
پایگاه داده بردار یک روش نسبتاً جدید برای ارتباط با نمایشهای داده انتزاعی است که از مدلهای یادگیری ماشین مانند ساختارهای یادگیری عمیق برمیآید. این نمایشها به طور رایج به عنوان بردارها یا بردارهای جاسازی شناخته میشوند، و نسخههای فشرده شده ای از دادههای استفاده شده برای آموزش مدلهای یادگیری ماشین برای انجام وظایفی مانند تحلیل احساسات، تشخیص گفتار و تشخیص اشیا هستند.
این پایگاه دادههای جدید در بسیاری از برنامهها عملکرد برجستهای از خود نشان دادهاند، مانند جستجوی معنایی و سیستمهای پیشنهادی.
چیست Qdrant؟
Qdrant یک پایگاه داده بردار منبع باز است که برای برنامههای هوش مصنوعی نسل بعدی طراحی شده است. این پایگاه داده ابری است و رابطهای RESTful و gRPC برای مدیریت جاسازیها ارائه میدهد. Qdrant ویژگیهای قدرتمندی دارد و پشتیبانی از جستجوی تصویر، صدا و ویدئو، و همچنین ادغام با موتورهای هوش مصنوعی را ارائه میدهد.
چیست یک پایگاه داده بردار؟
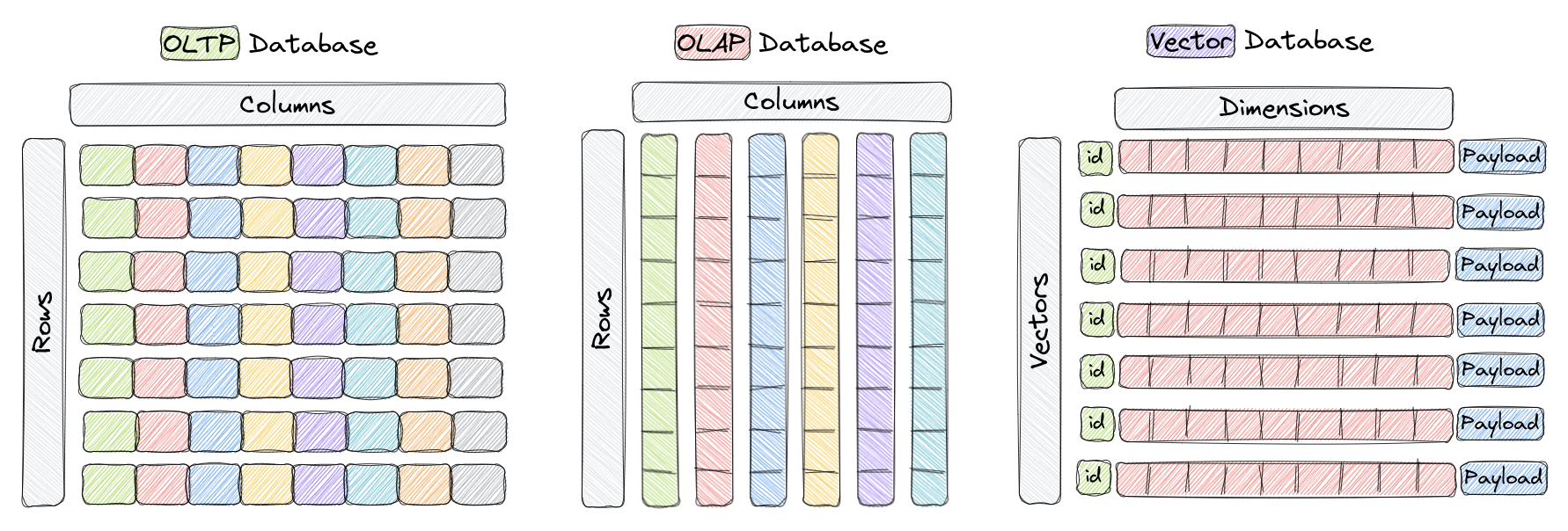
یک پایگاه داده بردار نوعی از پایگاه داده است که بهطور خاص برای ذخیره و پرس و جوی بردارهای بلند بعد طراحی شده است. در پایگاههای داده OLTP و OLAP سنتی (همانطور که در شکل فوق نشان داده شده است)، دادهها در ردیفها و ستونها (مشهور به جداول) سازماندهی میشوند و پرس و جوها بر اساس مقادیر این ستونها است. با این حال، در برخی برنامههایی مانند شناخت تصویر، پردازش زبان طبیعی و سیستمهای پیشنهادی، اغلب داده به صورت بردارها در فضای بلند بعد نمایش داده میشود. این بردارها به همراه یک شناسه و بار، عناصر ذخیرهشده در پایگاه دادههای برداری مانند Qdrant را تشکیل میدهند.
