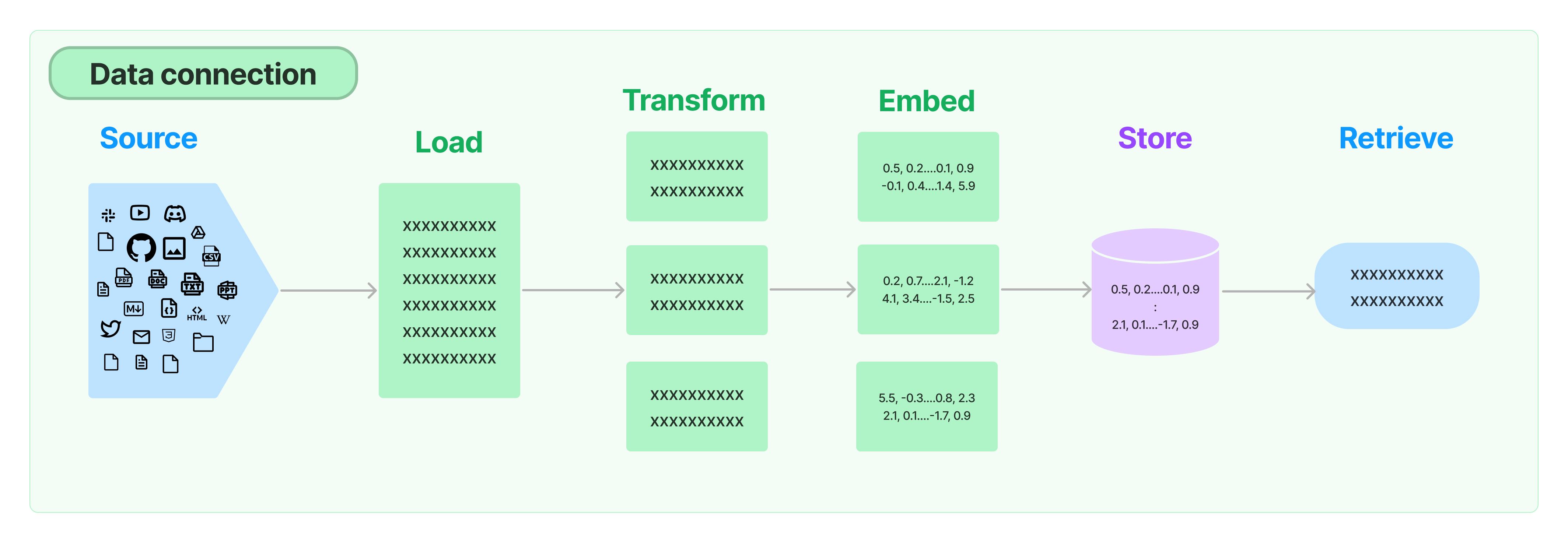
Anche se il Language Model (LM) addestrato conosce molte informazioni, non sa ancora nulla sui dati privati dell'azienda e sui nuovi dati. Molte applicazioni LM devono interrogare i dati privati dell'azienda, quindi concatenare i dati privati come informazioni di background nel prompt e alimentarli al grande modello per rispondere alle domande basate sulle informazioni di background. LangChain fornisce componenti di framework per caricare, trasformare, memorizzare e interrogare i dati.
I componenti di LangChain per gestire i dati privati includono:
- Caricatore di documenti: supporta il caricamento di dati documentali da diverse fonti.
- Convertitore di documenti: suddivide i documenti, converte i documenti in formato domanda e risposta e rimuove i documenti ridondanti.
- Modello di embedding del testo: converte il testo non strutturato in vettori di caratteristiche per supportare la ricerca di similarità semantica, come ad esempio interrogare contenuti simili alla domanda.
- Archiviazione vettoriale: memorizza e ricerca dati vettoriali.
- Retriever: classe di utilità incapsulata di LangChain per interrogare comodamente i tuoi dati.