecc.
- Payload: Un oggetto JSON che può essere aggiunto al vettore come dati aggiuntivi (utilizzato principalmente per memorizzare proprietà aziendali associate al vettore).
- Archiviazione: Qdrant può utilizzare due opzioni di archiviazione—archiviazione in memoria (tutti i vettori memorizzati in memoria, garantendo la massima velocità, in quanto l'accesso al disco viene utilizzato solo per la persistenza) e Memmap (creazione di uno spazio di indirizzamento virtuale associato a file su disco).
- Clienti: È possibile connettersi a Qdrant utilizzando gli SDK dei linguaggi di programmazione o interagire direttamente con Qdrant utilizzando la sua API REST.