در این زمینه، یک بردار نمایانگر ریاضی یک شی یا نقطه داده است، جایی که هر عنصر از بردار متناظر با یک ویژگی یا صفت از شی است. به عنوان مثال، در یک سیستم شناسایی تصویر، یک بردار میتواند یک تصویر را نمایش دهد، بهطوری که هر عنصر فرضی از بردار متناظر با مقادیر پیکسل یا ویژگی/توصیف پیکسل باشد. در یک سیستم پیشنهاد موسیقی، هر بردار یک آهنگ را نمایش میدهد و هر عنصر از بردار یک ویژگی از آهنگ مانند ریتم، سبک، متن و غیره است.
پایگاههای داده بردار برای ذخیره و پرس و جوی کارآمد بردارهای بلندبعد بهینهسازی شدهاند و اغلب از ساختارهای داده و تکنیکهای نمایهگذاری ویژه مانند Hierarchical Navigable Small World (HNSW) برای جستجوی نزدیکترین همسایه تقریبی و Quantization محصول استفاده میکنند. این پایگاههای داده به کاربران اجازه میدهند تا بردارهای نزدیکترین به بردار پرسوجوی داده شده را با توجه به متریک فاصله خاص پیدا کنند و امکان جستجوی شباهت سریع و معنایی را فراهم میسازند. از متریکهای فاصله معمولاً به فاصله یوکلیدین، تشابه کیسه، و ضرب داخلی حمایت کامل، همگی به طور کامل در Qdrant حمایت میشود.
در ادامه، یک معرفی مختصر به این سه الگوریتم شباهت بردار ارائه شده است:
- تشابه کیسه - تشابه کیسه یک اندازهگیری از شباهت بین دو مورد است. میتوان آن را به عنوان یک ابزار اندازهگیری برای اندازهگیری فاصله بین دو نقطه دانست؛ با این حال، به جای اندازهگیری فاصله، شباهت بین دو مورد را اندازهگیری میکند. این به طور رایج در مقایسه شباهت بین دو سند یا دو جمله متنی استفاده میشود. محدوده خروجی تشابه کیسه از 0 تا 1 است، که 0 نشان دهنده عدم شباهت کامل و 1 نشان دهنده شباهت کامل است. این روش ساده و مؤثری برای مقایسه دو مورد است!
- ضرب داخلی - تشابه ضرب داخلی یک اندازهگیری دیگر از شباهت بین دو مورد است، مشابه تشابه کیسه. در برخورد با اعداد معمولاً در یادگیری ماشین و علم داده استفاده میشود. تشابه ضرب داخلی را با ضرب مقادیر در دو مجموعه اعداد محاسبه میکند و سپس این حاصلات را با یکدیگر جمع میکند. یک مجموعه بیشتر نشانگر یک شباهت بیشتر بین دو مجموعه اعداد است. این مانند یک ترازو است که درجه مطابقت بین دو مجموعه اعداد را اندازهگیری میکند.
- فاصله یوکلیدین - فاصله یوکلیدین یک روش برای اندازهگیری فاصله بین دو نقطه در فضا است، مشابه این که چگونه ما فاصله بین دو مکان روی یک نقشه را اندازهگیری میکنیم. با محاسبه ریشه مربعی از مجموع مربعهای اختلاف مختصات دو نقطه، این فاصله محاسبه میشود. این روش اندازهگیری فاصله به طور معمول در یادگیری ماشین برای ارزیابی شباهت یا عدم شباهت دو نقطه داده استفاده میشود، به عبارت دیگر، برای درک اینکه چقدر دور هستند.
اکنون که میدانیم پایگاههای داده بردار چیست و چگونه از نظر ساختاری از دیگر پایگاههای داده متفاوتاند، بیایید بفهمیم چرا اهمیت دارند.
چرا به یک پایگاه داده بردار نیاز داریم؟
پایگاه دادههای برداری نقش حیاتی در برنامههای مختلفی ایفا میکنند که نیاز به جستجوی شباهت دارند، مانند سیستمهای پیشنهاد، بازیابی تصاویر مبتنی بر محتوا و جستجوی شخصیسازی شده. با بهرهمندی از تکنیکهای قدرتمند نمایهسازی و جستجو، پایگاه دادههای برداری میتوانند اطلاعات بدست نیاورده نا ساختار را که به صورت بردارهای مشخص شده اند، به سرعت و به طور دقیقتر بازیابی کرده و نتایج مربوطه را برای جستجوی کاربر ارائه دهند.
علاوه بر این، مزایای دیگر استفاده از پایگاه داده برداری شامل موارد زیر است:
- ذخیرهسازی و نمایهسازی کارآمد دادههای بعد بالا.
- توانایی مدیریت مجموعههای داده بزرگ با میلیاردها نقطه داده.
- پشتیبانی از تحلیل و پرسوجو به صورت زمانواقعی.
- توانایی مدیریت بردارها مشتقشده از انواع داده پیچیده مانند تصاویر، ویدیوها و متون زبانی طبیعی.
- بهبود عملکرد برنامههای یادگیری ماشین و هوش مصنوعی همراه با کاهش تاخیر.
- کاهش زمان و هزینههای توسعه و استقرار نسبت به ساخت راهحلهای سفارشی.
لطفا توجه داشته باشید که مزایای خاص استفاده از پایگاه داده برداری ممکن است بسته به موارد استفاده سازمان و قابلیتهای پایگاه داده انتخابی متفاوت باشد.
حالا بیایید یک ارزیابی سطح بالای از معماری Qdrant انجام دهیم.
مرور بالا از معماری Qdrant
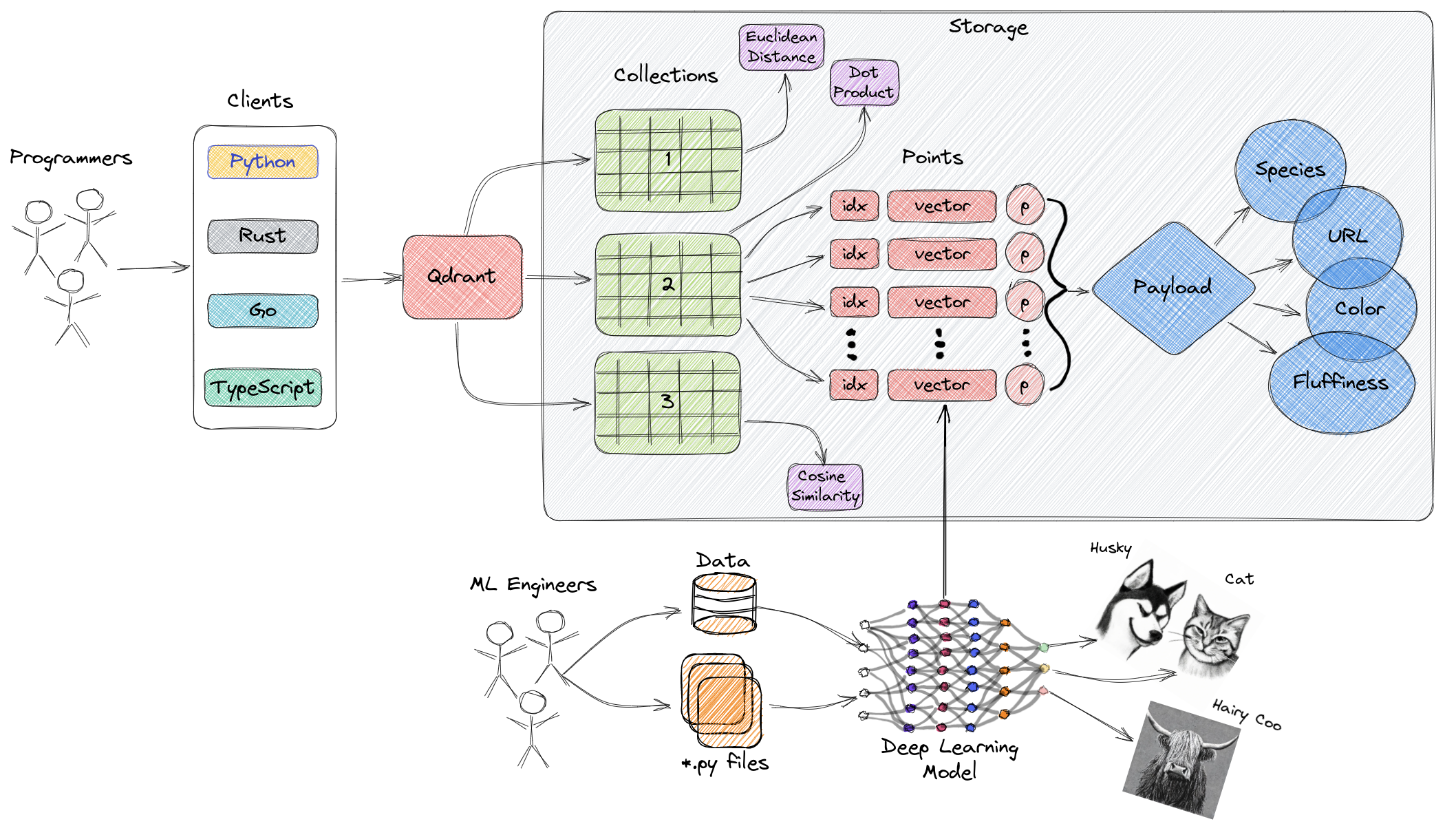
نمودار فوق یک مرور از سطح بالایی از اجزای اصلی Qdrant ارائه میدهد. موارد کلیدی مرتبط با Qdrant به شرح زیر است:
- مجموعهها: مجموعهها گروهی از نقاط نامگذاری شده (بردارها با بارمخصوص - به طور اصولی دادههای برداری) هستند. به عبارت ساده، مجموعهها مشابه جداول در MySQL هستند و نقاط مشابه ردهای داده داخل این جداول هستند. جستجوی میان این نقاط انجام میشود. هر بردار در یک مجموعه باید ابعاد یکسانی داشته و با استفاده از یک معیار تکی مقایسه شود. بردارهای نامگذاری شده میتوانند برای داشتن چند بردار در یک نقطه استفاده شوند که هر کدام ابعاد و نیازمندیهای معیار خود را داشته باشد.
- معیار: اندازهگیری استفاده شده برای اندازهگیری شباهت بین بردارها که باید هنگام ایجاد یک مجموعه انتخاب شود. انتخاب معیار بستگی به روش بدست آمدن بردار، به ویژه برای شبکههای عصبی استفاده شده برای رمزگذاری پرسوجوهای جدید (معیار الگوریتم شباهتی است که انتخاب میکنیم).
- نقاط: نقاط موجودیتهای اساسی هستند که توسط Qdrant عملیاتی میشوند و شامل بردارها، شناسههای اختیاری و دستمزد (شباهت به ردهای داده در یک جدول MySQL).
- شناسه: شناسه یکتا بردار.
- بردار: نمایش بعد بالای داده، مانند تصاویر، صدا، سند، ویدیوها و غیره.
- دستمزد: یک شی JSON که میتواند به بردار به عنوان داده اضافی اضافه شود (اصولاً برای ذخیره ویژگیهای تجاری مرتبط با بردار استفاده میشود).
- ذخیرهسازی: Qdrant میتواند از دو گزینه ذخیرهسازی استفاده کند - ذخیرهسازی در حافظه (تمام بردارها در حافظه ذخیره میشوند و سرعت بالاتری را ارائه میدهد، زیرا دسترسی دیسک فقط برای پایداری استفاده میشود) و ذخیرهسازی Memmap (ایجاد یک فضای آدرس مجازی مرتبط با فایلها در دیسک).
- مشتریان: شما میتوانید از طریق SDKهای زبان برنامهنویسی به Qdrant متصل شوید یا مستقیماً از طریق رابط برنامهنویسی REST آن با Qdrant تعامل داشته باشید.